Priority Scheduling
각 Task에게 Priority를 부여합니다. 일반적으로 0~255의 수치에요.
Priority가 높은 순서대로 스케줄링을 합니다.
Priority가 같은 task들은 FCFS manner로 다뤄집니다.
만약,
Priority가 1 / Computational time에 비례한다면? SJF가 되구요,
Priority가 1 / arrival time에 비례한다면? FCFS가 되겠죠!
그래서, SJF, FCFS도 큰 의미의 Priority Scheduling인 거에요.
Starvation
대신, 기아 현상에 봉착할 수 있습니다.
우선순위가 낮은 친구들은 Long Delay를 겪을 수 있어요.
특히, Priority Scheduling은 대체로 Preemptive하기 때문에,
'드디어 내 차례다!!' 해도, Priority 255짜리 task가 무더기로 activate되면,
말짱 꽝이죠.
그걸 Starvation problem이라 합니다.
가능한 해법으로는,
- Aging : 기다린 시간에 비례해 Priority를 높여 주는 것
- Promoting : T_Threshold만큼 schedule되지 못한 task의 priority를 promote하는 것
등이 있습니다.
RR
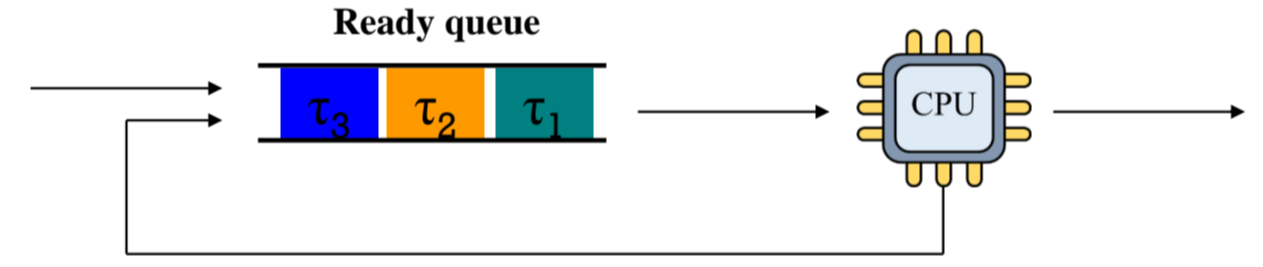
Ready Queue에서 FCFS Manner로 꺼내서 쓰긴 하되,
각 Task마다 실행가능 최대 시간을 Q time unit으로 한정합니다.
Q가 끝나면, 해당 Task는 queue의 제일 뒤로 빠지죠.
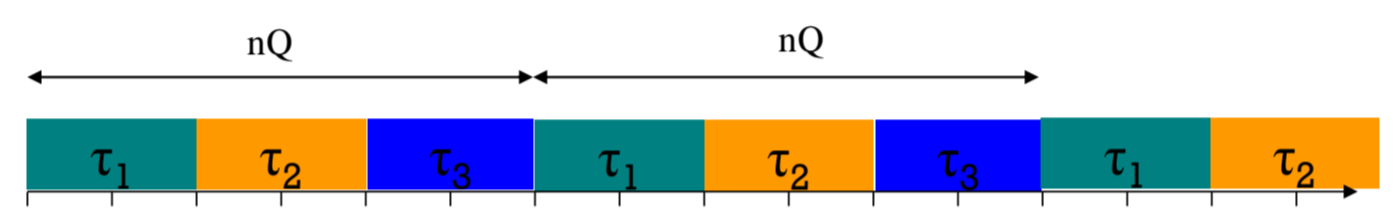
Context switch overhead가 없다는 가정 하에,
각 Task의 Response time을 계산해봅시다.
Activation time이 같으니까,
T1의 response time은 (nQ) * 2 + Q,
T2의 response time은 (nQ) * 2 + 2Q ..
n이 적당히 크다고 가정할 때,
Response time은 nQ * (Ci / Q) = nCi 에 수렴합니다.
nQ는 다시 자기 차례가 돌아올때까지의 시간이고,
Ci/Q는 자기가 몇회짜리 task로 쪼개졌는가를 의미하죠.
물론 완전 정확한 R_i는 따로 구해야 겠지만요.
그래서,
각 task 입장에선 원래의 CPU보다 n배 느린 CPU를 독점하고 있다고 생각할 수도 있게 됩니다.
Computation time이 그쯤 되니까요.

이번엔 Context-switch overhead가 존재하는 경우입니다.
똑같이 구하면 Response time은 n(Q+d) * Ci/Q 에 수렴합니다.
만일 쪼개지는 time Quantum Q가 max execution time보다 크다면,
어떤 task든 한번 스케줄되면 preemption 없이 쭉 끝까지 간다는 뜻이니까,
RR = FCFS가 성립합니다.
time quantum Q가 context switch time d와 비슷하다면,
아주 안 좋은 결과를 낳을 것이구요.
Multi-level scheduling
평생을 하나의 방법만 써서 스케줄링하지는 않습니다.
task의 종류에 따라 스케줄링 방식이 달라지죠.
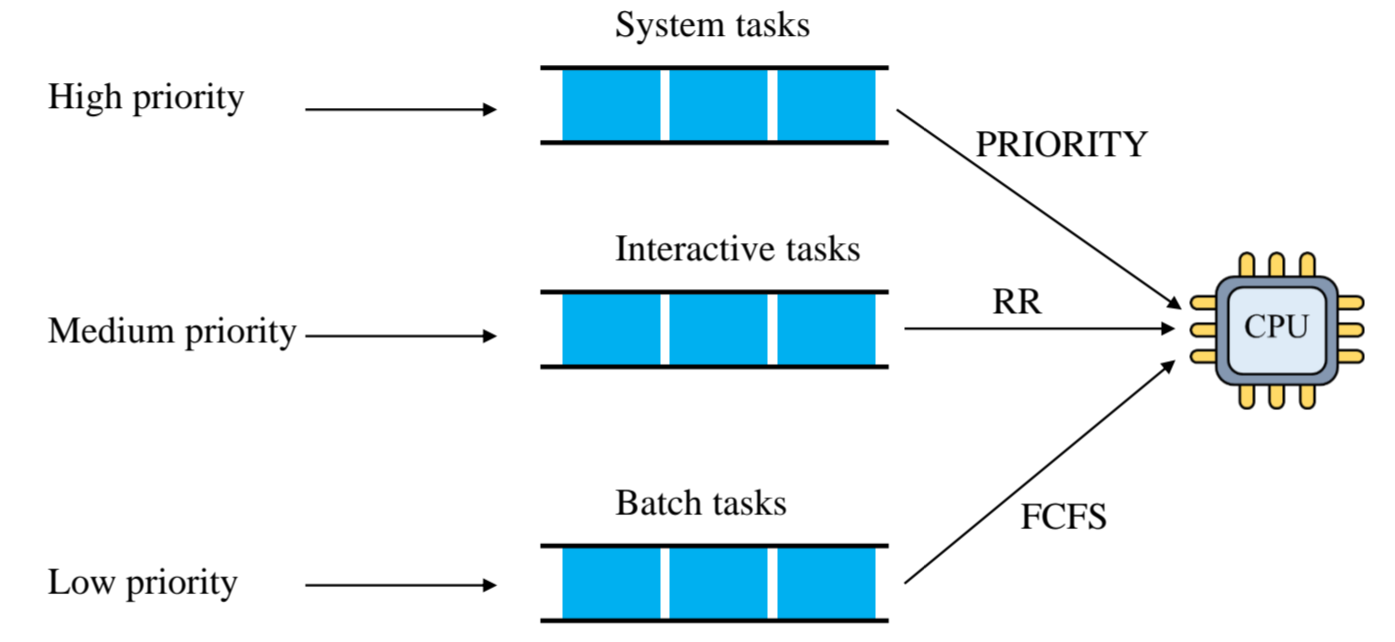
빨리 끝내야 하는 system task들은 Priority scheduling을 사용할 것이고,
딱히 그런거 중요하지 않은 Batch Task는 FCFS를,
Interactive task들은 Round robin을 써 주면 됩니다.
Graham's notation

Scheduling algorithm을 다음과 같이 표현하는 것을 Graham's notation이라 칭합니다.
a는 프로세서 개수입니다.
Uniprocessor면 1이겠죠.
B는 task에 걸린 제약입니다.
preemptive, synchronous, 등등.
r은 optimality criterion입니다.
우리가 만족하고 싶은 조건이죠.
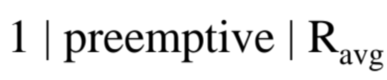
- Uniprocessor
- Task들이 Preemptive함
- Average Response time을 최소화 하고 싶음
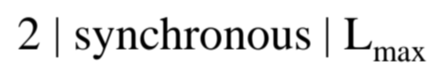
- Dualcore
- Task들이 똑같은 arrival time을 가짐
- Maximum Lateness를 minimize하고싶음 (이건 곧 배웁니다.)
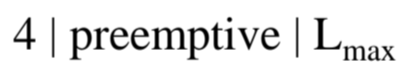
- Quadcore
- Task들이 똑같은 arrival time을 가짐
- Maximum Lateness를 minimize하고 싶음
EDD (Earliest Due Date)
FCFS, SJF, P, RR에 이어 EDD를 알아봅시다.
EDD는
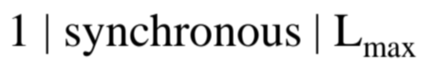
다음과 같이 표기됩니다.
- Uniprocessor
- Synchronous
- to minimize Maximum Lateness is the goal
Ready Queue를 deadline이 증가하는 순서대로 채우는게 알고리즘입니다.
Preemption이건 아니건 중요치 않습니다.
또, 각 Task별 데드라인이 고정되어 있다고 가정합니다.
이 때, EDD는 Maximum Lateness를 최소화함이 보장되어 있습니다.
Lateness
'얼마나 늦었느냐' 입니다.
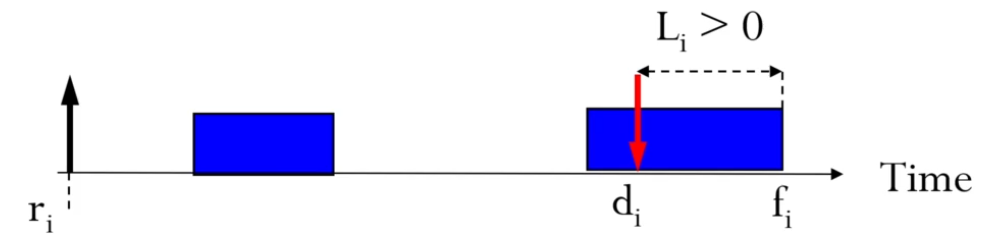
끝나는 시간에서 absolute deadline을 빼면 lateness입니다.
Lateness > 0이라면, 늦은거죠!
Lateness < 0이라면 안 늦은거구요.
Task들의 lateness가 각각
T1 : 4
T2 : 3
T3 : -1
T4 : 0이라면,
T4는 딱 맞춰 끝난거고,
T3는 좀 여유롭게 끝난거고,
T2, T1은 망한거죠.
이 경우 Maximum Lateness는 4고,
EDD는 이 Maximum Lateness를 최소화 하는게 Optimality Criterion입니다.
실제로 그 작업을 해주구요!

Earliest Deadline이 A인데, A가 먼저 스케줄되어 있지 않습니다.
EDD가 아니네요.
이 경우 Swap을 해줍니다.

앞선 경우의 Maximum Lateness : fA - dA (음수)
** EDD Case의 Lateness :
task A의 경우 fA' - dA인데, fA > fA'이니 fA' - dA < fA - dA
task B의 경우 fB' - dB인데, fB' = fA이고 dB > dA이니 fB' - dB < fA - dA
즉, 모든 경우 앞선 경우보다 lateness가 작으니,
maximum lateness도 더 작아졌군요!
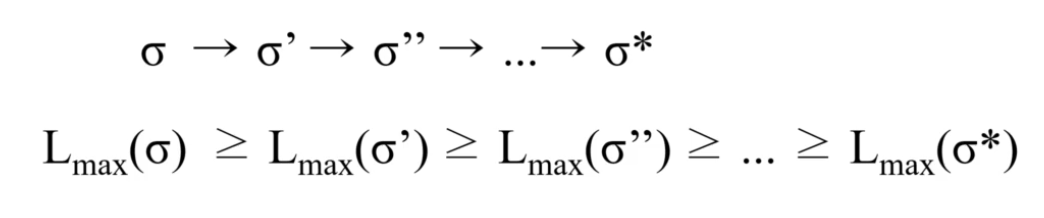
즉, schedule의 두 task를 EDD가 되게끔 swap하다 보면,
더 이상 swap할 수 없는 EDD case의 schedule이 발생하고,
이 경우가 Maximum Lateness를 최소화하는 측면에선 optimal하죠.
즉,
만약 내 목표가 feasibility, deadline miss, 그런거 상관 없고
Maximum Lateness만 최소화 하는 것이다 라면 EDD를 쓰면 되는거에요.
EDD Guarantee Test (Offline)
모든 parameter를 다 안다고 칩시다.
arrival time도 다 같은거고, 알고 있어요.
Deadline도 다 알고 있습니다.
Execution time도 다 알아요.
이 때, 모든 task set이 deadline을 지키는지 확인하고 싶습니다.

Execute를 실제로 하기 전에 이런 Schedule을 미리 만들 수 있죠?
모든 parameter를 다 아니까요.
수학적으로 표현해봅시다.
A Task set T is feasible, iff f_i <= d_i holds for every t_i in T.
Earlier Deadline task에게 낮은 번호를 부여했을 때,
모든 task T에 대해 f_i <= D_i가 성립하게 됩니다.
사실 당연한거죠.
EDF (Earliest Deadline First)
엥 ?
Earliest Due Date first나,
Earliest Deadline First나 똑같지 않나요?
예! 똑같은데요,
이번엔 좀 다릅니다.
Activation time이 같지 않아요.
Preemptive한 task를 가정합니다.
(주의! 이렇게 가정했다고 해서 EDF가 Preemptive한 task에서만 작동하는건 아닙니다.
Non-preemptive한 task들 사이에서도 작동 합니다!)
이 경우는,
Ready Queue를 Absolute Deadline이 증가하는 순으로 정렬합니다. (Horn's Algorithm)
EDF에서도 가정이 좀 필요합니다.
- Tasks can be activated dynamically.
- Dynamic Algorithm (d_i depends on a_i) (당연한거죠.)
- Tasks can be preempted
이 경우도,
놀랍게도 Maximum Lateness를 minimize 할 수 있다고 합니다!
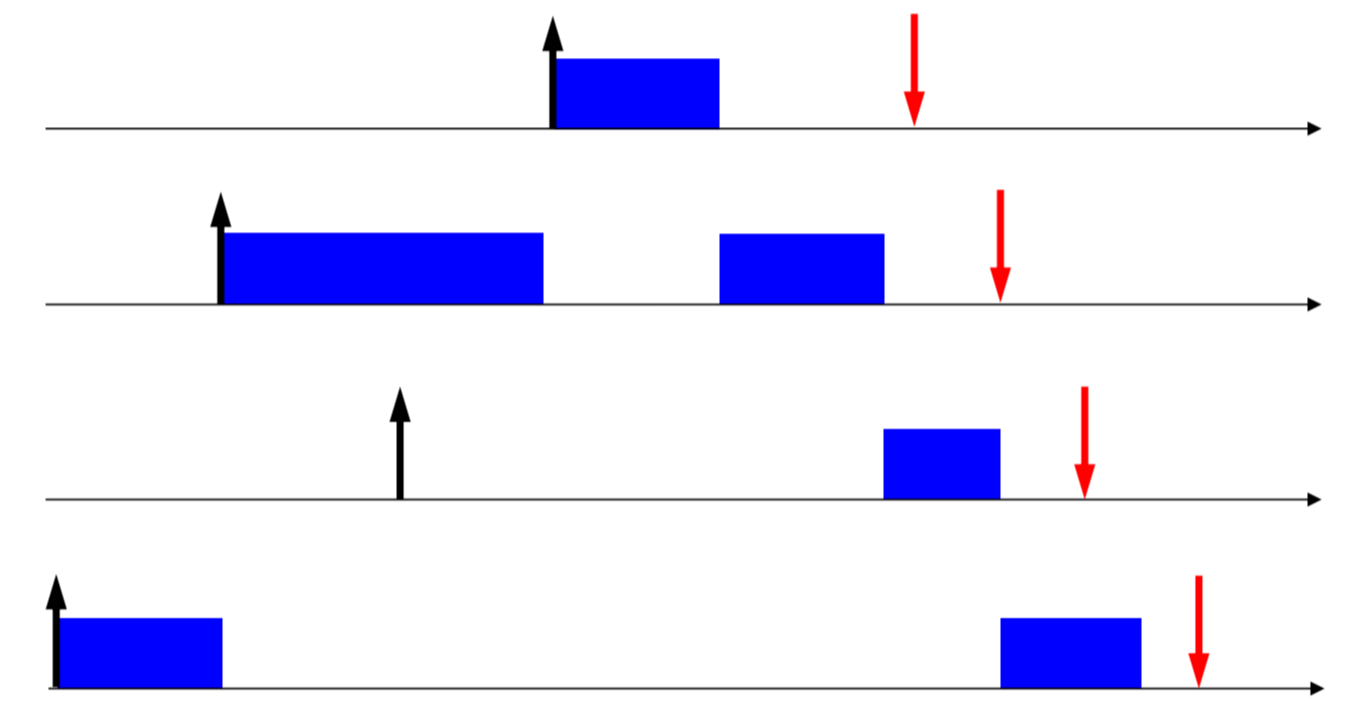
다음과 같은 4개의 task가 존재한다고 합시다.
상대적으로 다른 deadline을 가졌지만,
Absolute Deadline 순서대로, 위에가 priority가 제일 높고 아래가 제일 낮습니다.
재밌는건, Preemption이 발생했다는 점인데,
T4가 실행
-> 중간에 더 Absolute Deadline이 작은 T2가 들어옴, Preemption
-> 중간에 T3이 들어왔지만, 우선순위가 밀림
-> 중간에 더 Absolute Deadline이 작은 T1이 들어옴, Preemption
-> T1 종료, T2로 Context Switch
-> T2 종료 후, T3으로 Context Switch
-> T3 종료 후, T4로 Context Switch
EDF Guarantee Test
EDD와 다르게 EDF는 Online Scheduling Algorithm입니다.
또한, Preemption이 가능하죠.
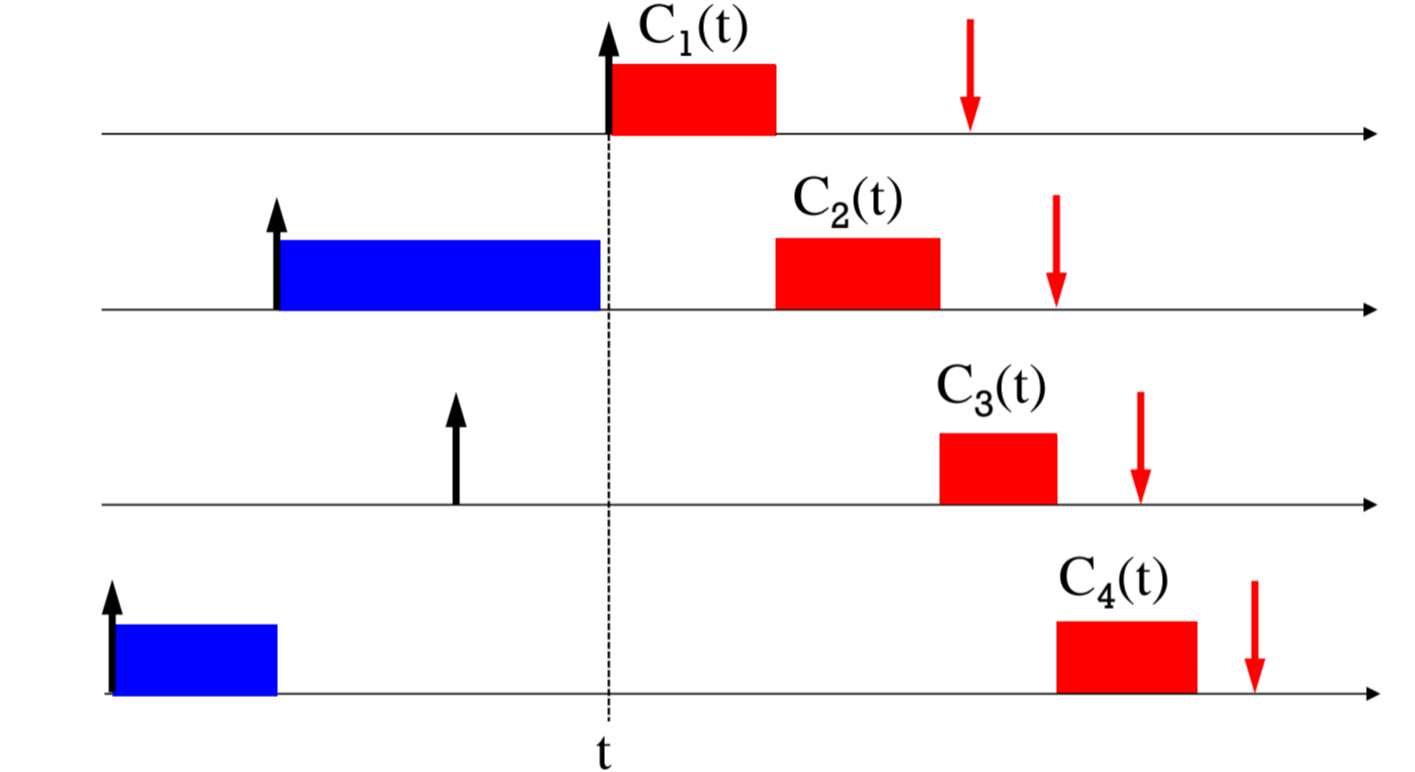
Task index들이 priority 순서대로 배정되었다고 합시다.
time t를 기준으로 봅시다.
time t에 task 1의 남은 execution time은 C1(t)입니다.
d1 - t보다 작죠. 자명합니다.
time t에 task 2의 남은 execution time C2(t)입니다.
C1(t)가 끝난 후 C2(t)가 priority를 부여받고 실행되었기 때문에,
C1(t) + C2(t)도 d2-t보다 작죠. 자명합니다.
time t에 task 3의 남은 execution time은 C3(t)고,
t1, t2가 끝난 후 역시 독점권을 부여받고 실행되기 때문에,
C1(t) + C2(t) + C3(t) 역시 d3-t보다 작은 모습입니다.
귀납적으로, EDF로 스케줄링하면,
모든 task의 f_i <= d_i가 보장이 된다면, EDF로 스케줄 시
feasibility 측면에서도 optimal함이 보여집니다.
Complexity - EDD , EDF
EDD
scheduler가 queue를 정렬하는 방법은, shortest deadline 순서대로 정렬하는 거죠.
static 알고리즘이고, 모든 정보를 사전에 알고 있기에
O(nlogn)만큼의 정렬을 1번 시행합니다.
Feasibility test는요?
C1이 D1보다 작은지 한번,
C1+C2가 D2보다 작은지 한번,
이렇게 가기에 O(n)만큼의 시간이 소요됩니다.
EDF
Task가 activate될 때마다 O(logn)만큼의 정렬이 필요합니다.
이미 정렬된 queue에 새 task를 넣는건 binary search일 테니까요.
Feasibility test는 똑같이 O(n)이겠네요.
EDF Optimality
the algorithm generates a feasible schedule, If there exists one.
이 문장이 성립한다면,
알고리즘 A는 feasibility 측면에서 optimal합니다.
만약 schedule이 EDF가 아니라면, 두 execution을 바꾸는 방식으로 나아가 봅시다.
Optimal algorithm은 2가지 특성이 있습니다.
-
If a task set T is not schedulable by an optimal algorithm,
then T cannot be schedulable by any other algorithm. -
If algorithm A minimizes Maximum Lateness,
then A is also optimal at the sense of feasibility.
The opposite is not true.
EDF Optimality - nonpreemptive
앞서 EDF를 가정할 때,
1|preemptive|Lmax로 가정했습니다.
만약 EDF가 non-preemptive 환경에서 사용된다면 어떨까요?
즉, activation time은 다를 수 있어도 absolute deadline이 짧은 순서대로 스케줄 하는겁니다.

다음과 같은 경우에는? schedulable하다고 할 수 있죠.
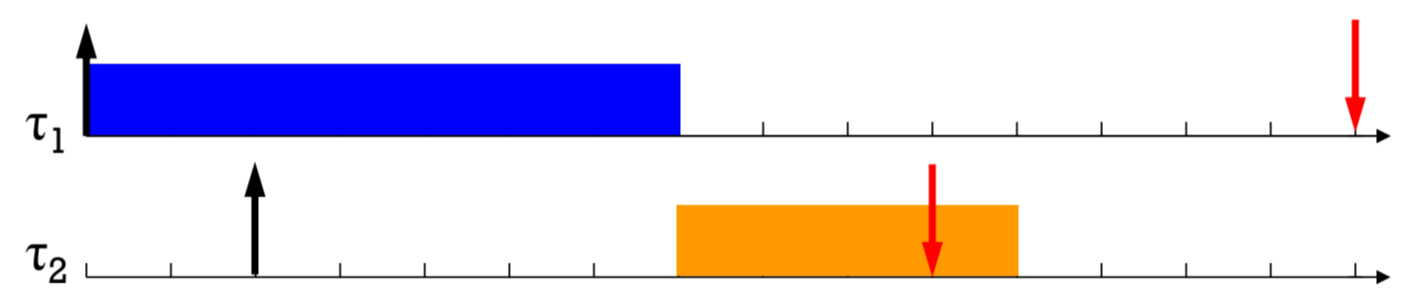
근데 이런 경우에는요?
Non-preemptive인데 EDF?
그 말은 중간에 더 abs.deadline이 짧은 친구가 들어와도 대응이 불가하다는 뜻입니다.
feasible하지 않네요.
Non-preemptive scheduling
원할 때 자르고 붙일 수 있는 preemptive scheduling과는 다릅니다.
algorithm이 clairvoyant 해야 scheduling이 가능해집니다.
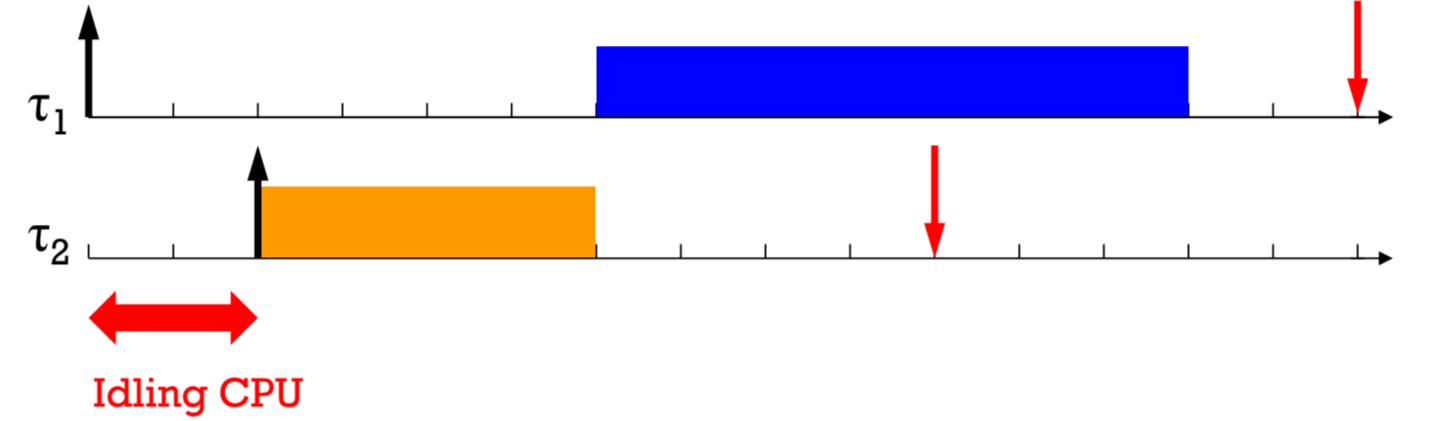
분명 T1의 activation 직후에는 task가 하나뿐이니 바로 실행해야 하지만
일부러 CPU를 idle하게 두는 것이
Clairvoyant (투시력이 있는) 알고리즘이에요.
말이 안돼죠?
그니까 미래를 알아야만 Non-preemptive 환경에서 optimal하게 설계할 수 있다는 거죠.
이런 식의 CPU idling을 금지하고,
resource-consuming (resource가 이용 가능하다면 무조건 사용할 것) 상황에선,
EDF가 Optimal algorithm입니다.
즉, 어느 algorithm을 가져와도 EDF보다 좋은 성능을 낼 수 없다는 뜻이죠.
그래서 Non-idle scheduling algorithm에선, NP-EDF가 optimal합니다.
