pickle
파이썬의 데이터 타입 그대로 파일로 저장하도록 지원
file write 방법
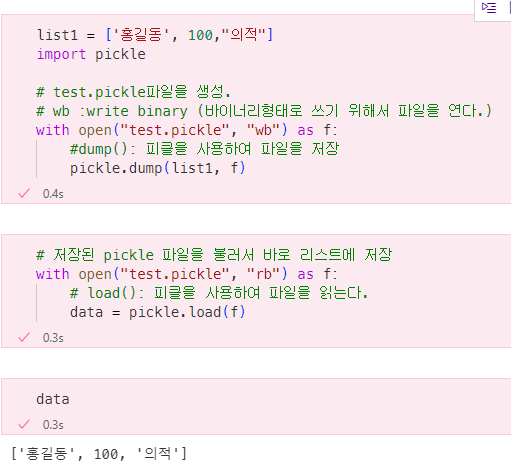
list1 = ['홍길동', 100,"의적"]
import pickle
# test.pickle파일을 생성.
# wb :write binary (바이너리형태로 쓰기 위해서 파일을 연다.)
with open("test.pickle", "wb") as f:
#dump(): 피클을 사용하여 파일을 저장
pickle.dump(list1, f)file read 방법.
# 저장된 pickle 파일을 불러서 바로 리스트에 저장
with open("test.pickle", "rb") as f:
# load(): 피클을 사용하여 파일을 읽는다.
data = pickle.load(f)출력
Dataframe으로 영화리뷰 분석
기본환경

리뷰의 평균 길이는?
import pandas as df
review_df = df.DataFrame(data, columns=['리뷰', '평가'])
#리뷰의 편균 길이
review_df['길이'] = review_df['리뷰'].apply(lambda x: len(x))
review_df['길이'].mean()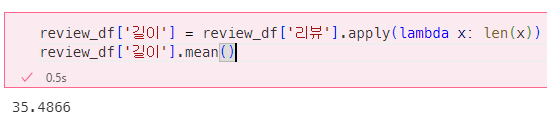
부정(0), 긍정(1) 댓글의 수를 출력
#블리언 인덱싱
긍정 = review_df['평가'] == 1
부정 = review_df['평가'] == 0
print("긍정:",len(review_df[긍정]))
print("부정:",len(review_df[부정]))
사용자가 입력한 단어가 댓글에 몇 개나 있는지 출력
search_str = input()
def get_cnt_varb(t_str):
return t_str.count(search_str)
review_df['단어수'] = review_df['리뷰'].apply(get_cnt_varb)
print("검색단어 :", search_str)
print("각 단어수 :", review_df['단어수'])
print("총 단어수 :", review_df['단어수'].sum())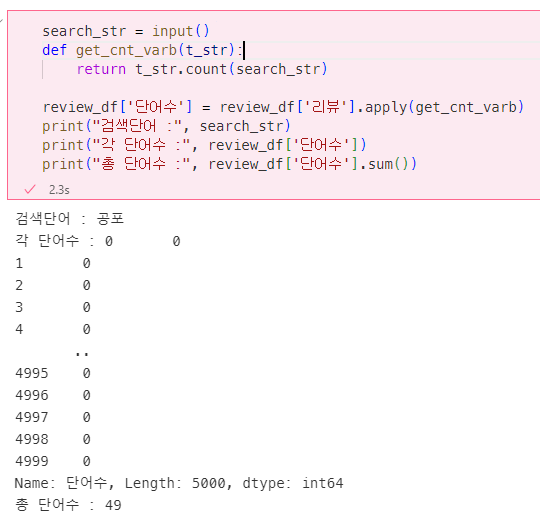

Have a good one!