Resource Sharing and Task Synchronization
지금까지 다뤘던 내용은
task가 uniprocessor에서 작동하고,
periodic하며 no interaction between task를 상정했습니다.
하지만,실제 세상에서 task끼리 share가 없을 수가 없습니다.
concurrent task같은 경우는 이 자원 저 자원 나눠야 하죠.
그래서, 이런 의존성이 있을 때에는 task끼리의 순서 정하기가 정말 중요합니다.
이걸 task synchronization problem이라고 부릅니다.
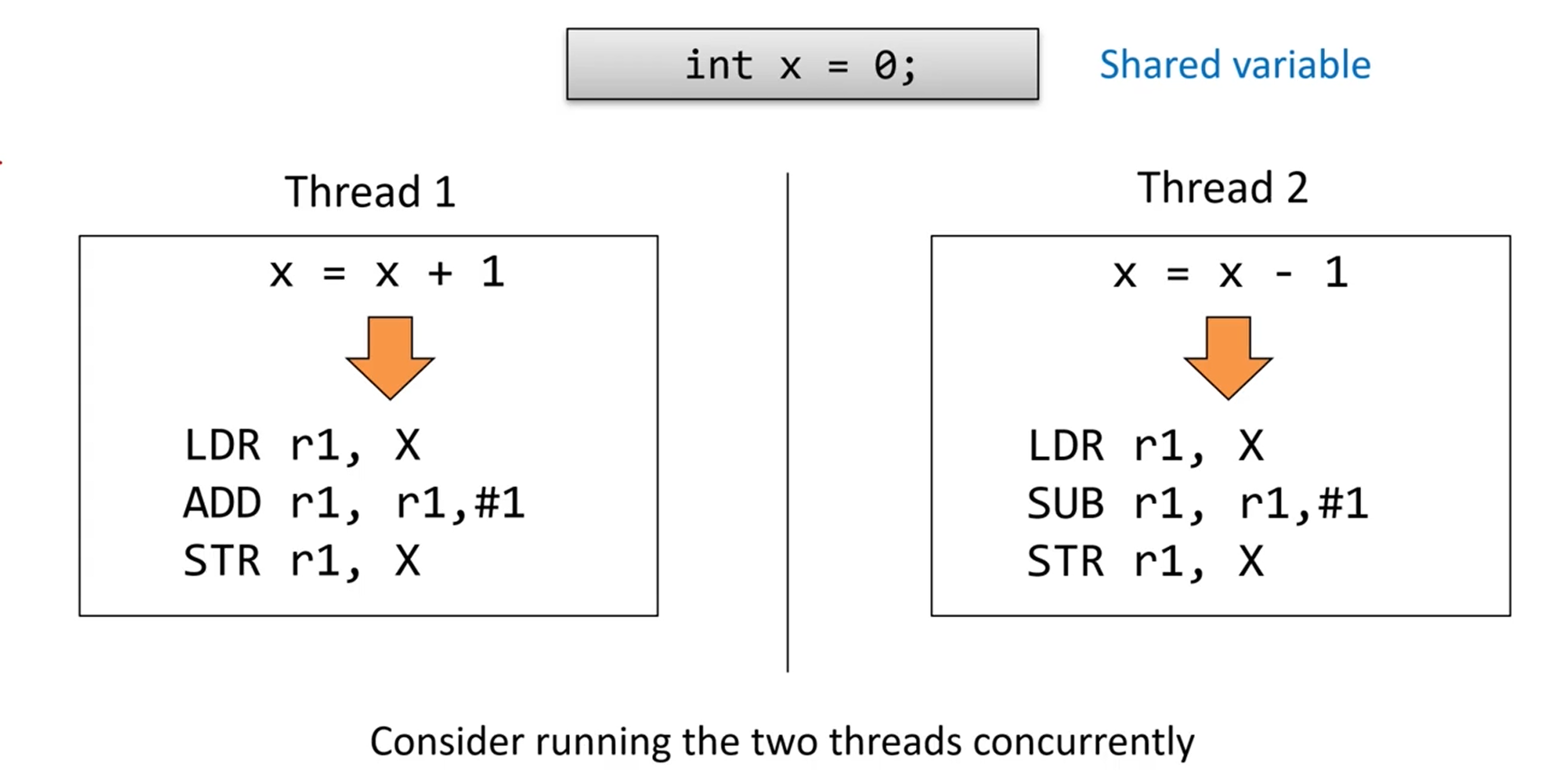
다음 공유변수를 공유하는 2개의 쓰레드가 있다고 합시다.
os를 조금만 공부해봤으면 알죠. race condition이 발생합니다.
만약 x = x+1이 'atomic'하게 일어난다면 race condition은 발생하지 않습니다.
그래서, race condition을 그나마 없애주기 위해 3가지 property가 필요합니다.

- MuTeX
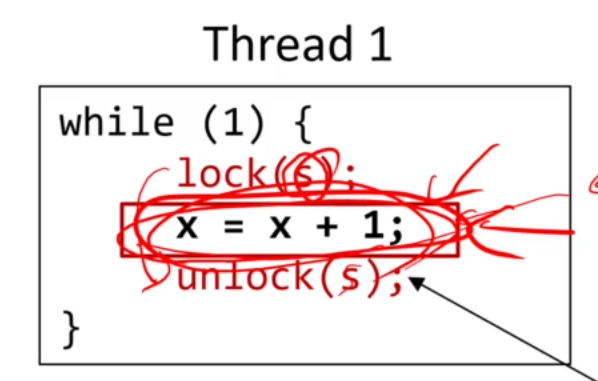
다음과 같이 lock을 critical section 사이에 걸면, Mutual Exclusion이 보장됩니다.
x = x+1;이 atomic하게 실행되는 것이 보장됩니다.
Priority Inversion
기존의 priority를 assign한게 있는데,
Lock 때문에 저순위 task가 고순위 task를 기다리게 하면,
뭔가 priority가 뒤집힌 것 같죠
그래서 priority inversion이라고 합니다.
그리고 그 priority inversion이 일어나는 시간을 'Blocking time'이라고 부르구요.
자연스럽게, Blocking time의 bound는 critical section의 duration과 연관이 있겠다 라는 생각이 듭니다.
Priority Inversion의 원인으로는, 가장 큰건 역시 방금 한 Syncrhonization / Mutual Exclusion이고,
Non-preemptible region of code, FIFO queue 등에서 priority inversion이 일어나기도 합니다.
Unbounded Priority Inversion

다음과 같은 flow가 있습니다.
lowest priority task가 lock을 잡으면,
highest priority task가 preempt를 해서 가져가도,
그 다음 영역이 lock이 걸려있는 영역이라면 자연스럽게 턴이 넘어가거든요.
그래서 (이게 priority가 있나?) 싶은 flow가 나옵니다.
그리고, 가장 큰 문제는 critical section과 관련도 없는 의 저 큰 blue block을 보십쇼.
지는 뭔데 보다 먼저 가냐 이겁니다.
은 락이라도 들고있지.
Schedulability Check with Blocking Time
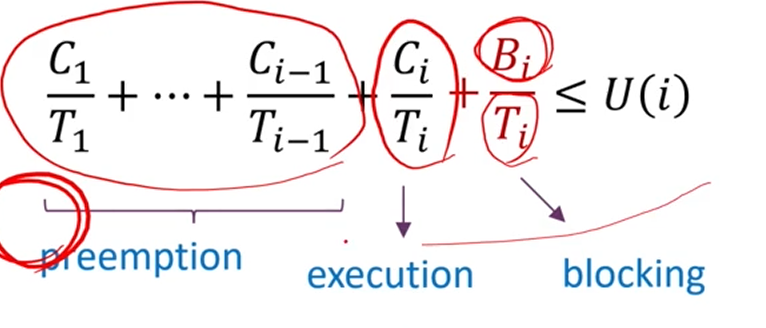
Task들이 priority가 감소하는 방향으로 놓여져 있다면,
Task 의 blocking time까지 고려해서 다음 식을 완성할 수 있구요.
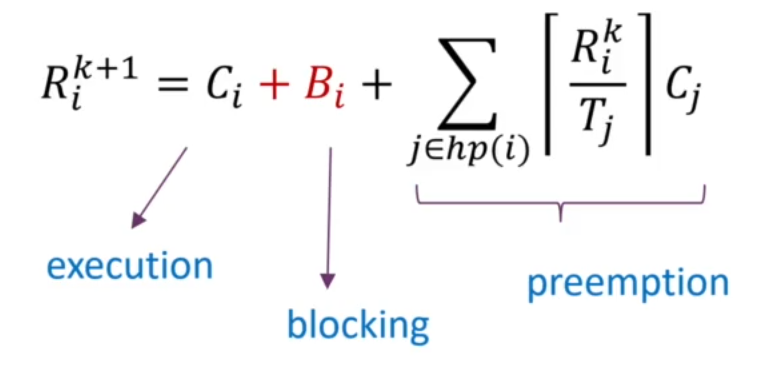
Response Time Analysis도 blocking time을 고려해서 할 수 있습니다.
그러면 그 Blocking Time은 누가 재주나요?
Synchronization protoocol에는
PIP (Priority Inheritance Protocol),
PCP (Priority Ceiling Protocol),
HLP (Highest Locker's Priority),
NPCS (Non-preemptive Critical Sections)
정도가 있습니다.
각 protocol은 unbounded priority inversion을 없애주구요.
즉, priority inversion이 일어날 수는 있으나 전부 관리되는 상황이라는 뜻이죠.
이 각각의 protocol의 성능은 각 task의 blocking time을 따라갑니다.
PIP (Priority Inheritance Protocol)
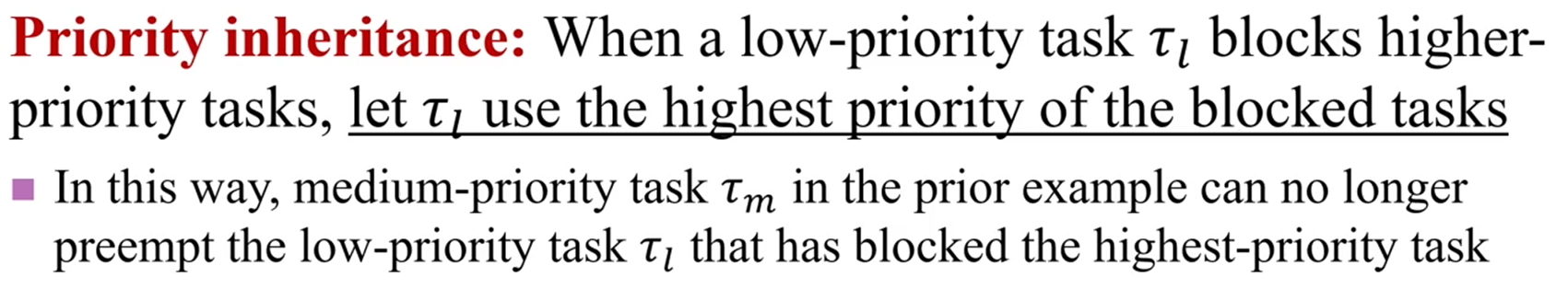
만약 가 lock을 잡고 blocking을 시전한다면,
block된 모든 task들 중 가장 뛰어난 priority를 '이전'받습니다.
그러면 priority inversion은 일어나지 않죠.
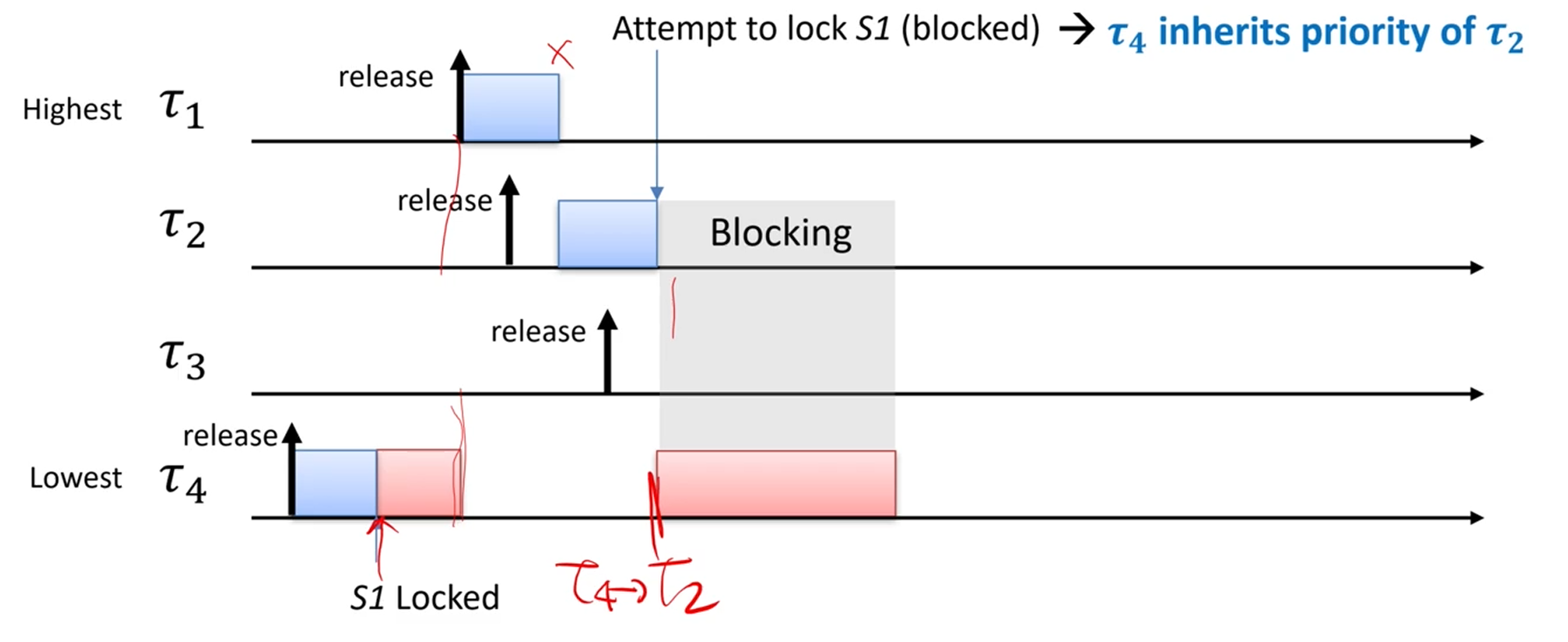
포인트는 '어 ㅅㅂ 락걸렸네 야!! 락 들고있는 놈 누구야!! 너 빨리 끝내!!' 입니다.
예전 운영체제 때 배웠던 '화장실 문 키' 정도로 비유하면, 빠르게 이해가 됩니다.
화장실 안 쓰는 애들은 상관없는데,
화장실 쓰는 애들은 미칠노릇이죠. 하루라도 빨리 저놈이 화장실을 비우게 해야 합니다.
Deadlock under PIP
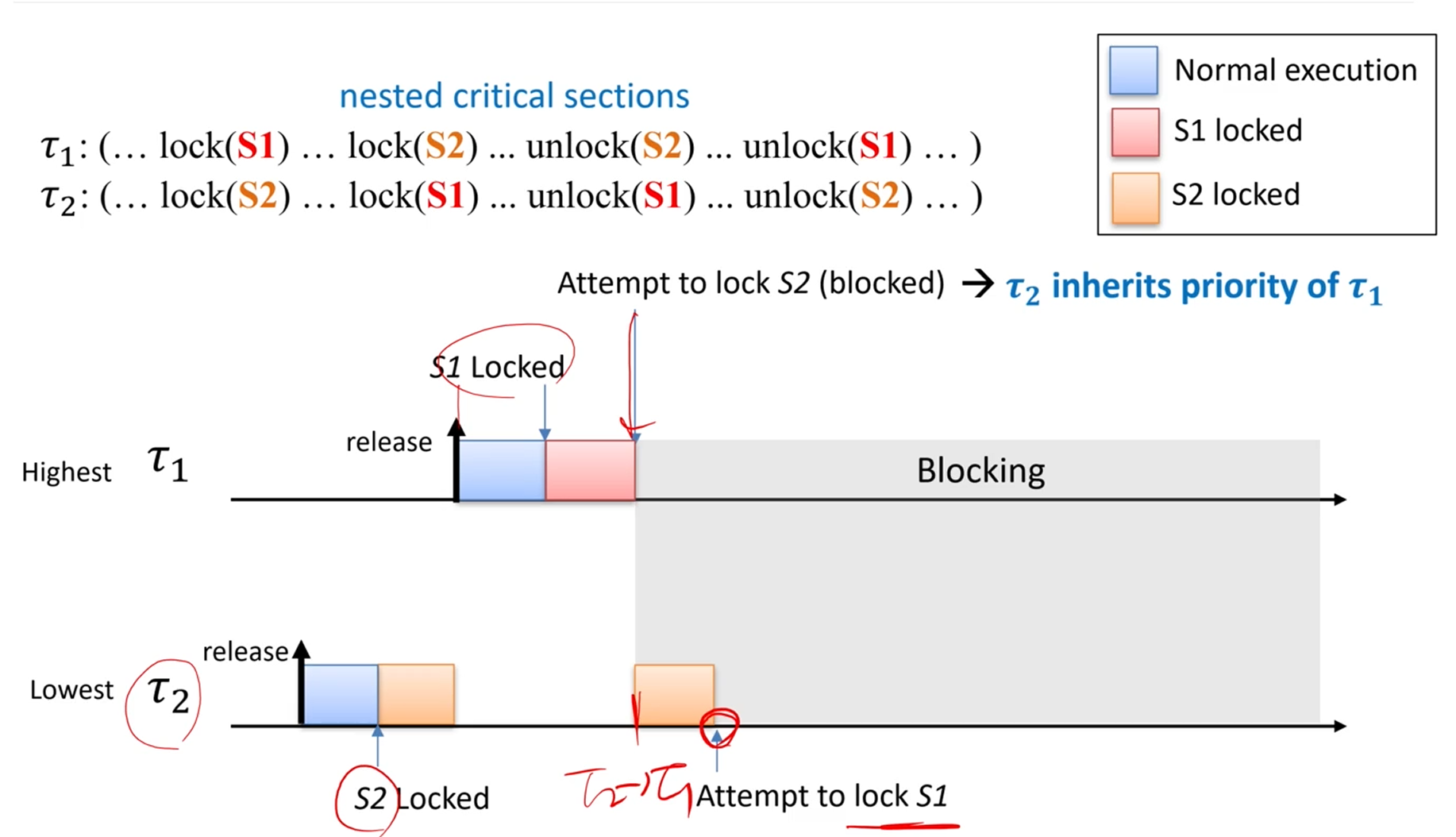
서로가 서로에 대한 lock을 보유하고 있다면,
"야 나 S1 락 없음. 너 가져가 나 기다릴게"
"야 나 S2 락 없음. 너 가져가 나 기다릴게"
...
이렇게 deadlock이 발생할 수 있다는 것입니다.
Blocking time in PIP
High priority task는 언제 block될까요?
- 각 lock마다 최대 1번씩
- 각 lower-priority task마다 최대 1번씩
이렇게 block을 당할 수 있습니다.
즉, 각각을 m, n이라고 하면 만큼 blocking을 당한다는 거죠.
그리고 그 Blocking Time을 계산하기 위해
Resource Usage Table을 만들 수 있습니다.
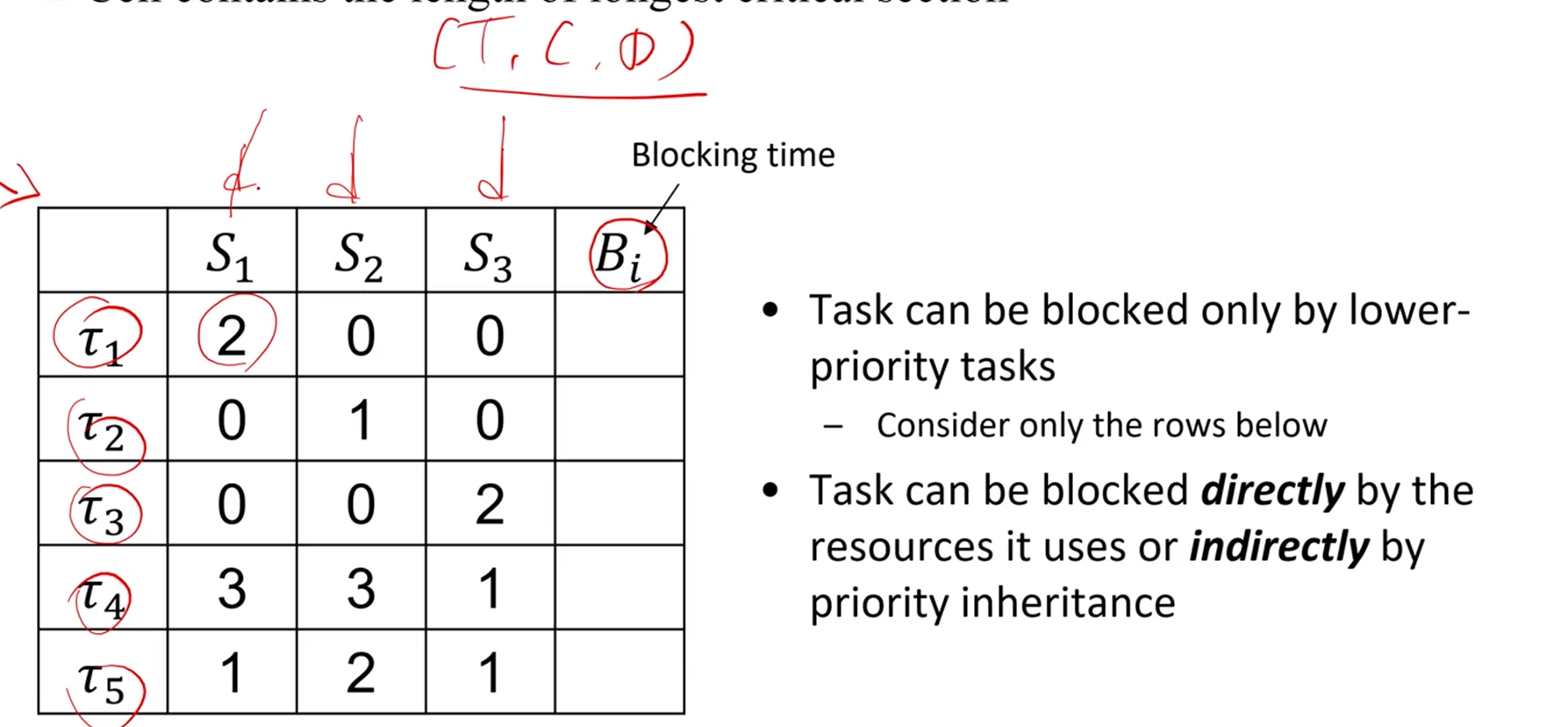
B1부터 시작합니다.
의 라는 의미는, 이 에 접근하는 시간이 2라는 뜻입니다.
즉, 이 때문에 block당한다면, 그건 최대 3만큼 block당하게 되겠죠.
Blocking Time은 '원래 고우선순위 task의 실행시간인데 저우선순위 task가 막고있음' 이 성립하는 시간입니다.
만약 가 을 방해하고 있다면, 최대 1초일 거고,
1초가 지나면 lock 풀고 에게 가겠죠.
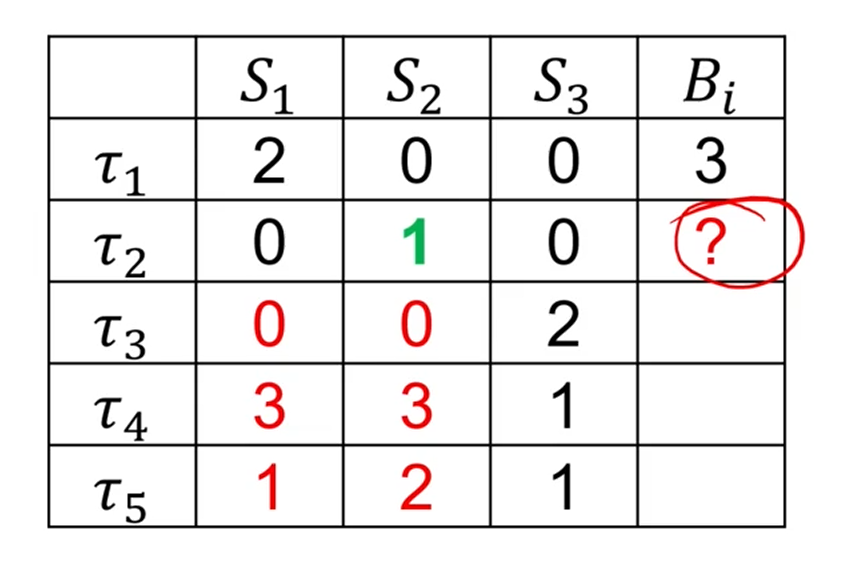
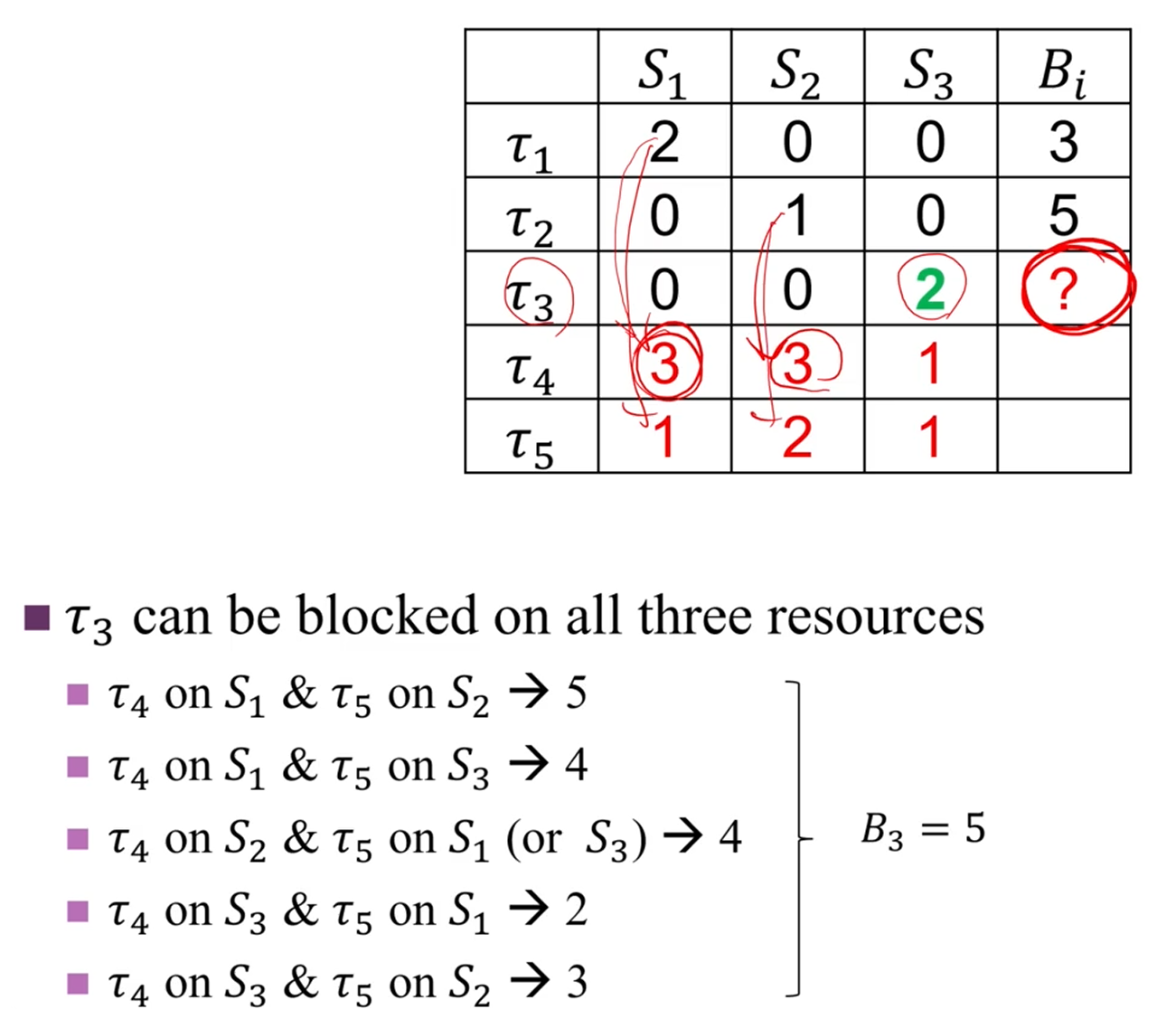
그 다음이 중요한데, 는 과 에 의해 block당할 수 있습니다.
왜죠?
그건, task가 Priority Inheritance에 의해서도 block될 수 있기 때문입니다.
이 '아, 갖고싶다.' 해서,
에게 넘어간 상태입니다.
원래는 에서 넘어간다면 그 다음 정실은 죠.
근데 가 3이나 쳐먹고 턴을 넘기네요?
그러니까 에 의한 delay도 포함이 됩니다.
이 경우에 worst case를 따지면,
가 3을 막고, 가 2를 막는 케이스가 최대네요.
는 5입니다.
Advantage of PIP
Unbounded Priority Inversion을 막아줍니다.
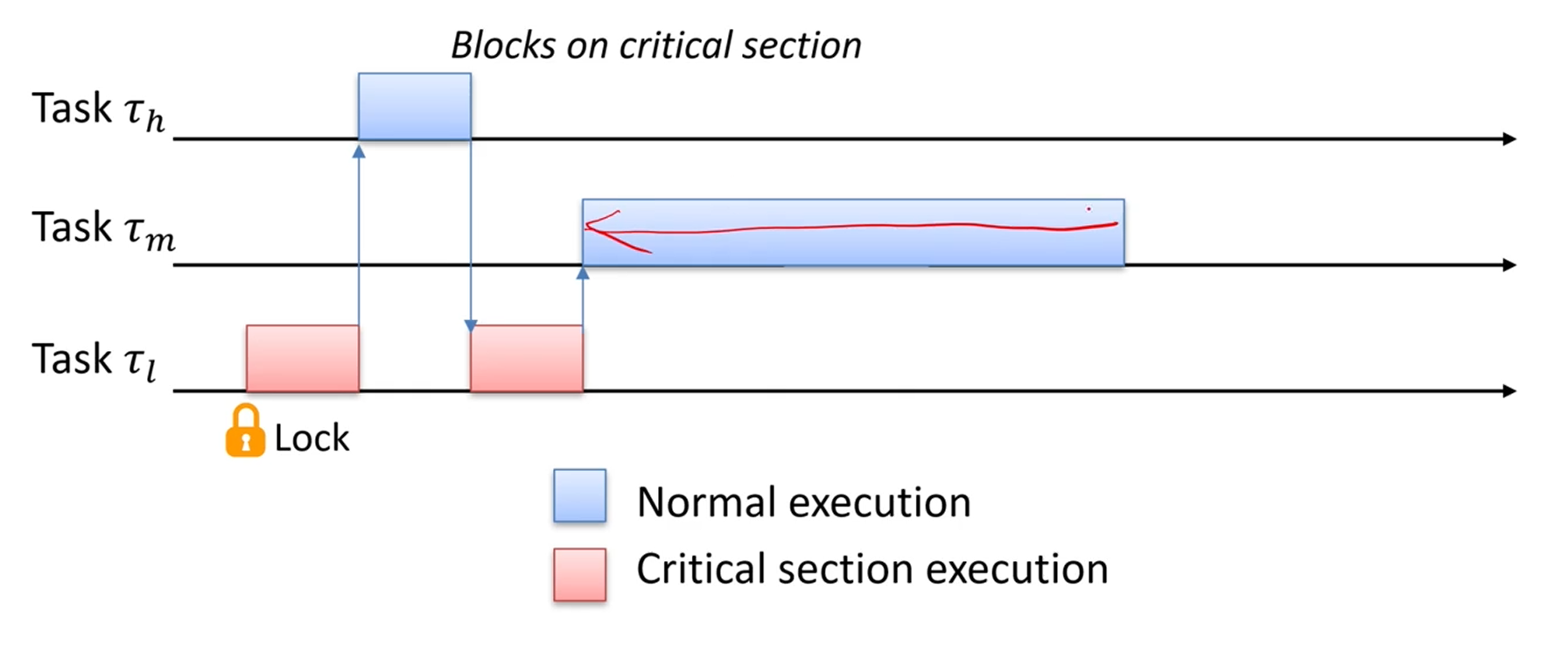
이딴 식으로 의 실행시간이 길 때, 언제까지 기다려야할지 모르는 그런 상황은 일어나지 않아요.
Resource Usage Table을 그려보면 어느정도가 blocking될지 예상이 가능하죠.
Disadvantage of PIP
단점은, deadlock을 막을 수 없고, chain blocking에 걸릴 수 있으며,
하나의 job이 여러번 block 당할 수 있다는 것입니다.
