Scheduling Time-critical Tasks
이어서 가봅시다!
우리가 앞서 Schedule을 Time과 Task들에 대한 함수로 정의했는데,
그 Schedule S가 다음 제약들을 만족시킨다면, feasible하다고 합니다.
-
Timing Constraints : Activation , Period, Deadline, Jitter
(Jitter : 작업의 도착 / 시작 시간의 변동성) -
Precedence : order of execution between tasks
-
Resources : Synchronization for mutual exclusion
그리고,
task set T를 위해 Feasible한 스케줄을 만들어주는
알고리즘이 존재한다면, task set T를 feasible하다고 합니다.
만약 algorithm A가 task set T를 feasible하게 할 수 있다면,
task set T는 schedulable with algorithm A라고 칭하구요.
일반적으로 Scheduling problem은 다음과 같이 정의됩니다.
Scheduling Problem
Given a set T of n tasks, a set P of p processors, and a set R of r resources,
find an assignment P,R -> T that produces a feasible schedule
under a set of constraints.
즉, Constraint, Resource, task 개수, processor 개수까지 고려해서
task set T를 feasible하게 만드는 알고리즘을 가져오라는 거죠.
1975년에, Garey와 Johnson이
General한 scheduling problem이 NP-Hard함을 입증합니다.
다행히도,
특정 Condition 하에서는 다항시간 안에 scheduling algorithm을 구해낼 수 있죠.
물론, 다항시간이라고 해도
task가 30개이고, 각 task마다 1ms씩 걸린다고 해도
O(n) 알고리즘은 30ms,
O(8^n) 알고리즘은 400억년이 걸리기 때문에
Time Complexity도 무척! 중요합니다.
간단한 가정을 해서, 문제를 쉽게 만들어봅시다.
Processor p개, task T개에 여타 resource, mutex까지 고려하면
학부생 수준에선 힘듭니다.
- Uniprocessor
- Homogeneous task set (각 task들이 비슷한 성질을 가짐)
- Fully-preemptive
- Simultaneous activation (activation time이 전부 일정함)
- No precendence constraints (task A가 task B보다 앞서야 한다 같은 조건 X)
- No resource constraints
Taxonomy
알고리즘을 분류하는 체계를 정리해볼 수 있습니다.
Preemptive 알고리즘이 좋나요, Non-preemptive 알고리즘이 좋나요?
알고리즘 자체의 Preemptive 허용도에 따라서 알고리즘의 성능이 바뀔 수도 있습니다!
이는 Task의 preemptiveness와는 다릅니다.
Task가 preemptive한 task들 (중간에 충분히 interrupt 가능)으로 이뤄져 있어도,
알고리즘상으로 선점이 불가능하게 제작하면
또 괜찮은 스케줄링 알고리즘이 될 수 있는거죠.
Static 알고리즘? Dynamic 알고리즘?
미리 알 수 있는 고정된 Parameter를 바탕으로 decision이 이뤄지는 걸
Static 알고리즘이라고 하고,
Runtime에 변화할 수 있는 Parameter를 바탕으로 decision이 이뤄지면
Dynamic 알고리즘이라고 부릅니다.
Offline ? Online ?
Task가 activate되기 전에 모든 scheduling decision이 완성되어,
Table에 저장되는 Table-driven scheduling을 Offline 알고리즘이라고 부르고,
Run-time때 scheduling decision이 완성되는 경우를
Online 알고리즘이라고 부릅니다.
Optimal? Heuristic?
특정 최적화 기준 (Optimality Criterion)을 기준으로
cost function을 최소화하는 알고리즘이 Optimal 알고리즘이고,
Optimality Criterion을 만족하려고 노력하는 알고리즘이
Heuristic 알고리즘입니다.
(이 경우는 Optimality를 보장할 수 없습니다!)
그러면 Static 알고리즘은 다 Offline 알고리즘인가요?
그렇지는 않아요!
Offline 스케줄링은 table-driven scheduling이 특징인데,
Static은 미리 알 수 있는 Parameter 바탕으로 schedule이 이뤄집니다.
만약 activation time이 정해지지 않는다면, Offline 스케줄링이 불가능하죠.
activation time을 모르니 스케줄링이 불가한거에요.
언제부터 시작할지는 알아야죠.
Optimality criterion
어떤 기준으로 optimality를 정의할 수 있을까요?
- Task set T가 feasible하다면, feasibility 측면에선 Optimal합니다.
만약 우리가 '딴건 다 필요없고, feasible한 스케줄이 필요해' 하다면,
아무리 오래 걸려도 아무튼 feasible한 스케줄링 방식이 optimal한거겠죠.
- Maximum Lateness가 criteria라면,
그걸 최소화하는 알고리즘이 lateness 측면에서 optimal 할거구요.
- Deadline Miss를 최소화하는게 목표라면, (이 경우 hard rts는 아니겠군요.)
그 개수를 최소화하는 알고리즘이 optimal할거구요.
- 각 task에 특정 value를 부여하여,
feasible task의 value 합을 최대화하는것이 목표일 수도 있구요.
목표는 여러 개 잡을 수 있습니다.
Task Sets
우리는 여러 Task Set을 가정해볼 수 있습니다.
task당 activation이 한번만 일어나는 Single-job tasks,
task가 정기적으로 계속 activate되는 Periodic tasks,
task가 최소한도의 주기만 두고 activate되는 Sporadic tasks,
task들이 마땅한 주기 없이 activate되는 Aperiodic tasks,
이것 저것 섞인 Mixed Tasks입니다.
Classical Scheduling Policies
전통적인 스케줄 방법입니다.
real-time용으로 설계된건 아닙니다!
FCFS
Arrival time을 바탕으로 먼저 온 놈을 먼저 Serve합니다.
먼저 왔으면 먼저 끝남이 전제된 알고리즘이라서,
내부적으로 Non-preemptive한 알고리즘입니다.
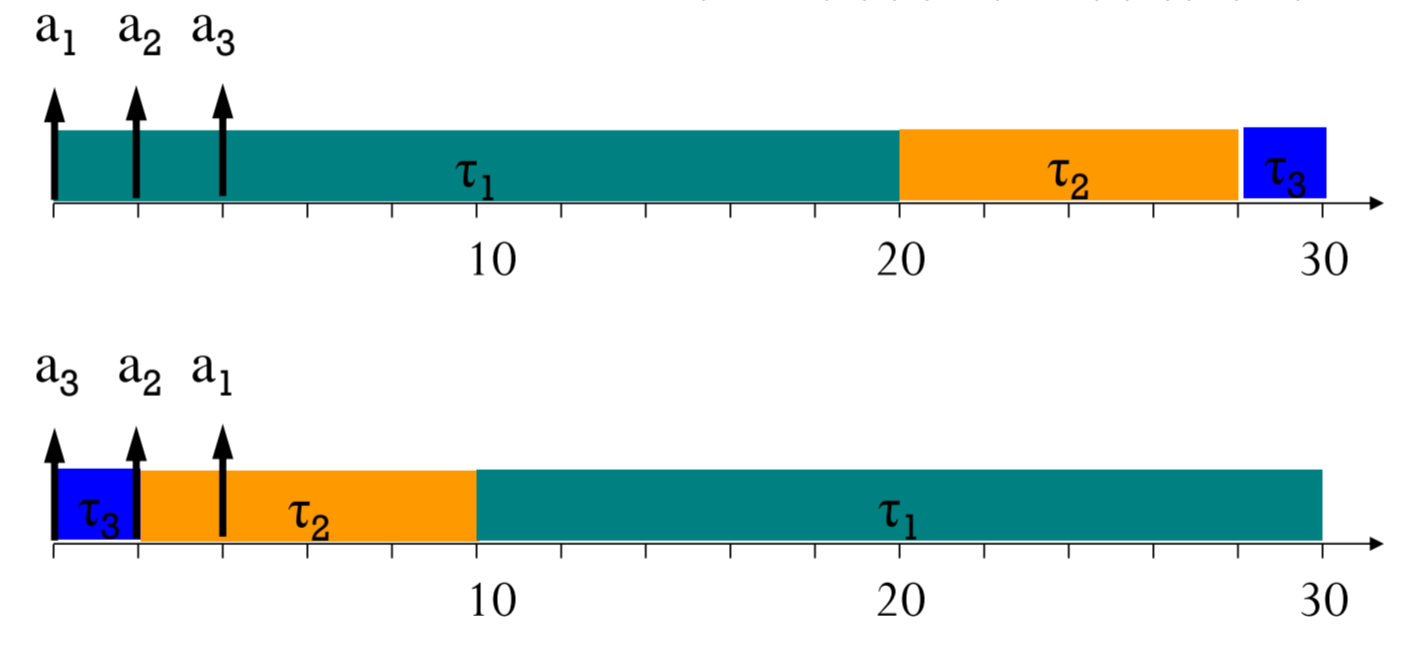
Activation time에 따라 상당히 불규칙적이죠?
분명히 같은 task set인데도 task의 순서가 매우 다릅니다.
Task가 10개만 되어도 360만개의 순서쌍이 가능해요.
SJF
Shortest Job First.
가장 빨리 끝나는
= 가장 Computation time이 짧은
task를 먼저 스케줄 하겠다는 뜻이죠.
Execution time을 미리 알 수 있다면 Static 스케줄링이고,
Activation time까지 알려져 있다면 Offline으로,
그게 아니라면 Online 스케줄링으로도 사용 가능하며,
Preemptive, non-preemptive 상관 없습니다.
그냥 Computation time이 짧은 순서대로 끝나는것만 보장이 되면 돼요.
SJF - Optimality
SJF의 optimality를 Average Response Time 측면에서 평가해봅시다.
(Optimality는 기준을 정하기 나름이에요!)


앞서 Simultaneous activation time을 상정했기에,
SJF쪽 스케줄링이 Average Response time이 더 작음이 보장이 됩니다.
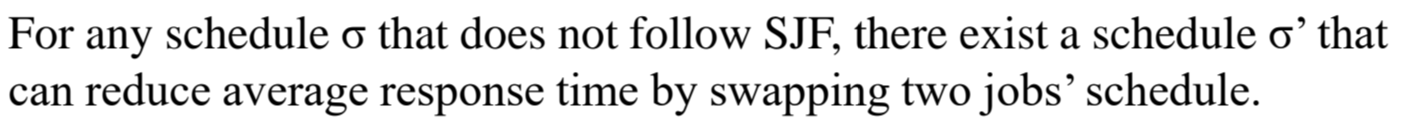
SJF를 따르지 않는 모든 스케줄은,
두 job의 schedule을 swap함으로서 Average Response Time이 작아지게끔 스케줄링이 가능합니다.

따라서 Criterion이 ARET (Average REsponse Time)이라면,
SJF는 Optimal하죠.
어떤 스케줄이든 SJF 방향으로 갈 수록 Average Response time이 줄어드니까요.
그럼 SJF가 짱인가요?
Real-time이 아니라면 그럴수도 있죠!
하지만 Real-time에선 얘기가 다릅니다.
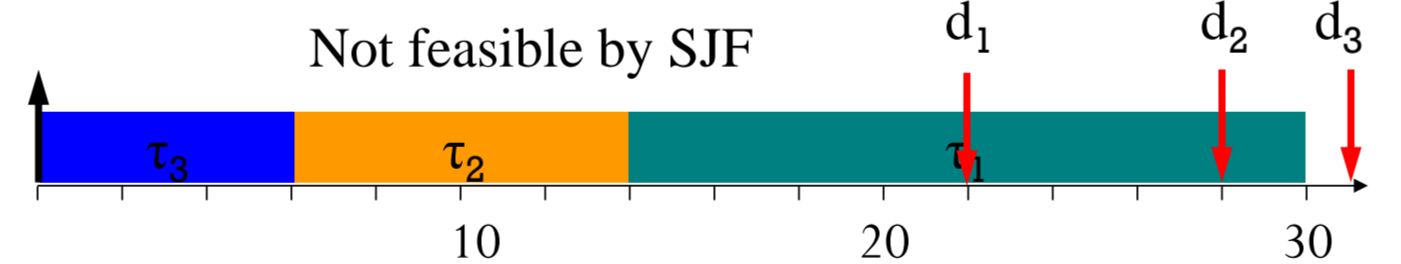
분명 SJF를 따랐음에도, task 1에 대해 deadline miss가 발생했죠.
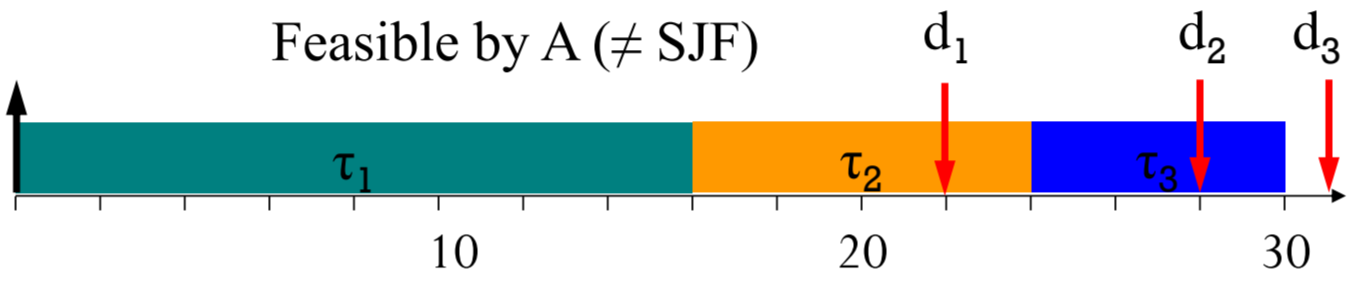
오히려 LJF를 따랐을 때 schedulable해졌네요.
