Seleninum 라이브러리
- 웹 페이지를 제어 할 때
- 동적인 웹 페이지에서 데이터를 수집할 때
환경구축
- !pip install selenium 설치
- chrome webdriver
➡️ 여기에서 다운로드 https://chromedriver.chromium.org/
설치된 Chrome과 동일한 버전으로 다운 받는다.
내 Chrome정보 보는법
Chrome 점 세개 -> 도움말 -> 정보
# chromedriver.exe 파일을 실행할때 사용하는 라이브러리
from selenium import webdriver as wb
# 브라우저 객체 생성.
driver = wb.Chrome('./chromedriver.exe')
# 브라우저 실행
driver.get('https://www.naver.com')위의 코드를 실행하면 크롬이 켜진다.
Seleninum으로 네이버에서 검색
find_element() 을 통해 검색
find_element()는 ID검색을 통해 접근하게 도와준다.
(But, ID만 검색이 된다.)
개발자모드를 통해 검색창의 input id를 찾아본다.
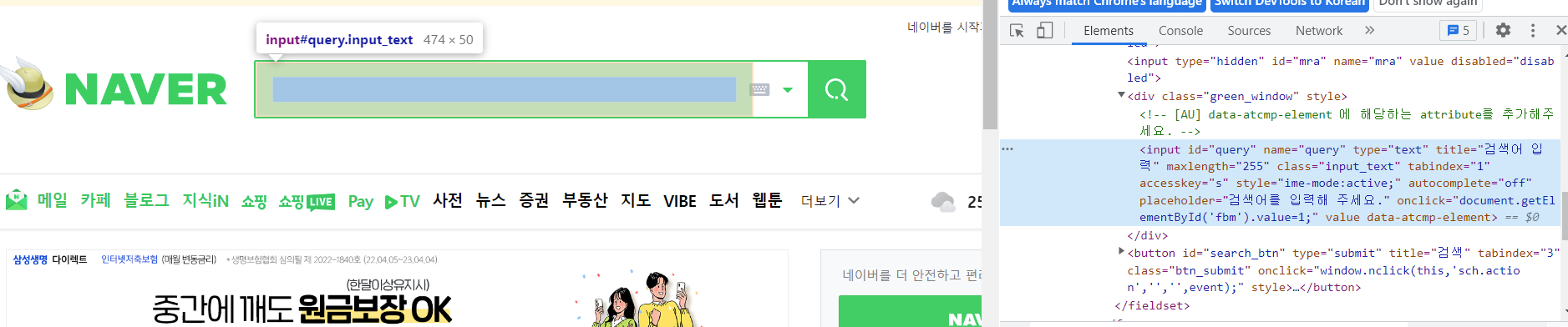
확인해 보니 input id가 query이다.
아래의 코드를 추가로 실행한다.
HTML요소중에 id가 query인 항목을 찾아서, 해당 부분에 키보드를 입력시킨다.
# HTML 요소 접근
driver.find_element(by='id', value='query').send_keys('장마\n')'\n' 은 엔터키가 입력된다.
검색 버튼까지 자동으로 눌러서 검색
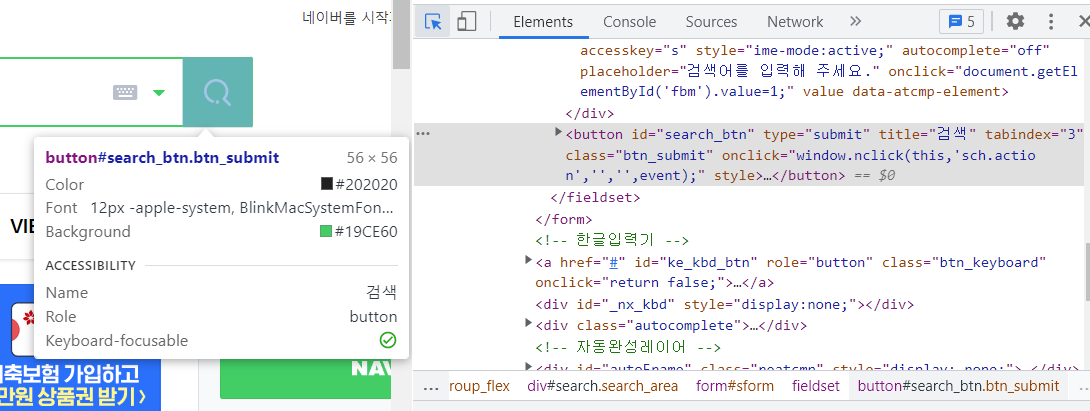
개발자모드를 통해 검색 버튼의 속성을 찾아본다.
id가 search_btn임을 확인한다.
아래와 같이 코드를 해보자
# HTML 요소 접근
driver.find_element(by='id', value='query').send_keys('장마')
# 검색버튼 찾기
driver.find_element(by='id', value='search_btn').click()By를 통해 검색
#다양한 방법으로 HTML요소 접근도와주는 라이브러리
from selenium.webdriver.common.by import By
# HTML 요소 접근
driver.find_element(By.CSS_SELECTOR, value='#query').send_keys('장마')
# 검색버튼 찾기
driver.find_element(By.ID, value='search_btn').click()
By.CSS_SELECTOR는 css_selector를 검색하는 것이므로 value앞에 꼭#이 붙어야 한다.
By.ID는 기존의 ID검색과 같으므로 value를 그대로 사용하면 된다.
다양한 Site에서 검색.
구글검색페이지에서 검색어 입력 후 결과페이지가 출력되도록 구현해 보기!
개발자 모드로 확인 결과, 검색 input식별자는 gLFyf.gsfi이다.

검색버튼을 검사해보니, Class로 너무 복잡하게 되어 있다.
이럴 경우 XPATH로 하면 좋다.
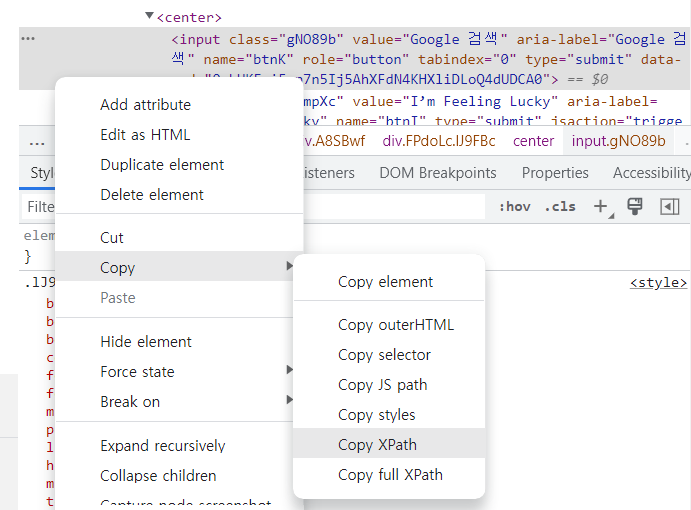
코드는 다음과 같다.
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
driver = wb.Chrome('./chromedriver.exe')
driver.get('https://www.google.com')
driver.find_element(By.CLASS_NAME, value='gLFyf.gsfi').send_keys('장마')
driver.find_element(By.XPATH, value='/html/body/div[1]/div[3]/form/div[1]/div[1]/div[3]/center/input[1]').click()Gmarket에서 Bestseller Page에서 상품과 가격을 가져오기
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
import time
import pandas as pd
gm_url = 'http://corners.gmarket.co.kr/Bestsellers'
driver = wb.Chrome()
driver.get(gm_url)
itemNms = driver.find_elements(By.CLASS_NAME, value='itemname')
itemPrices = driver.find_elements(By.CSS_SELECTOR, value='div.s-price > strong > span > span')
itemNms_list = []
itemPrice_list = []
for idx in range(len(itemNms)):
itemNms_list.append(itemNms[idx].text)
itemPrice_list.append(itemPrices[idx].text)
item_dic = {"상품명":itemNms_list,
"가격" : itemPrice_list}
item_df = pd.DataFrame(item_dic)
item_df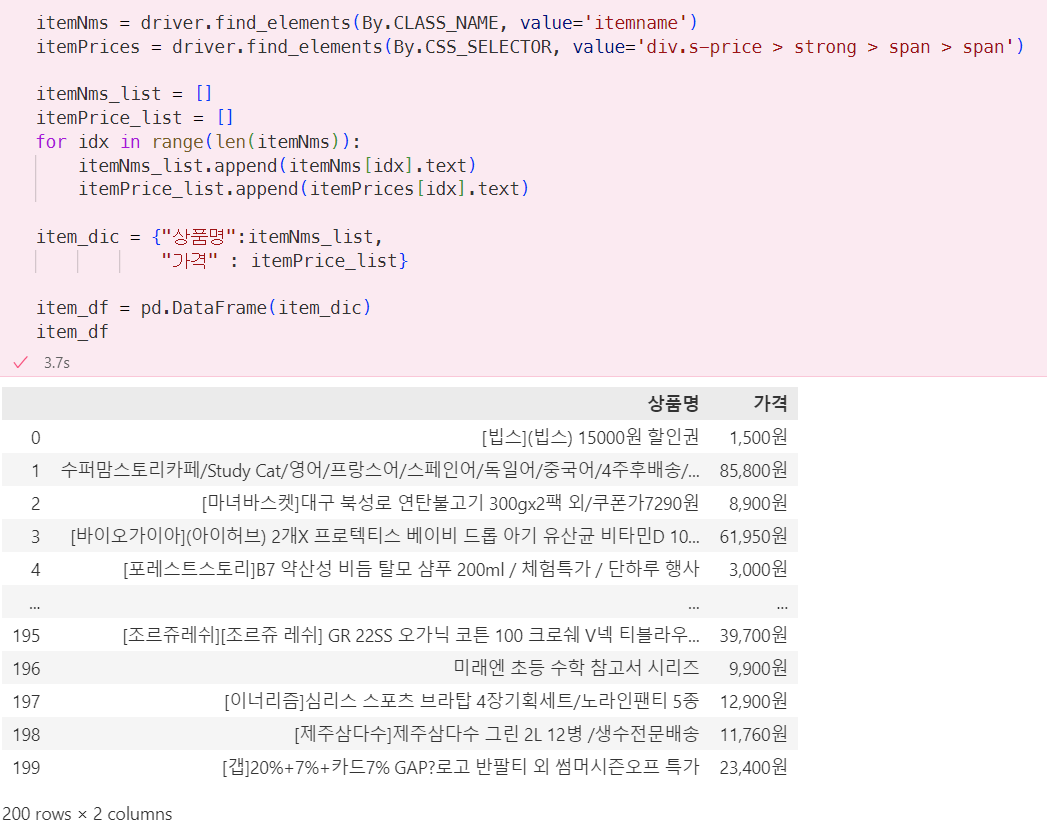
Gmarket에서 Bestseller Page에서 상품과 가격을 가져오기2 - 카테고리별 모든 데이터 가져오기
개발자모드로 카테고리를 확인해보면, id categoryTabG 내부에 li tag로 둘러 쌓여 있다. 이에 CSS_SELECTOR에서 #categoryTabG > li 을 통해 검색하면 된다.
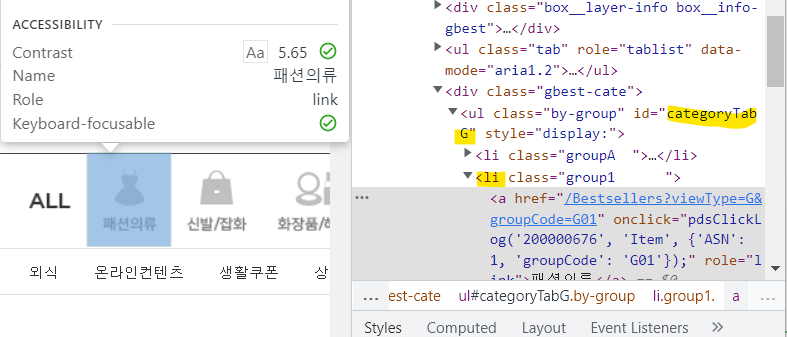
from tqdm.notebook import tqdm as tn
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
import time
import pandas as pd
gm_url = 'http://corners.gmarket.co.kr/Bestsellers'
driver = wb.Chrome()
driver.get(gm_url)
################ 여기서 부터 코드 ################
itemNms_list = []
itemPrice_list = []
tagNames_list = []
def collect_items(driver, tagName):
itemNms = driver.find_elements(By.CLASS_NAME, value='itemname')
itemPrices = driver.find_elements(By.CSS_SELECTOR, value='div.s-price > strong > span > span')
for idx in range(len(itemNms)):
itemNms_list.append(itemNms[idx].text)
itemPrice_list.append(itemPrices[idx].text)
tagNames_list.append(tagName)
tabs = driver.find_elements(By.CSS_SELECTOR, value='#categoryTabG > li')
for i in tn(range(1, len(tabs))):
tabs = driver.find_elements(By.CSS_SELECTOR, value='#categoryTabG > li')
tagName = tabs[i].text
tabs[i].click()
time.sleep(0.5)
####################################
collect_items(driver, tagName)수집된 3개의 list는 (itemNms_list, itemPrice_list, tagNames_list) dataframe으로 만들면, 아래와 같은 결과를 얻을 수 있다.
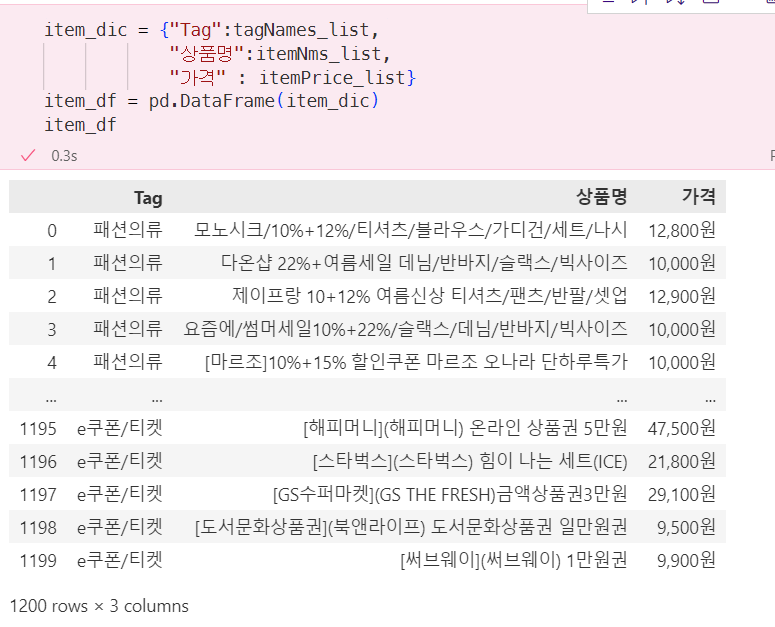
이미지 수집하기
환경 설정
# 이미지 주소를 이용하여 이미지파일로 저장할때 필요한 라이브러리
from urllib.request import urlretrieve이미지 처리
이미지 저장하기
# urlretrieve(이미지주소, 파일이름경로)
img_url = 'https://cdnimg.melon.co.kr/cm2/artistcrop/images/002/61/143/261143_20210325180240_500.jpg'
file_Nm = './test.jpg'
# 이미지 파일 저장.
urlretrieve(img_url, file_Nm)