거대한 시스템이 있으면,
그 시스템에 대해 모든 부분을 다 파악할 수 있다면 참 좋겠죠.
하지만 일반적으로는 힘듭니다.
따라서, 우리는 특정 시스템에서, 특정한 attribute들만 뽑아서
시스템을 modeling하여 표현합니다.
Model : representation of something.
It captures not all attributes of a specific thing,
but only those that are relevant for a specific purpose.
모델은
-
Expressive해야 합니다.
실제 세상을 잘 표현하고 있어야 하죠. -
Tractable해야 합니다.
결과를 계산할 때 너무 오랜 시간이 걸려선 안 됩니다.
특정 시간 안에 계산결과가 나와야 하죠.
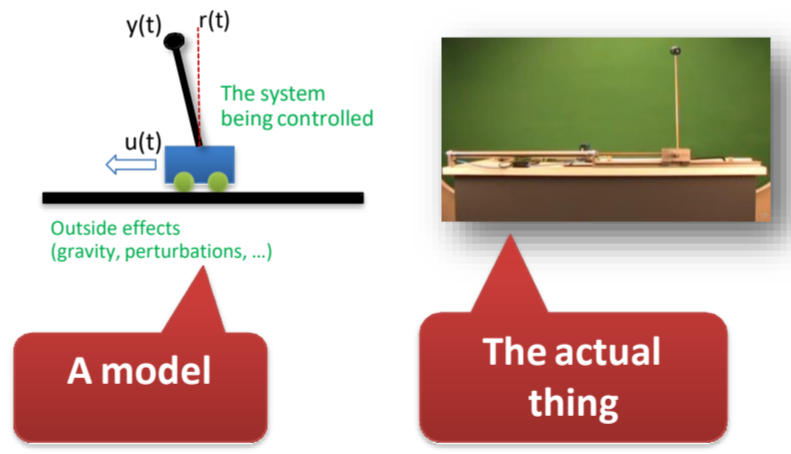
뭔가 복잡해 보이는 실제 세상의 시스템을,
모델링을 통해 간단하게 표현합니다.
Why do we need models?
앞서 말했듯, 실제 시스템을 완벽하게 구현하긴 힘듭니다.
시스템을 잘 모방한 모델을 가지고,
deadline을 지키는지 Time analysis를 하고 나면,
System이 safe한지 아닌지 분석이 가능하게 되죠.
즉, System을 analyze하기 위해 모델은 필수입니다.
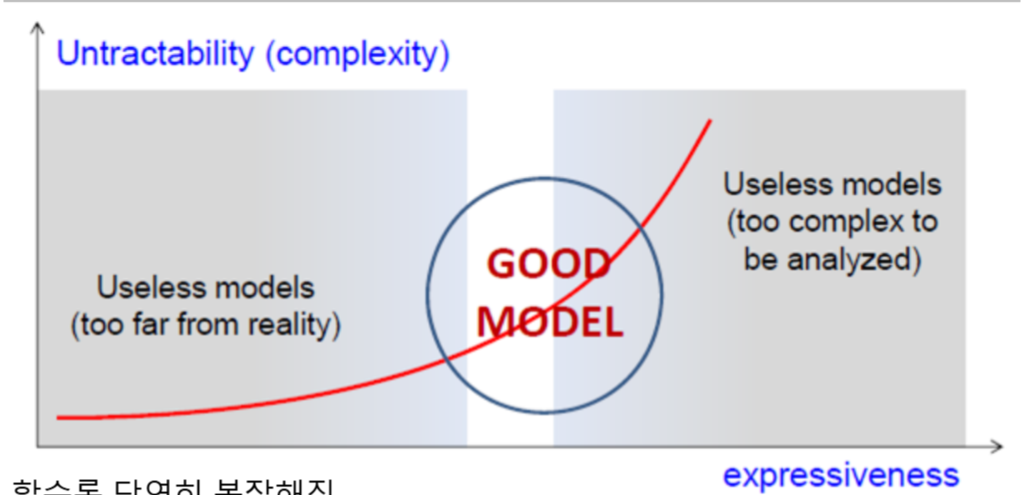
당연히, 앞선 2개의 속성을 다 가진 모델이 좋은 모델이겠죠.
Expressiveness가 부족한 모델은 현실성이 떨어져서 안 좋은 모델입니다.
공의 포물선 운동을 계산하는 모델이 중력가속도를 고려하지 않는다면,
좋은 모델이 아니겠죠.
너무 복잡한 모델 역시 안 좋은 모델입니다.
어쨌든 모델을 분석하여 timeliness를 보장하는지 분석하는건데,
매개변수가 40개씩 들어가 분석에만 3일이 걸린다면,
효율적이지 못하겠죠.
물론, 당연히 현실을 잘 반영하려 노력할 수록 untractability가 높아집니다.
공의 포물선 운동을 고려할 때,
공의 탄성, 기압, 공기저항, 던져질 때의 마찰계수 등을 다 고려해야
실제 현실을 잘 모방하겠지만,
그만큼 오래걸릴테니까요.
Then how do we build a model?
-
현실을 단순화하는 assumption은 거의 필수입니다.
앞선 공의 포물선운동 예시에서,
가령 '기압은 대기압으로 상정한다' 정도의 가정을 하는거죠. -
모델의 특성을 나타내는 variable을 정의해야 합니다.
-
모델을 평가할 때 쓰는 evaluation metric 역시 정의해야 하죠.
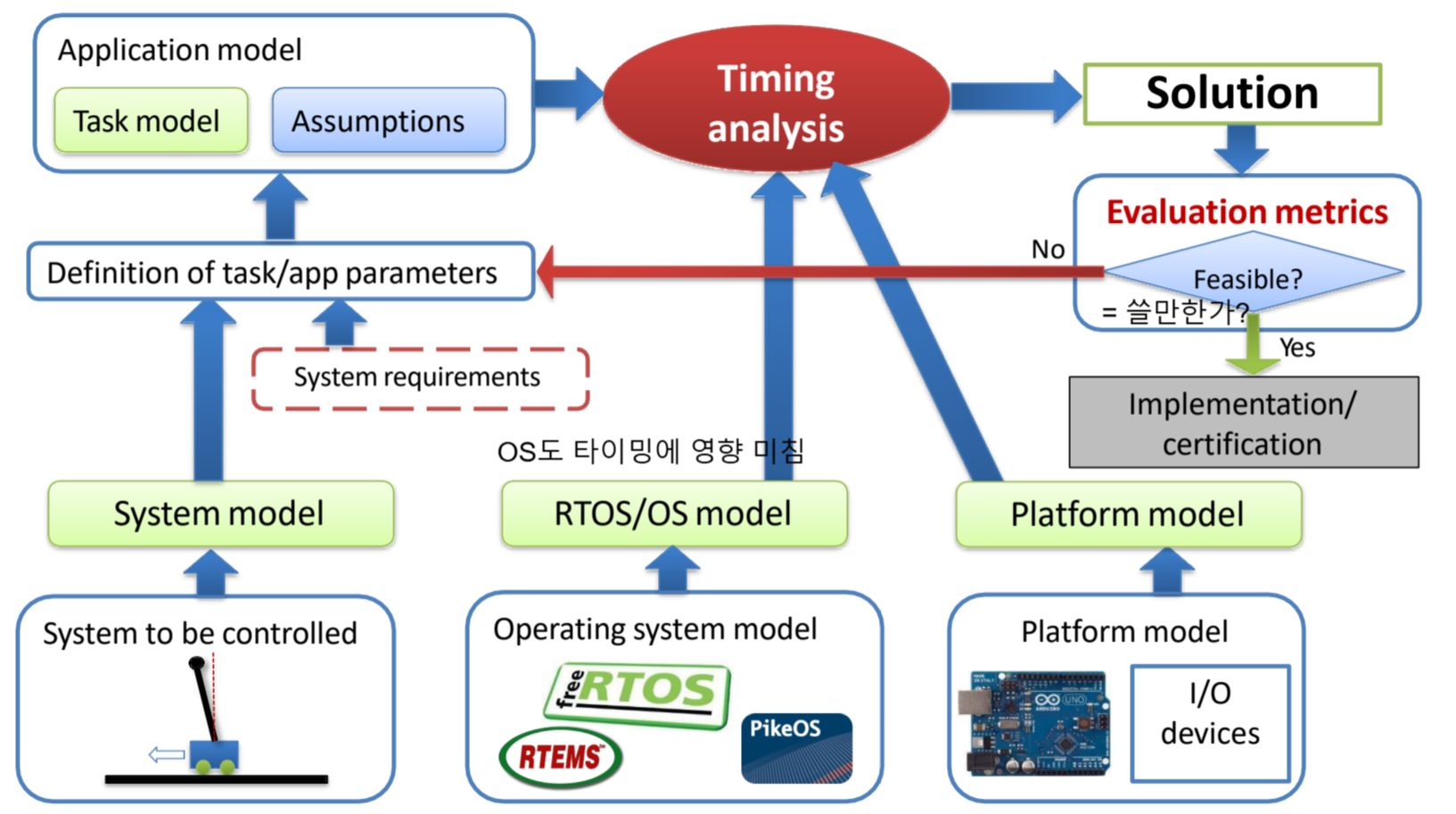
이렇게 다음과 같이,
특정 시스템에 대해
Application model, Platform model, OS model 등을 전부 고려하여,
Timing Analysis를 내고,
따로 마련했던 Evaluation metric에 따라서
Feasible하다면 => 사용
Feasible하지 않다면 => 바꿀 수 있는 parameter의 조정
이 과정을 거칩니다.
Task
아까부터 자꾸 Task Task하는데,
그래서 Task가 뭔데요?
Task : Sequence of instructions continuously executed.
Processor에 의해서, instruction이 끝날 때 까지,
타 activity가 존재하지 않을 때
연속적으로 실행되는 instruction의 묶음을 Task라고 부릅니다.
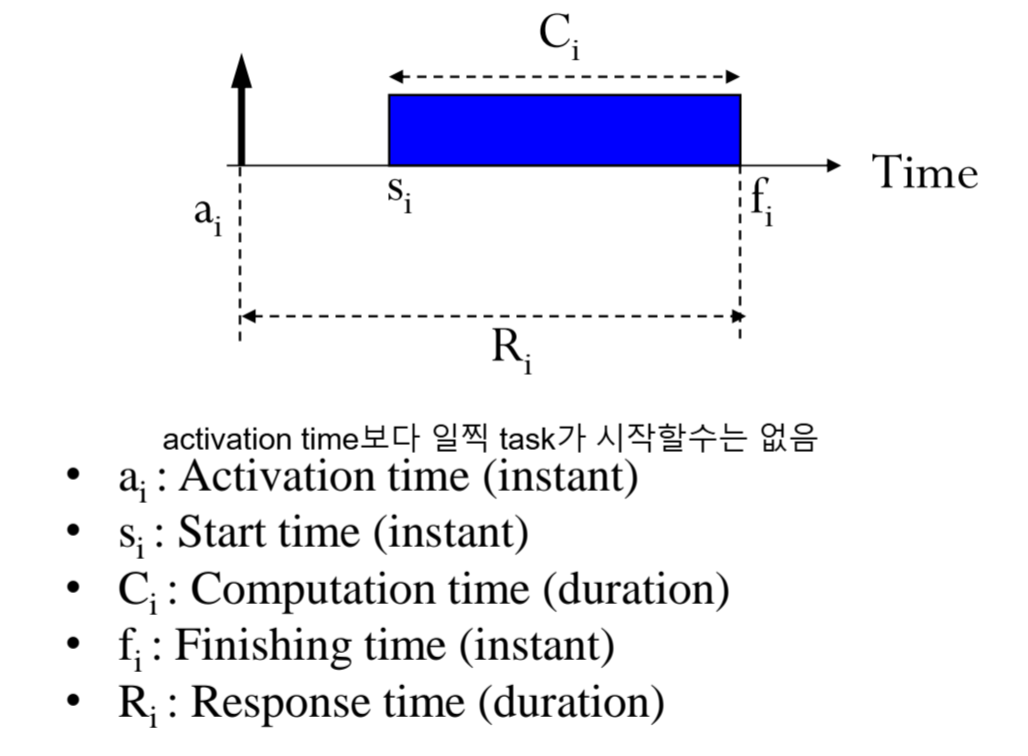
Task를 가지고 많이 이용하는 notation들입니다.
-
a_i : Activation time
Task가 실제로 도착하는 시각입니다.
복잡하지만, activation time때 뿅 하고 task가 생긴다고 이해합시다. -
s_i : Start time
Task가 실행되기 시작하는 시각입니다. -
C_i : Computation time
Task가 실행되기 시작한 시점부터 끝날 때 까지의 duration입니다.
만약 task가 모종의 이유로 늦게 끝난다면, computation time은 길어지겠죠. -
f_i : finish time
Task가 끝나는 시각입니다. -
R_i : Response time
Task가 뿅 생긴 이후로부터 끝날 때 까지 걸린 시간입니다.
사실상 제일 중요하죠.
Ready Queue
하나의 프로세서는 한번에 하나의 작업만 할 수 있습니다.
Quad-core라면 프로세서가 4개니까 한번에 4개의 작업을 할 수 있겠죠.
active task인데, 현재 실행중이지 않은 task를 ready 상태로 분류합니다.
그리고 그 ready task들은 ready queue에 들어있고,
Scheduler에 의해 관리됩니다.
Scheduler가 ready queue에서 자신만의 조건에 의거하여 task를 정해서
processor에게 가져다 주면,
processor는 해당 task를 실행하죠.
Preemption
현재 processor가 실행중인 task가 존재하는데,
더 중요한 task를 스케줄러가 보낸다면,
interrupt가 가능합니다.
그런 작업을 Preemption이라고 칭합니다.
Preemption을 통해서 concurrency가 높아지며,
더 중요한 task의 response time이 좋아집니다.
물론, 아주 중요한 operation이 preemption에 의해 빠져버리면 곤란하니,
일시적으로 해제할 수도 있죠.
Schedule
과연 Schedule은 뭔가요?
Schedule : a particular assignment of tasks to the processor, that determines the task execution sequences.
Processor에게 갈 Task의 실행순서를 결정하는 지시사항입니다.
좀 더 formal한 정의도 존재합니다.
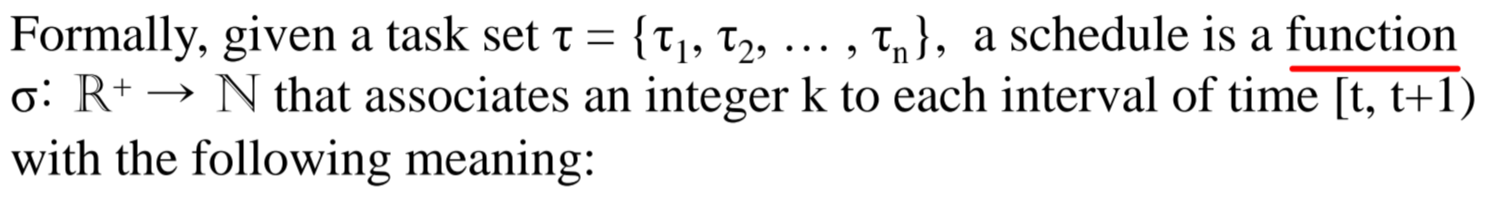
Task 집합 내에서, 시간 t를 task k에게 매핑하는 함수라고 볼 수 있습니다.
[t, t+1)에서 k=0이라면, 그 시간대에 processor가 놀고 있는거구요, (idle)
[t, t+1)에서 k=4라면, 그 시간대에 processor는 task_4를 실행중인 겁니다.
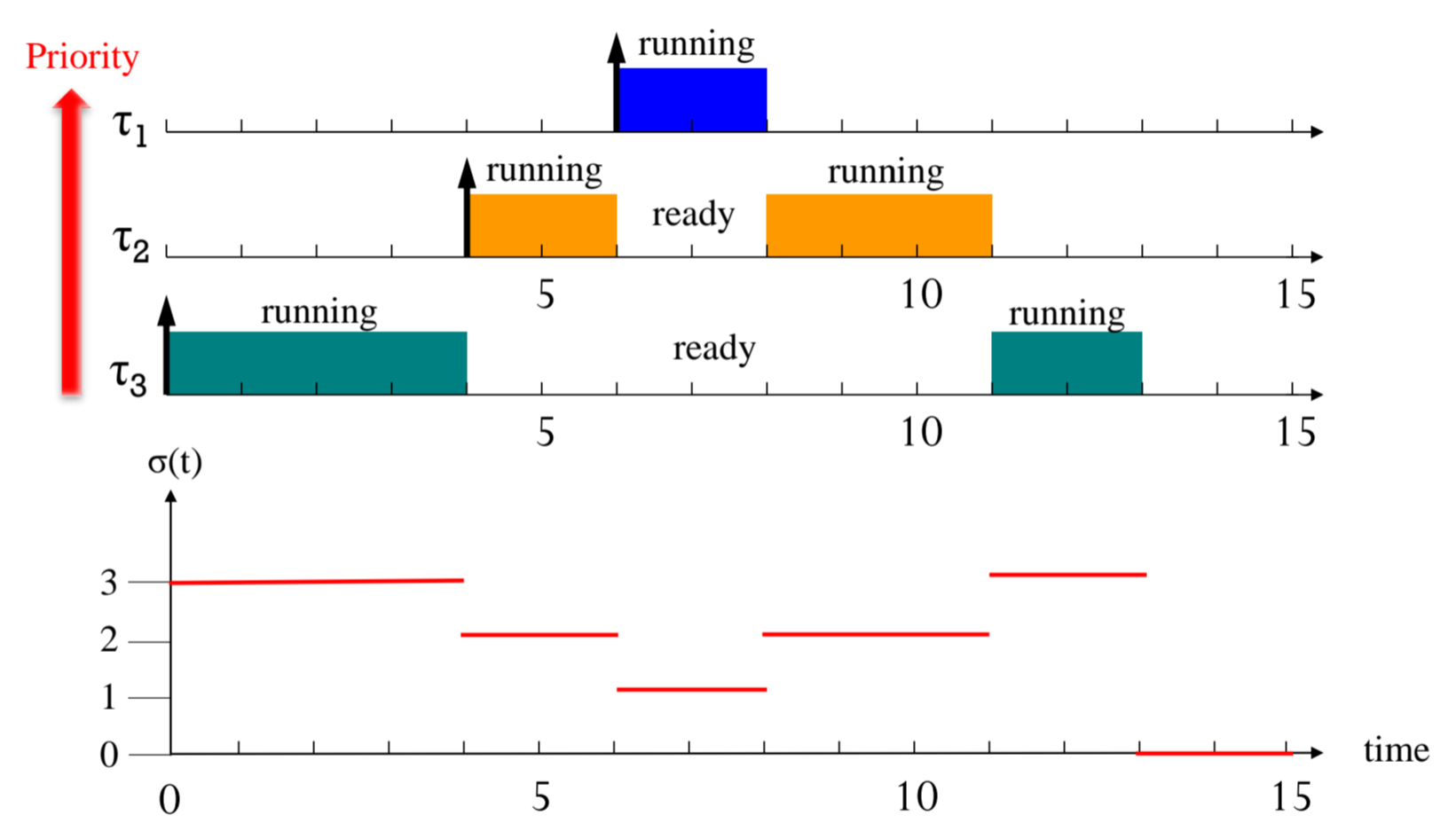
마땅히 schedule이 어려운 개념은 또 아닙니다.
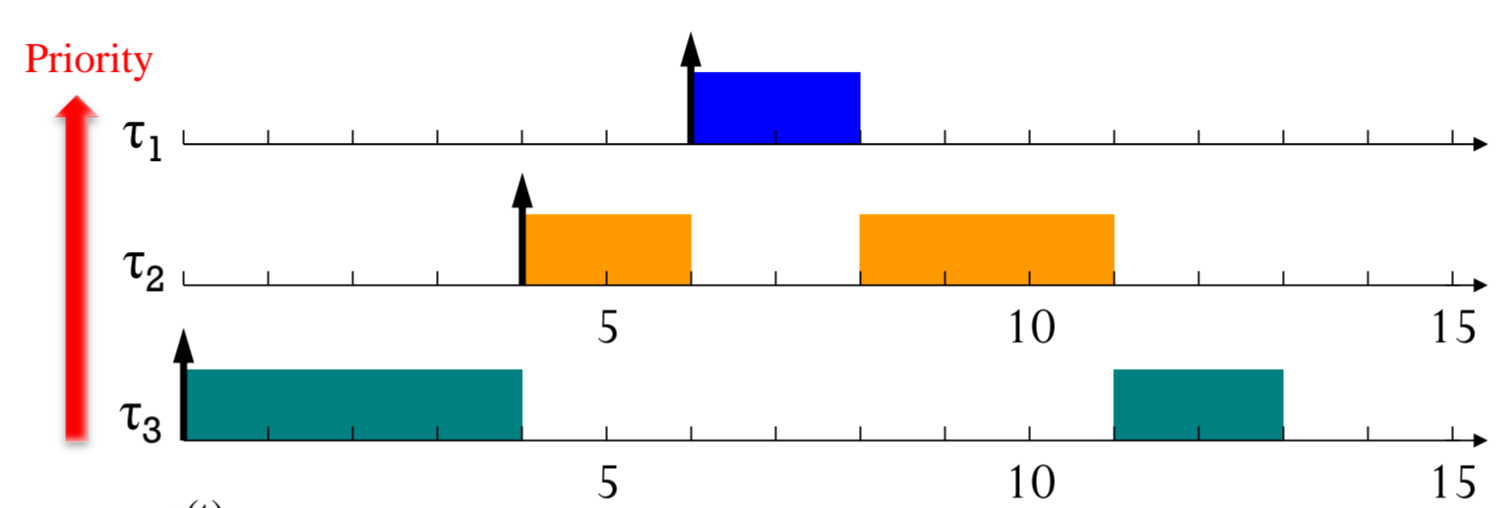
다음과 같은 time table이 있을 때,
Priority가 더 높은 애가 들어오면 이전에 Priority가 낮은 친구는 대체될 수밖에 없죠.
대표적인 Preemptive Scheduling의 예시네요.
[t = 4], [t = 6]에서 Preemption이 일어났고,
[t = 8], [t = 11]에서 Context Switch가 일어났다고 볼 수 있습니다.
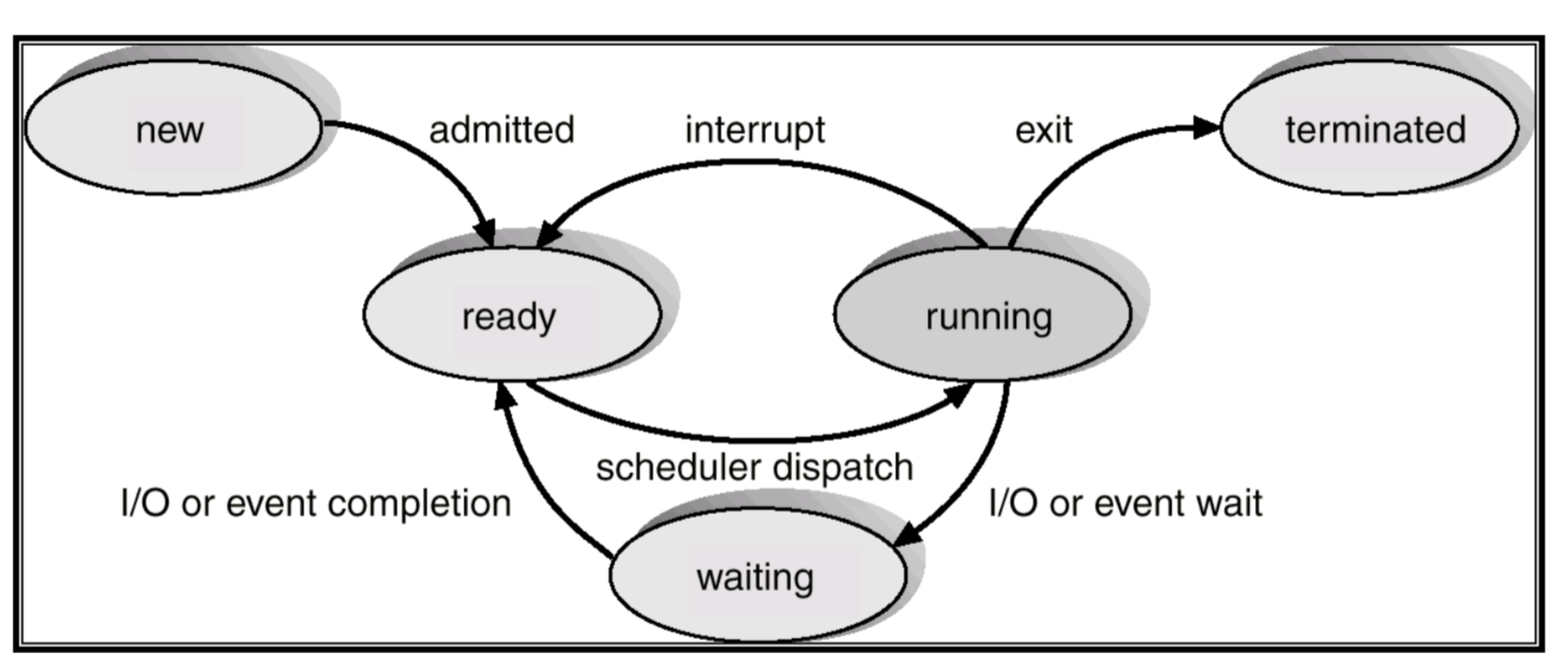
이 diagram은 Task State를 나타냅니다.
새 task가 허락되면 Ready로 이동하고,
scheduler가 dispatch (ready queue에서 꺼내는걸 dispatch라 합니다.)하면 running이 되며,
다 끝나면 terminated,
중간에 interruption이 들어오면 다시 ready로 이동하고,
그 외에 I/O 등 외력 발생 시 waiting으로 이동합니다.
그럼 다음과 같겠죠.
How do we model a real-time task?
deadline이 존재하는 realtime task를 모델링하고 싶습니다.
위쪽의 다이어그램은 보면 deadline이 마땅히 명시되어 있지 않죠.
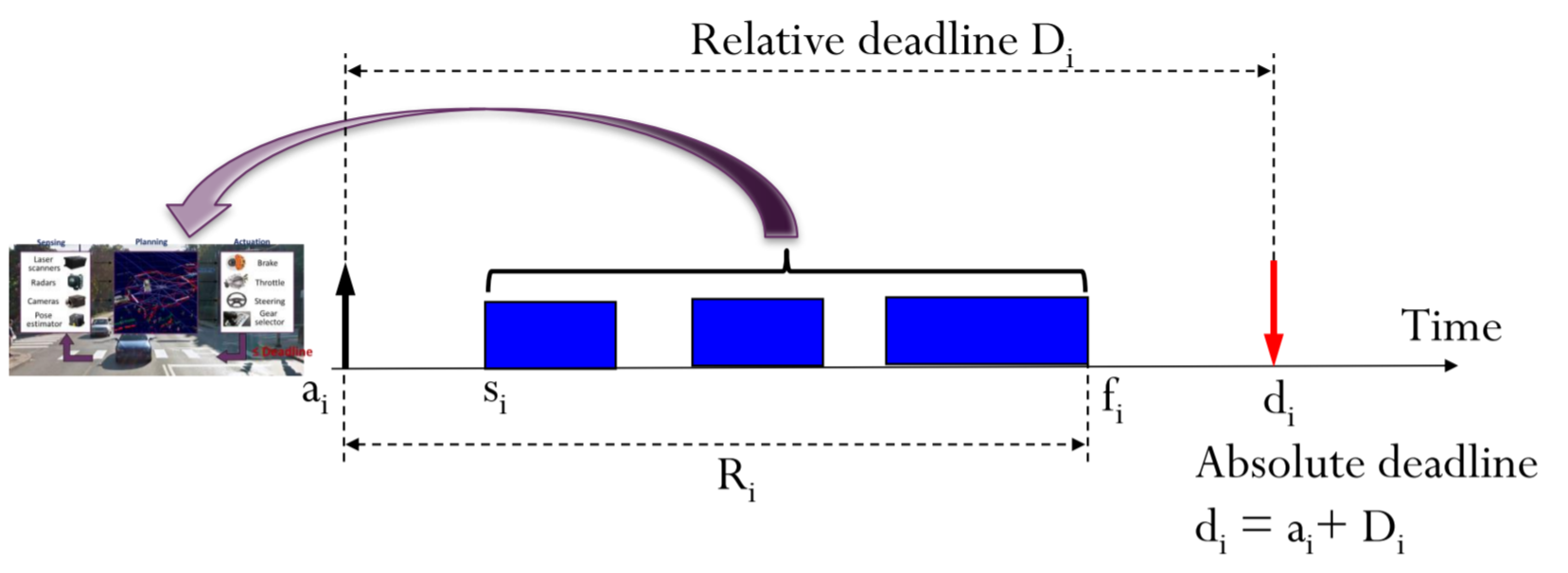
real-time task는 deadline이라 불리는,
task의 Response time이 지켜야 하는 timing constraint를 포함한 task입니다.
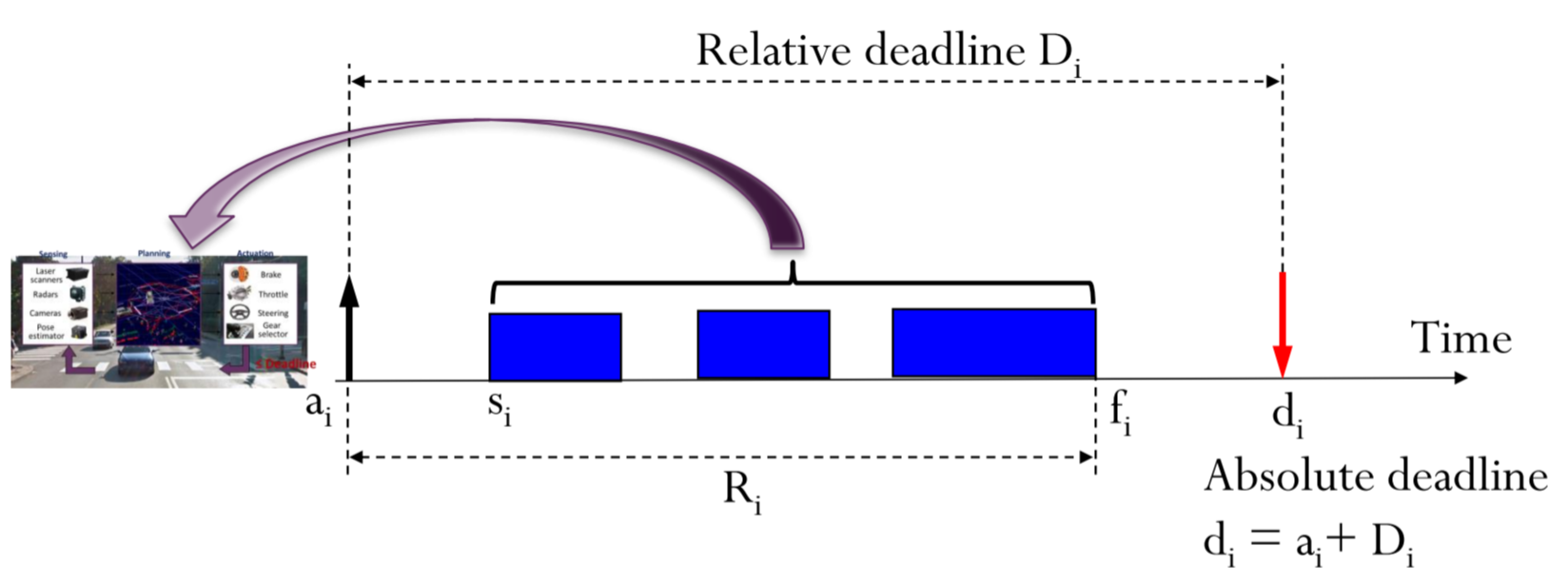
이 경우는, 이 task i는 D_i의 데드라인을 가지는 경우입니다.
D_i가 5라면, task는 activate되고 5 time unit 안에 finish되어야 하죠.
그리고, task가 deadline 전에 끝남이 보장되는 경우, feasible하다고 부릅니다.
Jobs
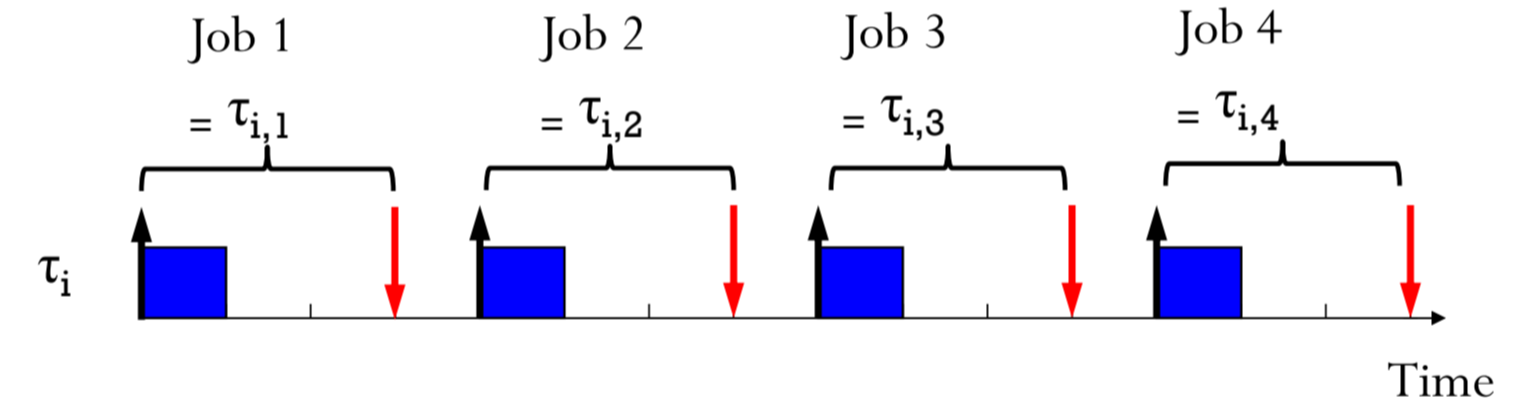
똑같은 task의 반복인데, input data가 다를 경우, Job이라 부릅니다.
각 Job은 다르죠.
print(a+b)에서, (a,b) : (1,1), (2,2), (-1,-1), (0,100)은 각각 다른 job이겠네요.
Periodic, Aperiodic, Sporadic task
Periodic task
우리는 Task를 2개로 나눌 수 있는데,
Periodic Task와 Aperiodic task로 나눌 수 있습니다.
periodic task는 말 그대로, OS에 의해 주기적으로 activate되는 task입니다.
앞서 얘기했던 기차 충돌 방지 sensor 정도가 해당하죠.
Aperiodic task는 Event-driven입니다.
특정 event에 의해서만 발생하는 task입니다.
뭐 pagefault handler 정도가 해당합니다.
다음과 같은 periodic task를 가정합시다.
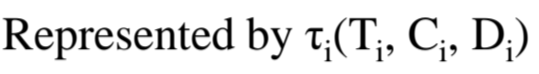
만약 t(5,2)라면, Relative Deadline이 T_i와 같다고 생각하면 됩니다.
t(5,2) = t(5,2,5)
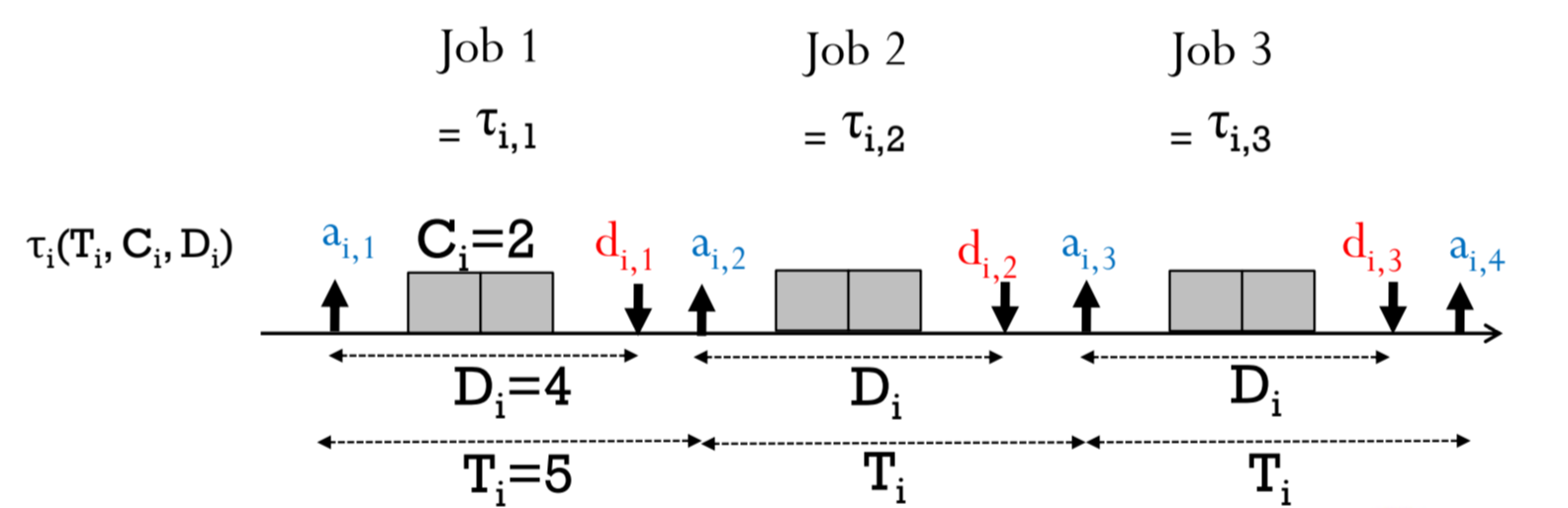
다음과 같은 Job들이 실행 될 때,
-
a1,1 = p1 이라고 가정합시다.
그러면, -
ai,k = p1 + (k-1)T_i가 성립합니다.
당연하죠?
첫번째 activation time 이후, 주기적으로 T_i마다 activate되니까요. -
di,k = a1,k + D_i가 성립합니다.
이 또한 당연하죠? 정의입니다.
Aperiodic task
Task간의 제약이 존재하지 않습니다.
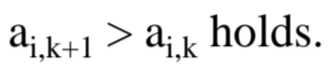
이게 무슨 뜻이냐?
Task간에 정해진 규약, 제약같은게 없다는 뜻입니다.
당연히 k+1번째 job은 k번째 job보단 뒤에 있겠죠.
번째니까요.
그게 끝이라는 뜻입니다.
주기도, 제약도 없습니다.
Sporadic task
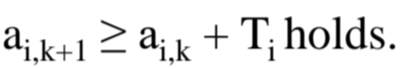
이전 Task가 실행되고, 최소한의 주기만 넘기면 그 이후에 언제든지 스케줄이 가능합니다.
"정확히 주기"만큼 후에 즉시 실행이 되면 periodic이고,
"정확한 주기"만 지나면 언제 activate가 되어도 상관없다면 sporadic이고,
"주기"따위 없다면 Aperiodic이겠네요.
WCET Measurement
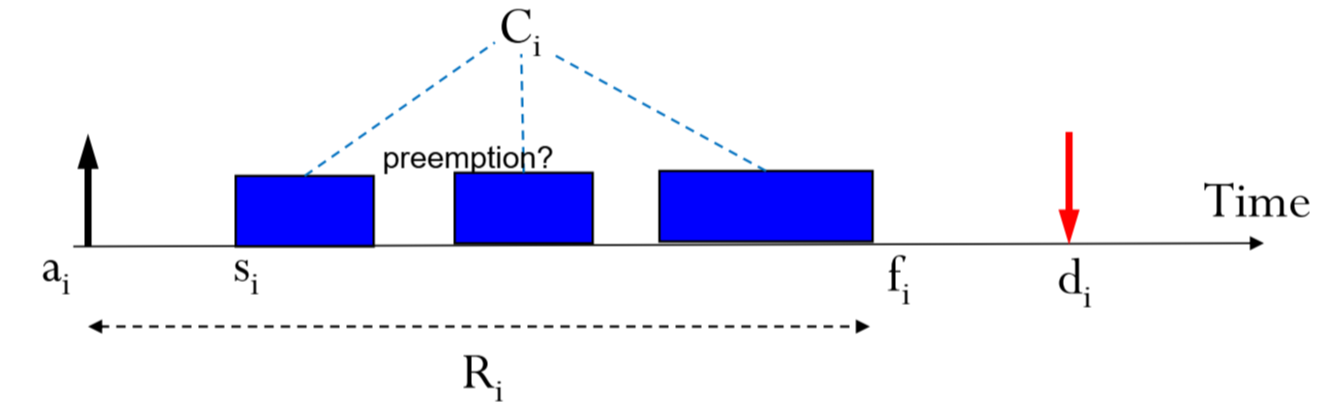
다음과 같은 time graph를 봅시다.
이 task는 뭐 preemption이 일어났건 I/O Interrupt가 일어났건,
모종의 이유로 2번의 중단이 일어났습니다.
그래서 Computation time이 길어졌습니다.
Computation time은 task가 시작한 후부터 끝날때까지의 시간이니까요.
근데, 이 Computation time이 길어진다면 충분히 s_i + C_i가 deadline을 넘길 수도 있습니다.
그래서, Schedulabiliity를 계산하기 위해서,
Computation time을 알아야 합니다.
하지만 우린 최악의 경우를 상정해야 하니, 모든 경우에 대해 Computation time을 계산하기보다는,
Worst-Case Execution Time인 WCET를 계산합니다.
WCET Measurement에는 2가지 방법이 있습니다.
Analysis
for (int i = 0 ; i < 1M ; i++)
{
if (A)
{
}
else (B)
{
}
}다음과 같은 코드에서, analysis 방식은 최악의 경우를 상정하고 시간을 계산합니다.
A branch의 실행시간이 1ms, B branch의 실행시간이 2ms라면
모든 경우 B Branch를 타고, 1백만번 실행됨 이라고 가정하는거죠.
즉 이 경우 2,000,000ms를 얻게 됩니다.
Measurement
단순무식하게 input을 다르게 해서 엄청난 양의 계산을 합니다.
그 후 가장 오래 걸린 시간을 측정하는 방식입니다.
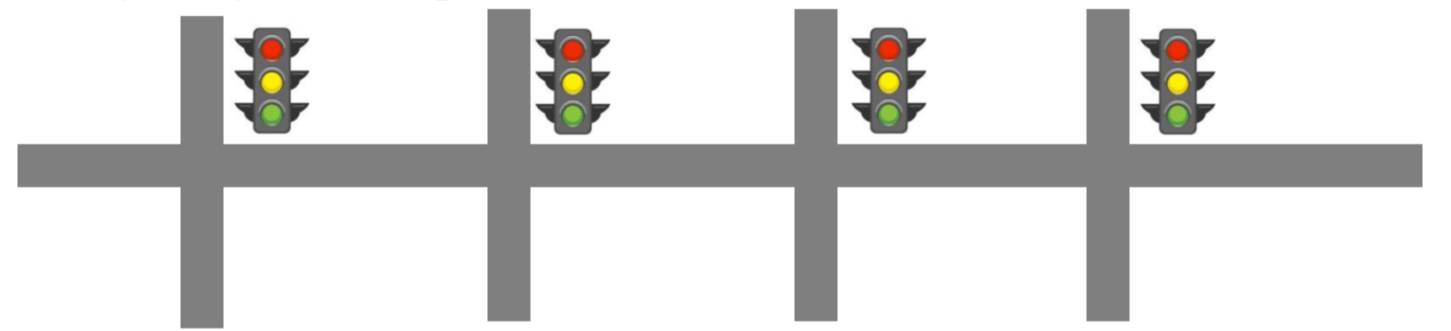
다음과 같은 신호등 모델을 상정합시다.
이 신호등 모델의 WCET를 계산하고자 합니다.
정확한 estimate를 알려면 roadmap, speed limit, traffic lights 등의
인자들은 다 알고 있어야 겠죠?
또한, C_i가 inf가 되는 일을 방지하기 위해, assumption도 필수적입니다.
- Car does not break.
- No accidents / traffic jams.
- We are not stopped at any cost. (e.g. by the police)
- We run at speed limits.
Analysis 방법을 사용해볼까요?
우리가 교차로에 갈 때마다 무조건 빨간 불이면 worst case겠죠?
모델의 simplicity를 위해 자동차의 가속/감속 시간을 없앨 때,
Time_spent_at_road + Time_waiting_at_trafficlight * 4
가 worst case가 되겠네요.
Measurement 방법은요?
이 교차로에서 차를 계속 굴려보는겁니다.
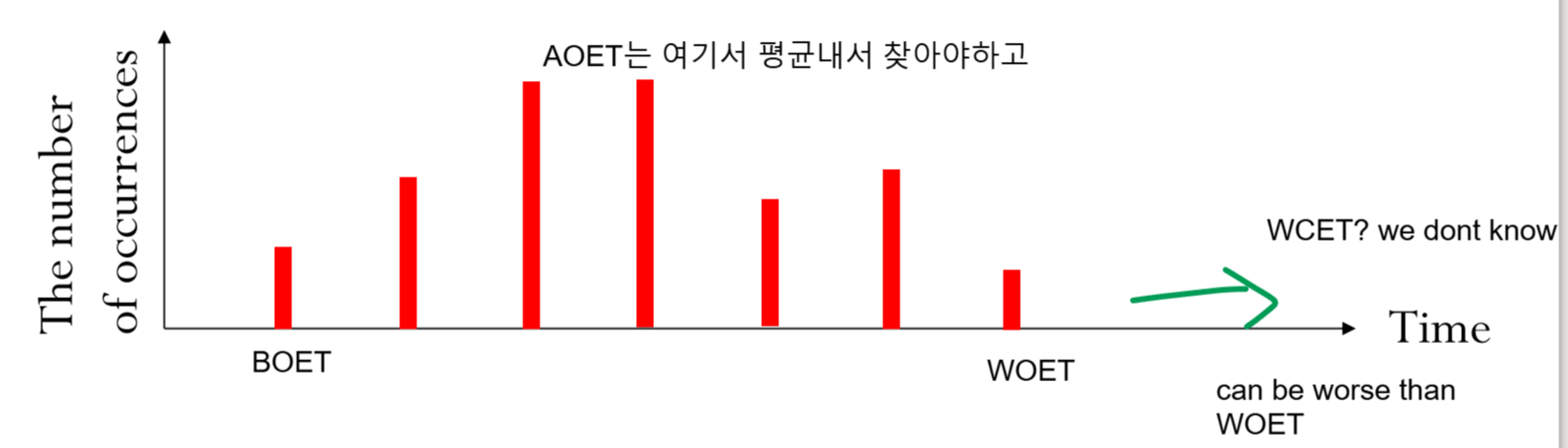
이래서 WOET (Worst Observed Execution Time)을 얻을 수 있고,
어쩔 수 없이 그 값이 WCET이겠거니 하고 추정하는거죠.
실제로 맞을 수도 있지만, 충분히 WOET < WCET일 수도 있습니다.
observed time중 제일 짧게 걸린 값을 BOET (Best Observed Execution Time)이라고 하고,
평균치를 AOET (Average Observed Execution Time)이라고 칭합니다.
정확한 Analysis method를 위해서는,
Task Code도 알아야 하고, CPU Speed도 알아야 합니다.
각 job이 for문을 몇 번 타냐, if문에서 어느 branch로 이동하냐에 따라서
different data가 도출될 테니, 그것도 확인해야 하구요.
즉,
Loop Cycle을 최대로 Bound하고,
가장 긴 path를 상정하고 계산하며,
Cache miss의 수도 최대로 bound하고,
이 상황에서 각 instruction에 대한 execution time을 계산해야
Analysis 방법으로 계산한 WCET가 나오는거죠.
가능만 하다면, WCET 계산은 Analysis를 이길 수 없어요!
Measurement는 멍청하게 여러번 실제로 해보는거구요.
미사일발사나 항공우주 프로토콜처럼 여러번 해보기가 거의 불가능한 종목들은
세기의 천재들 모아다가 Analysis를 시키는 게 나을거고,
여러 번 실행해볼 수 있는 task들은
실제로 여러 번 해서 WCET를 계산하는 편이 낫겠죠.
