지식그래프는 여러 개체의 상호작용을 표현하는 그래프이다. 이때 각 노드와 각 edge들은 서로 다른 종류를 가질 수 있다.
예를 들어 A라는 사람이 있고 1월1일 이라는 날짜가 있을 때 이 둘 사이에 생년월일이라는 edge로 연결할 수 있고 또 다른 Student라는 노드가 있으면 A노드와 이 노드를 직업이라는 edge로 연결할 수 있다. 이처럼 실제 세계의 여러 개체들과 그들 간의 관계를 표현한 그래프라고 생각하면 된다.
장점
기본적으로 검색엔진에서 쿼리에 기반하여 질의응답을 할 수 있다.
기존의 구조화되지않은 정보들을 구조화시켜 그래프로 표현하였기에 그래프 분석을 이용해 그 내부에 있는 인사이트를 도출할 수 있다.
단점
실제 텍스트에서 각 노드들의 관계를 모두 찾아내는 것을 어렵다.
또한 자동화 시스템을 이용해 찾아낼 경우 노이즈 및 잘못된 데이터를 가져올 가능성이 높다.
구성요소
지식기반 그래프에서 각 쌍은 총 3가지의 구성요소를 가진다.
Head : 어디에서 출발하는지
Tail : 어디로 도착하는지
Relation : Head가 Tail과 무슨 관계인지
Link Prediction
Head와 Relation이 주어졌을 때 Tail을 찾는 문제이다. 이전에 본 Link Prediction는 일반적으로 서로 다른 두 노드가 연결될지 되지 않을지이고 여기서는 조금 다르게 Relation이 주어지고 그 Relation이 어떤 노드를 가리키는 지를 찾는 문제이다
Knowledge Graph에서는 임베딩을 통해 임베딩 공간에서의 벡터를 이용하여 h,r이 주어졌을 때 t를 예측할 수 있다.
KG Embedding
그래프로 표현되는 (h,r,t) triples를 특정 임베딩 공간 Rn에 매핑시키는 문제이다.
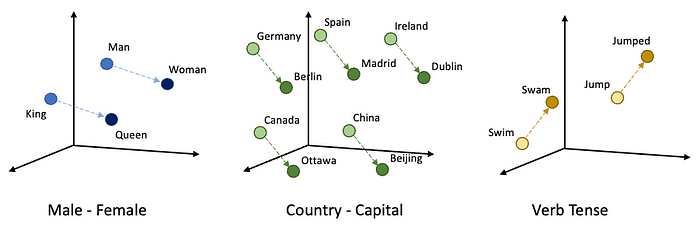
이때 가장 중요한 것은 h+r=t,h′+r=t′ 을 만족시키는 방향으로 임베딩학습이 진행되야한다는 것이다. 즉 head와 tail에 관계없이 같은 특성인 경우 평행을 유지해야한다라는 것이다.
TransE
fr(h,t)=−∥h+r−t∥
TransE에 따르면 실제 사실인 정보에 대해서는 h+r≈t를 만족해야하고 사실이 아닌 정보와는 h+r=t를 만족하도록 학습을 진행하여야한다. 따라서 scoring function은 다음과 같이 정의할 수 있다.
이 규칙으로 학습을 시키게 된다면 위에서 Link Prediction에서 말한 것처럼 h,r만 주어졌을 때 h+r이 해당 지식의 t에 해당하는 노드로 향할 것을 기대할 수 있다.
Algorithm
각 Entity(E)들과 Relation(L)을 모두 Uniform(−k6,k6)을 이용하여 랜덤하게 초기화 시킨다. 이때 k는 dimention이다. 또한 초기화된 값들은 ∥L∥L을 이용하여 정규화 시켜준다.
각 step에서 positive sample과 negative sample을 각각 하나씩 샘플링하여 Tbatch에 추가한다.