이미지 수집하기 계속
네이버에서 이미지 수집하기
아이유 사진 수집하기
image_list 라는 list에 image를 저장해 둔다.
from urllib.request import urlretrieve
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
keyword = '아이유'
naver_search_url = f'https://search.naver.com/search.naver?where=image&sm=tab_jum&query={keyword}'
driver = wb.Chrome()
driver.get(naver_search_url)
from tqdm.notebook import tqdm as tn
from IPython.display import Image
images = driver.find_elements(By.CSS_SELECTOR, value='div > div.thumb > a > img')
image_list= []
image_url_list = []
# for i in tn(range(len(images))): --> 이건 수가 너무 많다.
for i in tn(range(10)):
img_url = images[i].get_attribute('src')
if 'data:' in img_url: continue
image_url_list.append(img_url)
image_list.append(Image(img_url[:img_url.find('&type=')]))input받은 이름을 검색하여 나온 사진을 파일로 저장해 보자
from urllib.request import urlretrieve
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
import os
keyword = input("검색할 이미지 이름 : >")
naver_search_url = f'https://search.naver.com/search.naver?where=image&sm=tab_jum&query={keyword}'
driver = wb.Chrome()
driver.get(naver_search_url)
time.sleep(1)
from tqdm.notebook import tqdm as tn
from IPython.display import Image
images = driver.find_elements(By.CSS_SELECTOR, value='div > div.thumb > a > img')
image_url_list = []
for i in tn(range(10)):
img_url = images[i].get_attribute('src')
if 'data:' in img_url: continue
image_url_list.append(img_url)
# image_list.append(Image(img_url[:img_url.find('&type=')]))
if not os.path.isdir('이미지'):
print('폴더생성')
os.mkdir('이미지')
for idx, src_url in tn(enumerate(image_url_list, 1)):
fileNm = f'./이미지/{keyword}_{idx}.jpg'
urlretrieve(src_url, fileNm)
time.sleep(0.5)셀레니움 (selenium) 으로 open된 브라우저 종료
driver.close()
셀레니움(selenium) 추가 기능 알아보기
키보드 특수키 넣기
#키보드의 값을 활용할 수 있는 라이브러리(e)
from selenium.webdriver.common.keys import Keys
keyword = '강아지'
keyword = input("검색할 이미지 이름 : >")
naver_search_url = f'https://search.naver.com/search.naver?where=image&sm=tab_jum&query={keyword}'
driver = wb.Chrome()
driver.get(naver_search_url)
time.sleep(1)
##### 특수키 넣는 부분!!
# pagedown 키 넣기
driver.find_element(By.TAG_NAME, value='body').send_keys(Keys.PAGE_DOWN)
# END 키 넣기
for i in range(5):
driver.find_element(By.TAG_NAME, value='body').send_keys(Keys.END)
time.sleep(2)유튜브 영상 정보 수집하기
목표
- 영상 url, 영상제목, 조회수
- 데이터프레이으로 만들기
환경세팅
사용할 유튜브 채널 : 고양이 산책 - https://www.youtube.com/c/%EA%B3%A0%EC%96%91%EC%9D%B4%EC%82%B0%EC%B1%85/videos
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
yt_url = 'https://www.youtube.com/c/%EA%B3%A0%EC%96%91%EC%9D%B4%EC%82%B0%EC%B1%85/videos'
driver = wb.Chrome()
driver.get(yt_url)
time.sleep(1)유튜브 채널 정보 분석하기
우선 개발자 모드로 영상제목을 살펴보면, 우리가 필요한 모든 정보가 저장되어 있음을 확인할 수 있다.
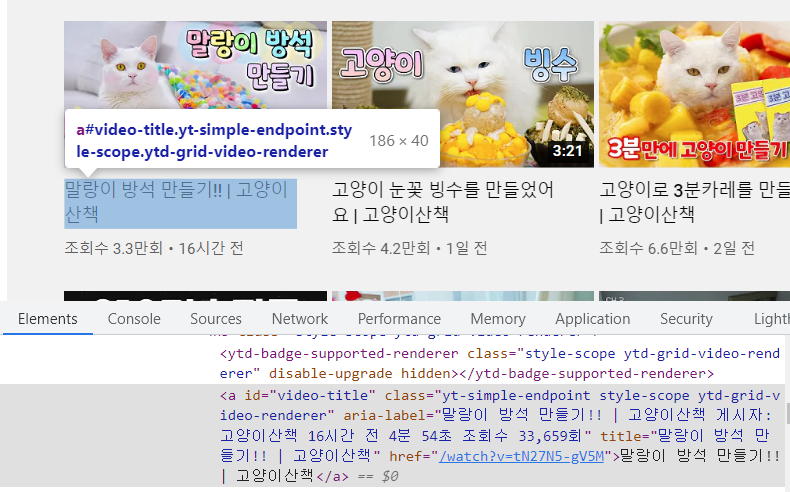
영상정보 1개만 가져와서 분석하기
By.CSS_SELECTOR 를 이용해서 원하는 Data를 1개만 가져와서 Test해보자
물론
By.ID를 써도 되는데, 그냥By.CSS_SELECTOR를 써봤다.
#video-title
video_info_list = driver.find_elements(By.CSS_SELECTOR, value='#video-title')
sample1 = video_info_list[1]
print('title',sample1.text)
print('조회수',sample1.get_attribute('aria-label')[sample1.get_attribute('aria-label').find('조회수')+3:])
print('URL', sample1.get_attribute('href'))결과
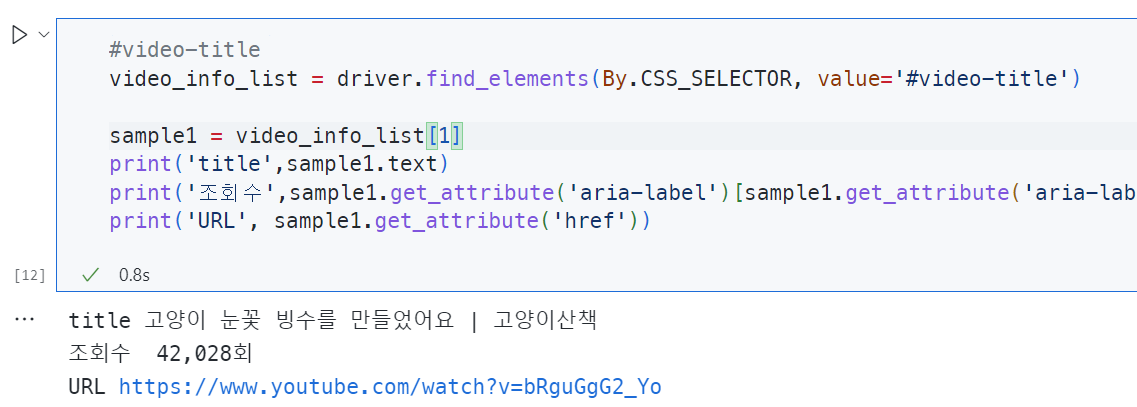
영상정보 가져와서 DataFrame에 저장하기
결과가 잘 나오므로, for문을 통해 Data를 모두모두 가져온다.
#video-title
video_info_list = driver.find_elements(By.CSS_SELECTOR, value='#video-title')
title_list=[]
count_list=[]
yt_url_list=[]
for video_info in video_info_list:
title_list.append(video_info.text[:video_info.text.find('|')])
count_tmp = video_info.get_attribute('aria-label')[video_info.get_attribute('aria-label').find('조회수')+3:]
count_tmp = count_tmp[:count_tmp.find('회')]
count_list.append(count_tmp)
yt_url_list.append(video_info.get_attribute('href'))
video_info_dic = {
"영상제목" : title_list,
"영상조회수" : count_list,
"영상주소" : yt_url_list
}
video_info_df = pd.DataFrame(video_info_dic)
video_info_df실행결과

네이버 지도에서 맛집정보 수집
수업시간 관계상, 목표 코드만 남음..
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
map_url = 'https://map.naver.com/v5/?c=14140822.8653826,4508397.7630627,15,0,0,0,dh'
driver = wb.Chrome()
driver.get(map_url)
time.sleep(2)
# 지도 검색어 입력하기
driver.find_element(By.CSS_SELECTOR, value='input.input_search').send_keys('중국집\n')
time.sleep(1)
# 검색결과 창 전환
driver.switch_to.frame('searchIframe')
# 검색결과 중 가게하나를 클릭
stores = driver.find_elements(By.CSS_SELECTOR, value='span.place_bluelink.OXiLu')
time.sleep(1)
for store in stores:
store.click()
time.sleep(1)
# 이전페이지 창 전환
driver.switch_to.default_content()
# 상세페이지 창 전환
driver.switch_to.frame('entryIframe')
try:
# 상세페이지에 있는 가게정보 수집
storeNm = driver.find_element(By.CSS_SELECTOR, value='span._3XamX').text
except:
storeNm = ''
print('가게명:', storeNm)
# 이전페이지 창 전환
driver.switch_to.default_content()
# 검색결과 창 전환
driver.switch_to.frame('searchIframe')
time.sleep(1)
driver.close()
Have a good one!