지금까지 나온 Q&A를 정리합니다.
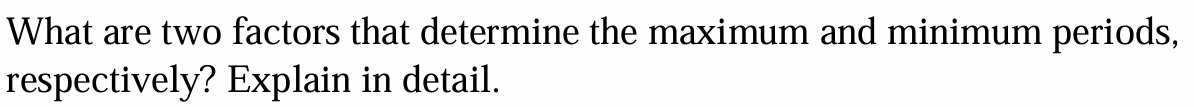
마땅한 deadline을 보유하고 task를 schedule할 때,
Task의 주기가 너무 짧다면, 다른 여타 Task들을 고려했을 때
Schedulable하지 않게 될 것이고,
Task의 주기가 너무 길다면, deadline miss가 발생하겠죠?
Rate Monotonic Schedule을 고려했을 때에는,
minimum period를 구하고자 하는 task를 Task s라고 둘 때,
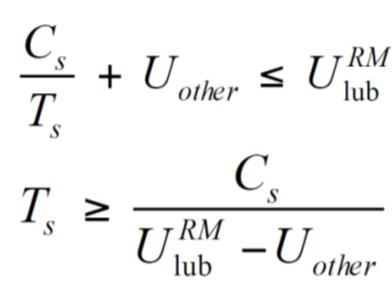
해당 target task와 나머지의 utilization을 더해서 0.69 (Liu-Layland 한계)보다 작으면
Task가 schedulable합니다.
Maximum case는 언제 deadline miss가 일어나는지에 대해 알아야 겠죠.
코드로 설명을 대체합니다.
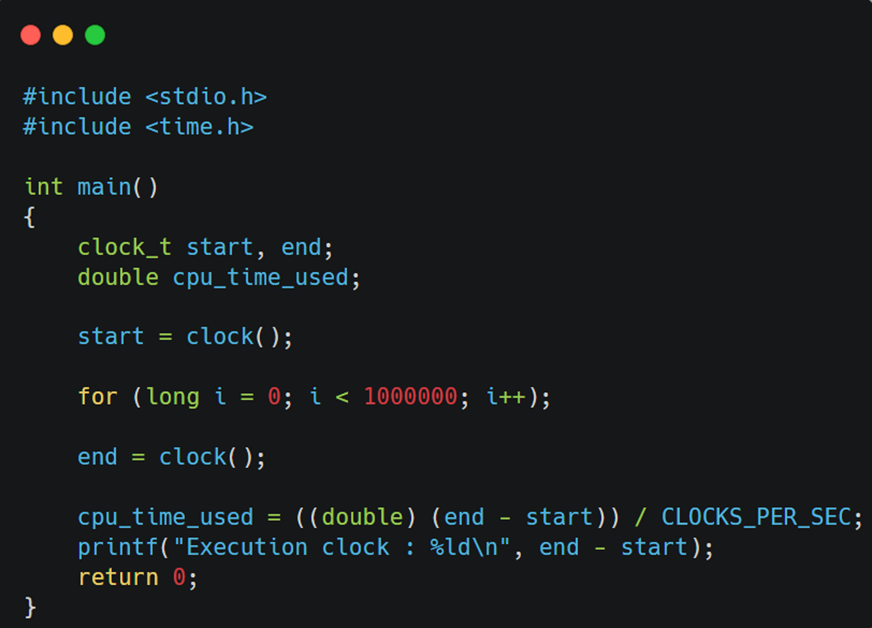
clock()과 CLOCKS_PER_SEC을 통해,
몇 clock을 사용했는지, 그게 몇초인지 체크가 가능하죠.
물론 좀 더 low-level로 내려가면, clock을 measure하고 print하는 시간까지
포함해야 하기 때문에, 훨씬 복잡해집니다.
단순히 measure하는 방법으로는 clock()가 있다~ 정도만 알아도 될 것 같아요.

순서대로, task i에 대한
- Computation time (start time ~ finish time. 중간에 context switch로 ready가 된 시간까지 싹~다 포함)
- Activation Period
- Relative Deadline (activate되고 deadline까지 몇초가 주어지는지)
- Utilization (C/T)
- absolute activation time
- absolute starting time
- absolute finish time
- Response time
대문자는 시간, 소문자는 시각.
activation time은 ready queue에 들어오는 시각이고,
starting time은 걔가 CPU에 의해 실행이 시작되는 시각이죠.

available offline은 실행하기 전에 알 수 있다는 것이고,
available online은 실행해야지만 알 수 있다는 뜻이죠.
Computation time
일반적으로 WCET로 분석이 가능합니다.
하지만, input이 방대하거나 매우 다양하고,
코드가 방대하여 Analysis 방식으로 측정이 불가한 경우,
이 경우는 Measurement 방식을 이용해야 할 것이고,
측정해야만 알 수 있는 Online이 되겠네요.
Activation Period
Periodic task같이 task의 주기성이 알려진 경우,
offline으로 measure할 수 있습니다.
하지만, aperiodic task나 sporadic task에선 online으로 measure할 수밖에 없죠.
Relative Deadline
Available Offline.
이건 미리 알고 있어야죠.
Deadline을 실행 해봐야만 알 수 있다면,
Deadline의 존재 의미 자체가 희석됩니다.
Utilization
C,T의 online/offline 여부에 따라 갈리겠네요.
Absolute activation time
Static task의 경우는, 실행 전에 전부 table에 기록하고 시작하기에
absolute activation time까지 계산이 가능합니다.
그게 아니라면, online에서만 계산 가능하죠.
Absolute starting time, absolute finish time
이 또한 마찬가지입니다.
Response time
static task이며 Periodic task라면 response time도 명확하겠죠.
그러나 periodic하지 않아 period를 정의할 수 없거나,
static task가 아니라서 starting time / finish time / computation time을
모른다면,
runtime에서만 측정할 수 있겠네요.
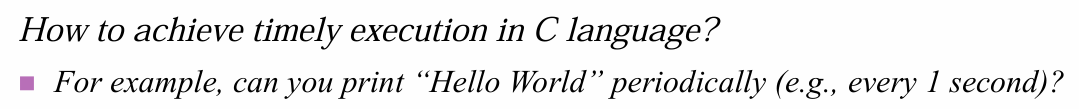
1초마다 돌게끔 spin-lock 프로그램을 짤 수 있겠네요!
물론 이것도 spin-lock을 걸지 않게끔,
혹은 printf의 출력시간까지 고려하여 출력하는 등,
수많은 low-level approach가 존재합니다.
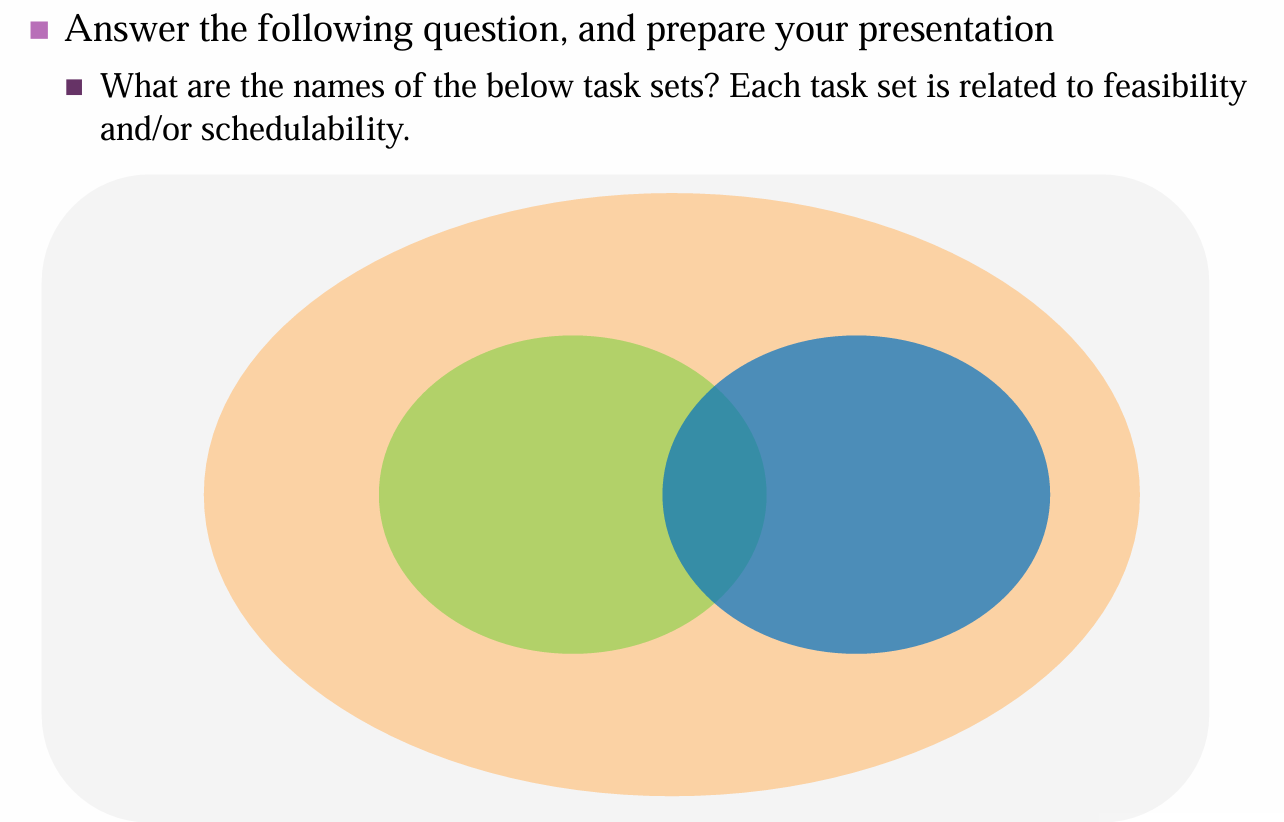
Feasible과 Schedulable의 정의를 잘 나타내는 다이어그램입니다.
특정 Schedule이,
- Timing Constraints (Activation, Period, Deadline, Jitter)
- Resource Restraints
- Precedence
등을 만족한다면, 그 schedule을 Feasible하다고 합니다.
그리고,
어떤 task set T에 대해 Task set T를 Feasible하게 만들어주는 schedule이 단 하나라도 존재한다면,
그 task set T를 feasible한 task set이라고 하구요,
만약 algorithm A가 task set T를 feasible하게 만들어준다면,
task set T is schedulable with algorithm A라고 합니다.
따라서 이 그림에서는,
초록이 Schedulable with algorithm A고,
파랑이 Schedulable with algorithm B이고,
주황은 Feasible task set이겠네요.
A, B가 아니더라도 세상 수많은 스케줄링 알고리즘 중 단 하나라도
task set을 feasible하게 만든다면,
그 task set은 feasible task set이니까요.

Round Robin 환경에서 Task가 n개 있고,
각 task가 time quantum Q만큼의 시간만을 보장받으며,
계산의 편의를 위해 task들은 homogeneous하다고 가정합시다.
이 때, task의 avg response time은
정확하지는 않지만,
n(Q+d) * Ci / Q에 수렴합니다.
만약 Q = d라면?
avg response time은 n * 2Q * Ci / Q ~ 2nCi가 되겠네요.
context switch overhead가 아주 작을 때의 avg response time이 nCi에 수렴함을 생각하면,
사실상 response time이 2배가 되는 영향을 끼친 것을 볼 수 있습니다.
