tl;dr
2021년 6월 2일에 arXiv에 등록된 논문이다. 강화 학습 문제를 conditional sequence modeling으로 해석하고 transformer 모델로 학습하는 시도를 했다.
선행 지식
- Offline reinforcement learning
- Transformers
배경
Temporal difference (TD) learning과 같은 알고리즘 대신 transformer 모델을 사용하여 collected experience를 학습하자는 아이디어에서 출발했다.
Rewards를 천천히 propagate 하고 "distractor" signals로 가기 쉬운 Bellman backups와 반대로, transformer는 self-attention을 통해 직접적으로 credit assignment를 수행한다.
이는 transformers가 sparse rewards나 distracting rewards의 존재에도 여전히 효과적으로 작동하도록 한다.
이 논문에서는 offline RL을 고려함으로써 이러한 가정을 살펴본다.
방법
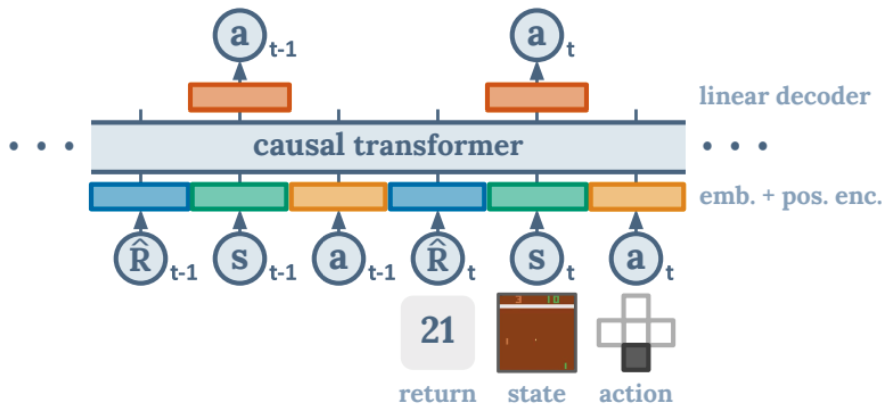
Trajectory Representation
Autoregressive training and generation을 위해 다음과 같은 trajectory representation을 사용한다.
이때, 우리는 future rewards에 관심이 있기 때문에 returns-to-go 를 사용하며, 이다.
Architecture
마지막 K timesteps, 총 3K 개의 token(return-to-go, state, action)을 Decision Transformer에 입력한다.
Token embeddings를 얻기 위하여, 각 modality(여기서는 토큰 종류)에 대하여 raw inputs를 embedding dimension으로 만드는 linear layer를 학습하고, layer normalization을 한다.
Visual inputs를 가진 environment들에 대하여 state를 linear layer 대신 convolutional encoder에 넣는다.
그리고 각 timestep에 대한 embedding이 학습되며, 각 token에 더해진다.
그런 다음 GPT 모델은 token을 처리하고, autoregressive modeling을 통해 future action tokens를 예측한다.
Training
주어진 offline trajectory들의 데이터셋에서 길이 K의 미니배치들을 추출한다.
Input token 에 해당하는 prediction head는 를 예측하기 위하여, discrete actions에 대하여 cross-entropy loss, continuous actions에 대하여 mean-squared error를 사용하여 training 된다. 그리고 각 timestep에 대한 loss들은 averaged 된다.
이 논문에서는 states나 returns-to-go를 예측하는 것이 성능 향상을 가져온다는 것을 관찰하지 않았다. 이것은 이 framework에서 쉽게 할 수 있으며 future work로 남겨둔다고 한다.
수도코드는 논문을 참고하길 바란다.
결과
- Decision Transformer와 TD learning (CQL)과 behavior cloning을 비교한 결과
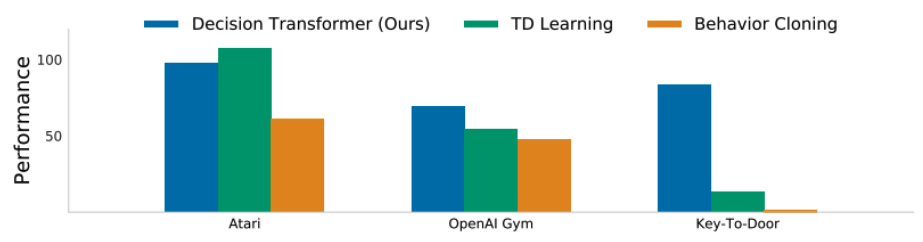
위 실험에서 Performance는 normalized episode return으로 측정되었다.
자세한 실험 내용은 논문을 통해 확인하는 것이 좋을 것 같다.
참고
