[논문 리뷰] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
추천시스템 논문 리뷰
이번에 선택한 논문의 경우, 입사 후 업무를 위해 처음으로 접한 논문이었다. Alibaba의 연구진 Fei Sun, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, Peng Jiang이 작성한 논문 "BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer"은 2019년 ACM에서 발표되었다. 본 논문은 현재까지도 Sequential Recommendation 분야에서 좋은 성능을 보이고 있다.
Introduction
Related Works
General Recommendation
추천시스템은 크게 두 가지, 협업 필터링(Collaborative Filtering)과 콘텐츠 기반 필터링(Content-Based Filtering)으로 나눌 수 있다. 협업 필터링은 사용자와 아이템의 상호작용을 활용하는 추천시스템이다. 콘텐츠 기반 필터링은 해당 아이템의 도메인을 활용하여 유저가 관심있는 아이템의 속성을 분석하여 새로운 아이템을 추천해주는 모형이다. 최근에는 위의 모형들에 딥러닝과 결합된 모델이 제안되기도 하였다. MLP를 접목한 Neural Collaborative Filtering(NCF), Auto-encoder 프레임워크를 활용한 AutoRec 등이 있다.
Sequential Recommendation
RNN 계열 모델은 유저의 이용 및 구매 이력을 기반으로 한 Sequential Recommendation을 위해 등장하였다. 이를 통해 유저의 sequential history를 학습하여 그 다음에 일어날 행동에 대해 예측할 수 있게 되었다. 하지만, RNN 계열 모델은 left-to-right, 단방향 모델 구조로 고객의 시간 순서를 가정함으로써 유저의 숨겨진 의도를 놓칠 수 있다. 또한 유저의 과거 상호작용에서 아이템 선택은 정해진 순서를 따르지 않는 경우가 많다.
Attention Mechanism
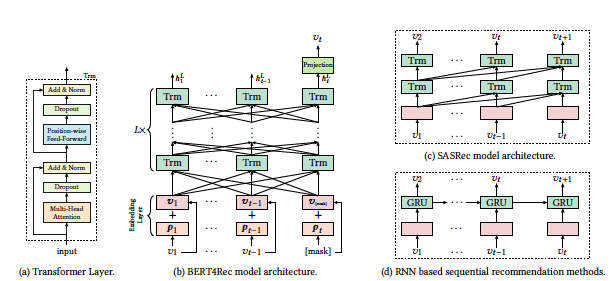
Text sequence 과제에서 transformer 계열의 모델들이 두각을 보이면서 sequential recommendation에 대한 연구가 본격적으로 이루어지기 시작하였다. Attention 메커니즘을 구현한 것으로 각 단어의 벡터끼리 서로 간의 관계가 얼마나 중요한지 점수화 즉, 각 단어들이 주변 단어와 어떤 연관성이 있는지에 집중한다. Attention 메커니을 추천에서 활용하게 되면 은 각각의 행동이 서로 어떤 영향을 미치는지 행동 사이의 관계를 추론하여 고객의 행동을 예측을 가능하게끔 한다. Attention 메커니즘을 활용한 모델로 SASRec이 있다. 이 모형은 Left-to-Right 구조로 BERT4Rec과 구조가 유사하나, SASRec은 다음 단어를 예측하는 방식으로 훈련하고 BERT4Rec은 마스킹된 단어를 예측하는 방식으로 훈련하게 된다. SASRec은 각 타임 step에 따른 loss를 모두 계산해야 하여 계산량이 많다는 단점이 있다. 또한 를 예측할 때는 이전에 등장한 만 참고할 수 있고 미래의 v(t)를 참고할 수 없다는 단방향성이 단점으로 작용한다.
BERT4Rec
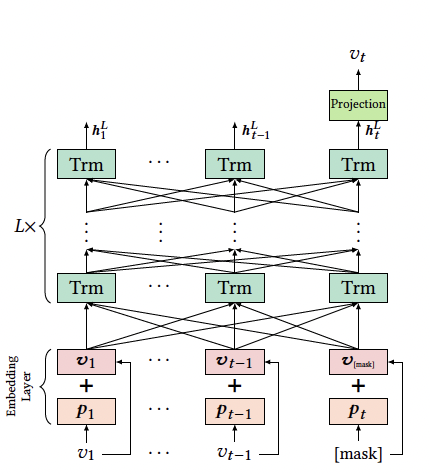
Problem Statement
Sequential recommendation에서는 유저-상품의 이력을 기반으로 유저가 다음 상품을 선택할 확률을 최대화하는 것을 목표로 한다.
Model Architecture
BERT4Rec의 경우, 이름에서 알 수 있듯이 BERT 모델을 차용하고 있다. BERT 모델이 그렇듯 L개의 양방향 transformer의 encoder layer가 쌓여서 만들어진다. 각 layer의 경우, 이전 layer의 모든 position에 대한 정보들을 상호 교환하여 모든 position의 representation을 수정하며 학습을 진행하게 된다.
Transformer Layer
BERT4Rec의 transformer layer는 multi-head attention과 position-wise feed forward 두 가지의 sub-layer로 구성되어 있다.
Multi-Head Self-Attention
Self-attention 메커니즘을 통해 거리 제약 없이 representation pair 사이의 dependency를 포착할 수 있다. 이러한 self-attention 메커니즘을 병렬적으로 활용하는 multi-head self-attention을 통해, 이전 layer에 존재하는 모든 position에 대한 정보들을 상호 교환하여 모든 position representation을 수정하면서 학습을 수행한다. 이를 통해 여러 transformer layer, Trm을 jointly하게 고려할 수 있게 된다.
Position-wise Feed Forward
Self-attention의 sub-layer는 대부분 linear projection을 기반으로 한다. Position-wise Feed Forward(PFFN)은 여러 dimension 사이의 상호작용을 포착하고 비선형성을 강화해준다. 일반적인 경우 activation function으로 ReLU를 쓰는 것과 달리 성능 면에서 GELU가 더 뛰어났기에 GELU가 활용되었다.
Stacking Transformer Layer
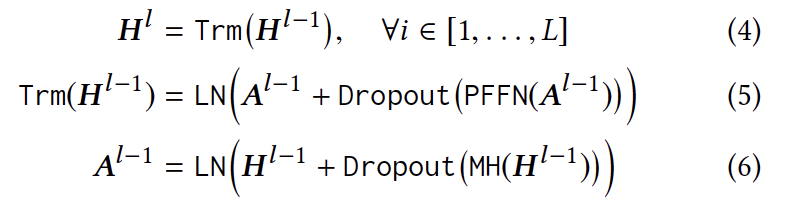
Self-attention 메커니즘을 통해 전체 유저의 행동 sequence에서 아이템 간의 상호작용을 쉽게 추출할 수 있다. 그러나, self-attention layer을 여러 개 쌓는 과정을 통해 복잡한 item transition pattern을 학습할 수 있게 된다. 이 방식의 경우 gradient vanishing이 생겨 학습하기에 어렵다는 단점도 함께 가지고 있는데 이를 방지하고자 (a)그림의 residual connection을 활용한다. sub layer을 dropout시키고 residual connection 산출물에 대해 layer normalization을 적용한다.
Model Training
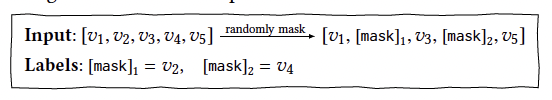
기존의 단방향 네트워크의 경우에는 이전 아이템들을 기반으로 다음 아이템을 추론하는 방식으로 학습을 진행하였다. BERT4Rec은 Cloze Task 방식을 활용하는데 이는 랜덤하게 p%의 마스킹한 아이템을 추측하는 방식으로 학습을 진행하게 된다. 이 방식의 경우에는 기존 방식에 비하여 모델을 훈련하기 위한 많은 샘플을 확보할 수 있다. 기존의 방식은 같은 문장을 학습할 때 개의 샘플을 얻을 수 있다면, Cloze Task 방식은 개의 샘플을 얻을 수 있다. 따라서 같은 양의 데이터로부터 더 효과적으로 학습할 수 있다.
하지만, 이와 같은 방식의 경우, data leakage가 발생할 수 있어 validation과 test set의 경우, 각각 input의 마지막 전 token과, 마지막 token을 mask 처리하여 수행한다. 이는 Leave-one-out evaluation 기법으로도 불린다.
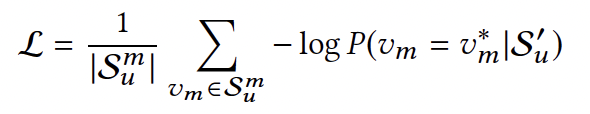
Loss 함수는 위 형태의 negative log-likehlihood loss이다. 는 masked token을 포함한 sequence를 의미하는데 가 주어졌을 때 = 일 확률을 계산하는 것이다. -log를 씌워, 낮을수록 좋은 negative log-likelihood loss로 변환하였다. 즉, negative log-likelihood loss를 최소화하는 방향으로 학습을 진행한다.
Experiments
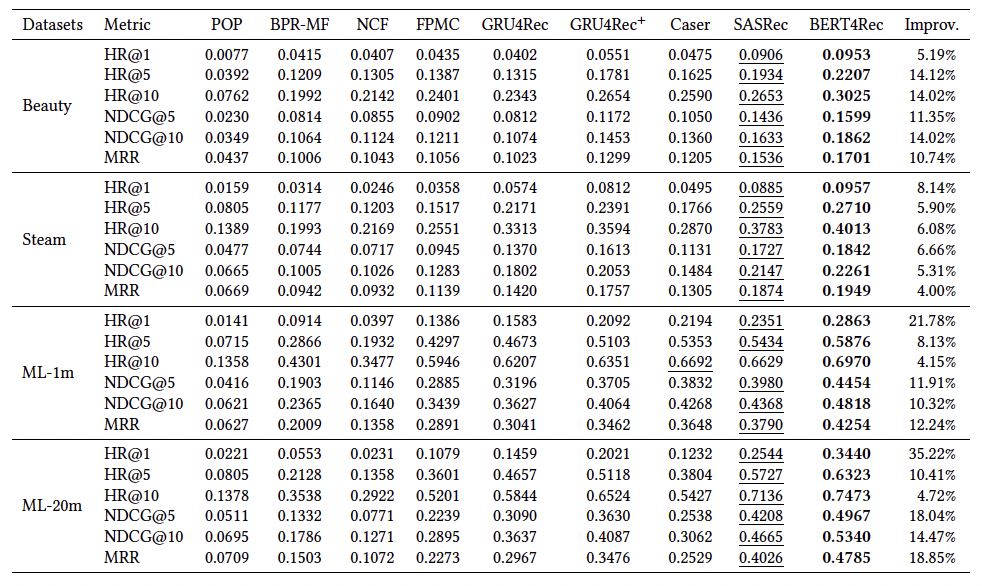
본 논문에서는, Amazon Beauty, Steam, MovieLens(ML-1m, ML-20m) 데이터셋을 활용하여 타 모델과 비교하는 실험을 진행하였다. 각 데이터셋은 숫자화된 평점이나 리뷰의 존재를 암시적 피드백으로 간주하여 전처리 하였고 시간 흐름에 따라 고객 별 로그를 배열하였다. 데이터 품질을 위하여 5건 이상의 레코드가 있는 유저의 데이터만을 활용하였다. Sequential Recommendation 모델의 성능을 측정하기 위하여 leave-one-out 전략을 사용하였고, metrics로는 Normalized Discounted Cumulative Gain(NDCG), Hit Ratio(HR), Mean Reciprocal Rank(MRR)을 사용하였다. 대표적인 추천의 모델들인 POP, BPR-MF, NCF, FPMC, GRU4Rec, GRU4Rec, Caser, SASRec과 BERT4Rec의 성능을 비교하였다. 위의 표를 보면 모든 데이터셋에서 좋은 성능을 나타냈다.
BERT4Rec 코드
https://github.com/FeiSun/BERT4Rec
