
이번 강의는 노드 임베딩(Node Embedding) 에 대해 이야기할 예정입니다.
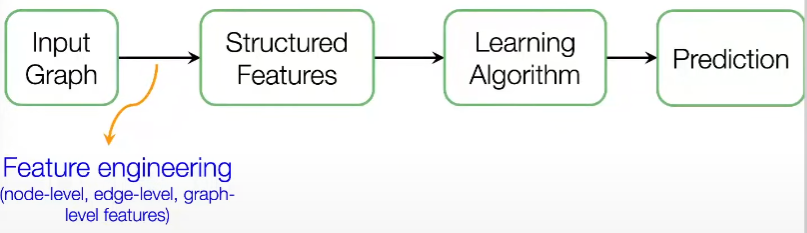
지난 주 강의는 그래프의 전통적인 기계 학습에 대해 학습하였습니다. 여기서 아이디어는 입력 그래프가 주어지면, 토폴로지 구조를 설명하는 노드/링크/그래프 수준 기능을 추출한다는 것입니다.
아래 이미지와 같이 입력 그래프가 주어지면 노드, 링크 및 그래프 수준의 특징을 추출하고, 특징 Label에 매핑하는 모델(SVM, neural network)을 학습합니다.
그러나 이 작업 대신, 그래프 표현 학습은 Feature engineering이 필요 없이, 자동적으로 특징을 학습합니다.
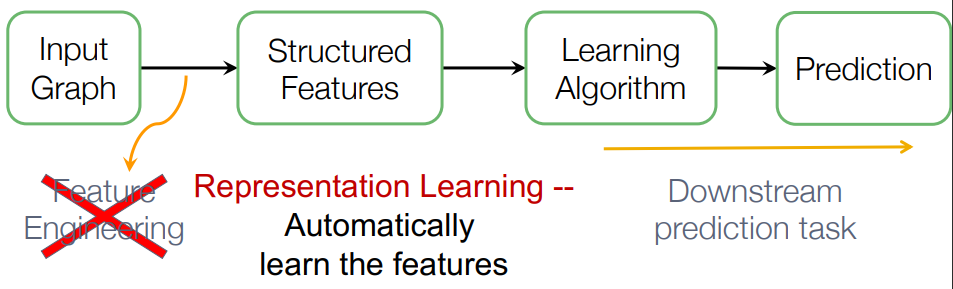
Graph Representation Learning
그렇다면, 그래프 표현 학습은 무엇일까요? 그래프 표현 학습은 기존의 머신러닝 방법과는 다르게, 노드를 임베딩 공간으로 매핑하여 그래프 내의 노드의 유사성이 임베딩 간의 거리에 반영되도록 합니다. 이 방법은 노드 임베딩 알고리즘의 주요 구성 요소인 인코더와 디코더를 도입하며, 유사성 함수를 어떻게 정의할지에 대해서도 설명합니다.
그래프 표현 학습의 목표는 임베딩 공간에서의 유사성이 그래프의 유사성에 근접하도록 아래 이미지와 같이 노드를 인코딩하는 것입니다.
아래 슬라이드에서는 노드를 차원 공간에 매핑, 그리고 의 벡터로 표현하였네요.
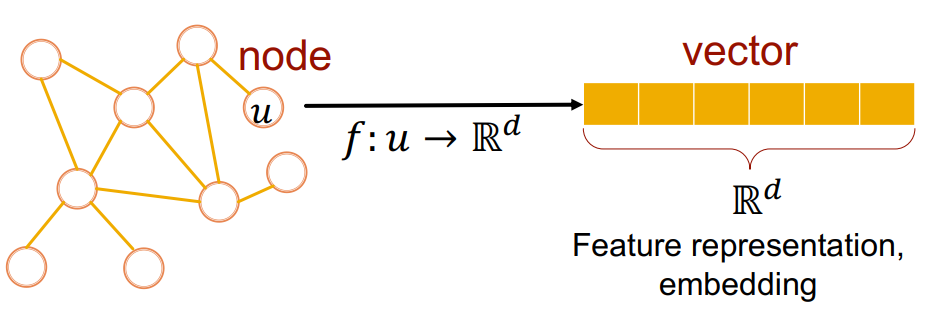
이를 위해 인코더는 노드를 임베딩으로 매핑하고, 노드 유사성 함수를 정의합니다. 그 후, 인코더의 매개변수를 최적화합니다.
Why Embedding?
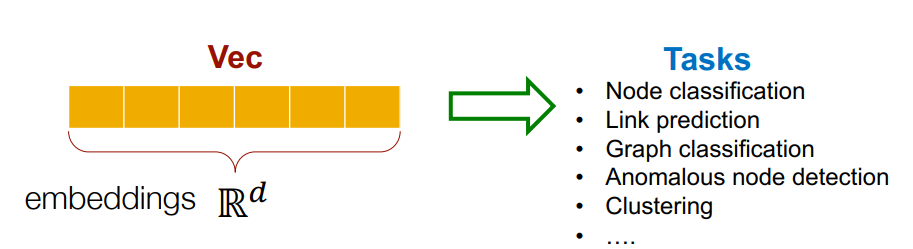
그럼 왜 노드를 임베딩하는 것일까요? 우선, 노드 간 임베딩의 유사성은 네트워크에서의 유사성을 나타냅니다. 예를 들어, 네트워크에서 서로 가까운 node가 있다면, 임베딩(벡터) 공간에서 서로 가깝게 인코딩 될 것입니다. 이렇게 노드를 인코딩(임베딩) 하는 것은 노드 분류, 링크 예측 등 다양한 작업을 위해 선행됩니다.
Example Node Embedding
아래는 간단한 그래프 구조인데요. 현실 그래프 데이터는 이렇게 간단하지 않지만, 좋은 임베딩 예시라고 생각합니다.
> 2D embedding of nodes of the Zachary's Karate Club network
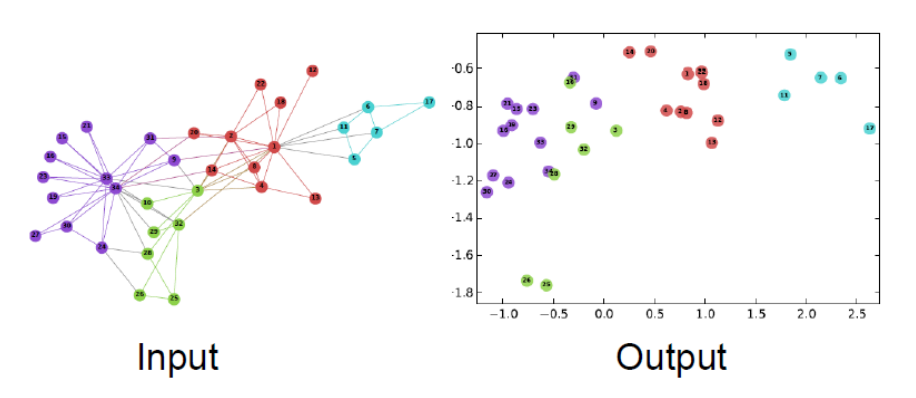
Embedding Nodes
그래서 우리는 노드 임베딩을 하기 위한 작업을 진행할 것입니다. 그렇다면, 인접 행렬의 관점에서 생각해야 합니다.
목표는 임베딩된 공간의 유사성이 그래프의 유사성에 가까워지도록 노드를 인코딩하는 것입니다. 아래 이미지가 대표적인 예시가 되겠네요.
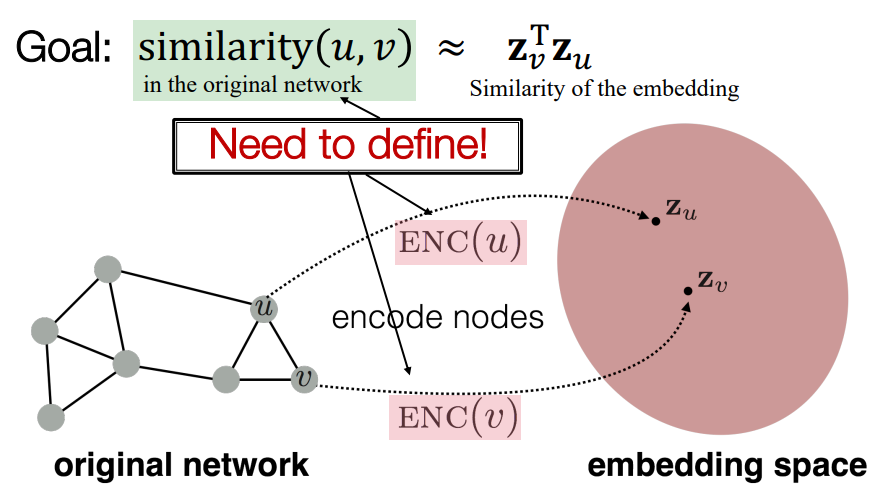
이는 의 수식으로 표현됩니다. 임베딩 공간의 유사성 측정 기준으로는 내적(dot)을 활용합니다. 내적은 단순히 두 벡터의 각도를 나타내죠.
정리하자면, 원래 네트워크에서 유사성 개념을 정의하고 유사성을 임베딩과 연결할 목적 함수를 정의해야 합니다.
Learning Node Embedding: Summary
그렇다면, 우리가 할 내용을 요약 및 정리해 보겠습니다.
- 인코더는 노드를 임베딩에 매핑합니다. 네트워크 유사성을 측정하는 노드 유사성 함수를 정의해야 합니다.
- 디코더는 임베딩을 유사성 점수로 매핑합니다.
- 디코딩된 유사성이 네트워크 유사성의 기본 정의에 최대한 가깝게 일치하도록 매개변수를 최적화할 수 있습니다.
- 여기서는 매우 간단한 디코더인 내적(dot-product)을 예시로 사용하였습니다.
Two Key Components
- Encoder: 인코더는 각 노드를 수식을 통해, 저차원 벡터로 매핑합니다.
따라서, 특정 노드의 인코더는 단순히 해당 노드의 좌표 또는 임베딩이 됩니다.- 수식을 조금 더 설명하겠습니다. 에서 는 그래프의 각 노드가 됩니다.
- 임베딩 된 는 d차원 공간에 있을 것입니다. 예시로, d는 약 64에서 1,000까지 값을 생각해볼 수 있습니다. 일반적으로 사람들의 얼마나 많은 차원을 선택하는지와 동일한 개념입니다.
- Similarity function: 벡터 공간의 관계가 원래 네트워크의 관계에 어떻게 매핑되는지 지정합니다. 이는 내적으로 유사성을 표현할 수 있습니다.
"Shallow" Encoding
인코딩 접근 방법은 Embedding-lookup 입니다. 이것이 의미하는 바는 인코딩된 특정 노드는 단순히 숫자 벡터라는 것을 의미합니다. 수식으로는 로 표현될 수 있습니다.
내적은 행렬과 깊게 연관이 되어있죠. 우리의 목표는 차원이 인 행렬를 배우는 것입니다. 이는 로, 각 노드의 임베딩 표현식입니다. 우리가 배우고 추정해야 할 내용이죠.
관련하여, 표기법에서, 는 노드의 1열 값(id)를 제외하고는 모두 0을 갖는 indicator 벡터로 생각할 수 있습니다.
더 자세히 설명해 보겠습니다. 아래 그림처럼 기본적으로 는 노드당 하나의 열(column)이 있고, 이 열의 집합을 로 생각할 수 있습니다.
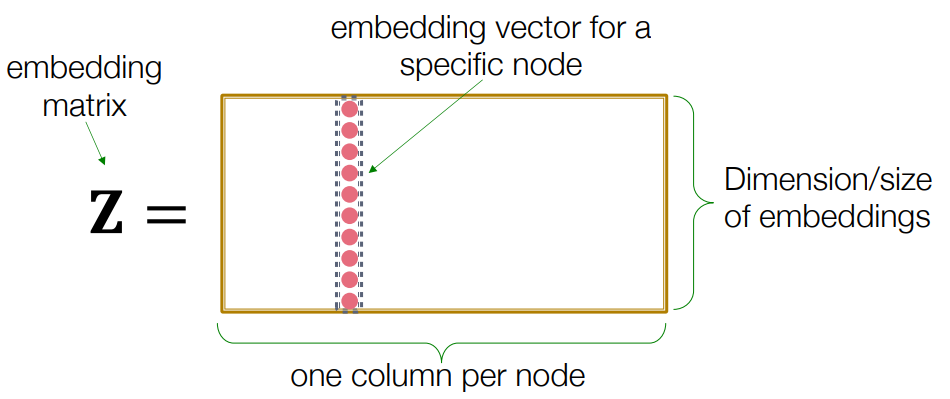
주어진 열은 해당 노드의 임베딩을 저장합니다. 따라서, 행렬의 크기는 노드 수에 임베딩 차원을 곱한 값이 됩니다.
그렇다면 거대한 그래프의 경우, 행렬은 거대해지기 때문에 복잡한 연산을 요구합니다. 따라서, 10억개 이상의 노드를 만들고 싶다면 거대한 차원이 요구되므로 적절한 방법은 아닌 것 같네요. 꼭 10억개가 아니더라도, 수백만개 이후부터는 연산 비용이 높아질 것 같습니다.
그렇다면, 어떻게 해야할까요?
이는 앞서 말했듯이, 각 노드에 고유한 임베딩 벡터가 할당됩니다. 그리고 우리의 목표는 각 노드의 임베딩을 개별적으로 최적화하거나, 학습하는 것입니다. 우리는 이러한 목표를 위해, 다양한 방법을 활용할 수 있으며, 대표적으로 DeepWalk와 node2vec 방법이 있습니다.
Random Walk
우선, 표기법부터 알아보겠습니다.
- Vector : 임베딩된 노드 를 의미합니다.
- Probability : 에서 random walk로 노드를 방문할 확률(예상) 입니다.
- Softmax function: K개의 실제 값의 벡터를 1: 의 확률로 변환합니다.
- Sigmoid function: 실제 값을 (0, 1)로 변경하는 이진(binary)형태의 확률을 나타냅니다.
이제 Random walk를 정의해보겠습니다. 간단히 말하면, 그래프 위의 프로세스라고 합니다.
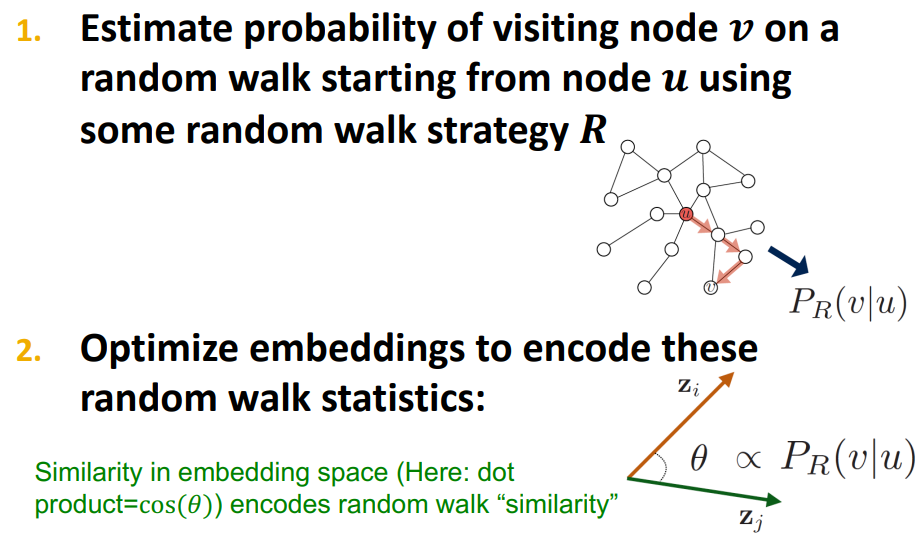
그래프와 시작점이 주어지면 그래프의 이웃을 무작위로 선택하고, 해당 이웃으로 이동한 다음, 이동한 지점의 이웃을 무작위로 선택하고 또 다른 이웃으로 이동합니다. 이런 식으로 방문한 점의 (무작위) 순서를 그래프에서 random walk라고 합니다. 아래 이미지를 참고해주세요.
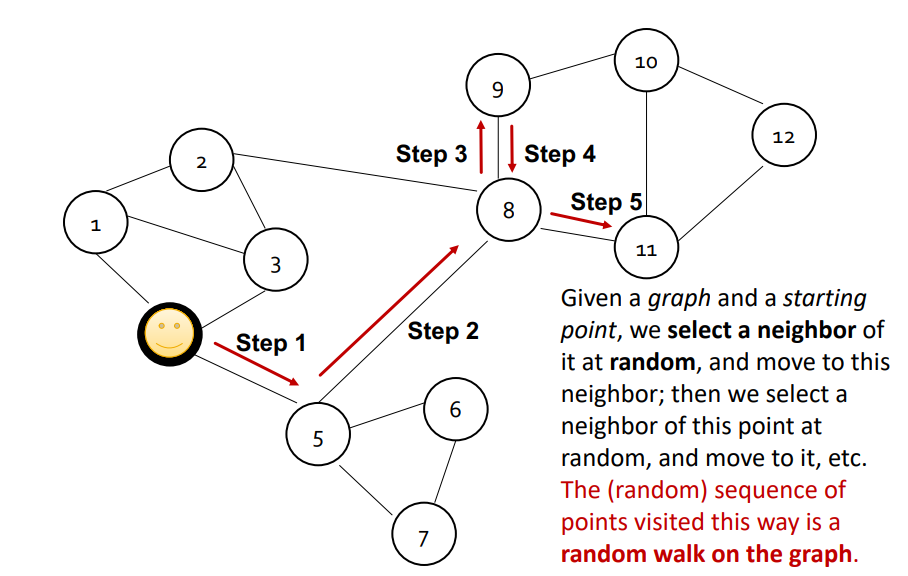
random walk의 전략은 다양하지만, 현재 강의에서는 무작위로 균일하게 하나의 이웃을 선택하고, 그 곳으로 이동하는 단순 확률기반 random walk로 설명했습니다.
자, 돌아가서, 간 내적으로 유사성을 표현할 수 있다고 했습니다. 그렇다면, random walk에서의 확률 통계를 인코딩하는 방식으로 random walk을 최적화할 수 있겠습니다. 인코딩은 두 벡터 사의 각도(cos)을 사용하겠습니다. 즉, 임베딩 공간의 유사성은 random walk '유사성'을 인코딩합니다.
그럼 왜 random walk를 사용할까요? 대표적으로 두 가지 이유가 있는데요, 표현력과 효율성이 훌륭하다고 합니다.
- 표현력: 노드 유사성에 대해, 유연한 확률적 정의가 가능하며, (high-order multi-hop information)이 가능하다고 합니다.
- 효율성: 모든 노드 쌍을 고려할 필요가 없습니다. random walk에서 함께 발생하는 (ex. 노드, 노드) 쌍만 고려하면 됩니다.
Feature Learning as Optimization
이제 최적화 문제로 넘어가겠습니다. 노드 와 edgeset 에 대한 그래프가 주어지면, 로 나타낼 수 있으며, 우리의 목표는 로 정의할 수 있습니다. 이 때, 최대 가능도(Log-likelihood)는 로 표현됩니다.
간단하게, 노드 가 주어졌을 때, random walk로 이웃인 에 있는 노드를 예측하는 특징을 학습하고자 합니다.
그럼 이것을 어떻게 예측할지는 대략적으로 아래와 같이 진행합니다.
- 랜덤 워크 전략 을 사용하여, 그래프의 각 노드 에서 시작하여 short fixed-length
(이 부분은 번역이 어렵네요)의 random walk를 실행합니다. - 각 노드 에 대해, 에서 시작하는 random walk로 방문한 노드의 을 수집합니다. (동일한 노드가 여러번 방문될 수 있습니다)
- 마지막으로, 임베딩을 최적화할 것입니다. 노드 가 주어지면, random walk로 정의되는 이웃 노드가 무엇인지 예측하고자 합니다. 그래서, Maximum likelihood objective를 구합니다.
결국, 3번이 핵심이겠네요. 이것을 어떻게 쓸 수 있을까요? 모든 시작 노드의 합계와 근처에 있는 모든 노드에 대한 합계로 사용합니다. 수식으로는 로 표현됩니다. 역시 수식으로는 이해가 잘 되지 않네요. 직관적으로, 임베딩 를 최적화하여, random walk의 동시 발생 가능성을 극대화하는 것 같습니다.
이 때, 의 확률은 Softmax를 사용합니다. 수식으로는 로 계산되어집니다. 노드와 노드 사이의 내적을 최대화하려는 것 같네요. Softmax를 사용하는 이유는 노드가 모든 노드 중에서, 노드와 가장 유사하게 만들어야 하기 때문입니다. 즉, 다중 레이블 분류 문제? 라고 생각해주시면 될 것 같습니다. 내용 관련한 이미지는 아래와 같습니다.
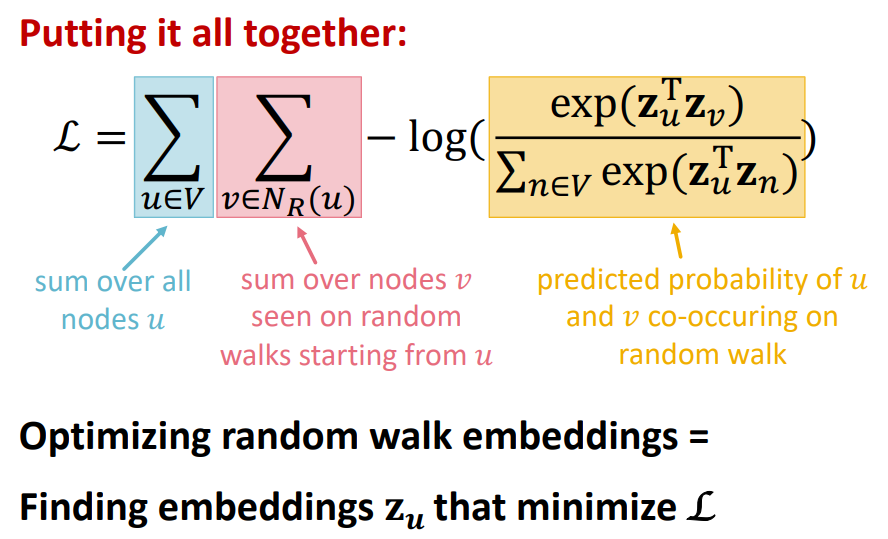
이 방법은 많은 비용이 부과됩니다. 모든 노드 쌍을 고려하진 않지만, 모든 노드 경우의 수를 하기 때문이죠. 시간 복잡도는 로 측정됩니다. 그리고 제일 큰 문제는 Softmax를 적용할 때, 네트워크의 모든 노드에 대해 다시 정규화하기 때문에, ( 부분) 계산 비용이 높습니다.
하지만, 이에 대한 해결책이 있습니다.
Negative Sampling
앞서, Softmax에서 정규화를 진행할 때, 비용이 높다고 했습니다. 이에 대한 해결책으로 Negative Sampling을 제안합니다.
네거티브 샘플링은 주로 자연어 처리 분야의 워드 임베딩 모델 학습에 사용되는 기술입니다. 이 기술은 대규모의 단어 집합에서 모든 단어를 대상으로 하는 것이 아니라, 소수의 '네거티브' 샘플(즉, 관련 없는 단어들)을 선택하여 모델의 성능을 향상시키고 계산 비용을 줄이는 데 목적이 있습니다.
예를 들어, 워드투벡(Word2Vec)과 같은 워드 임베딩 모델에서 네거티브 샘플링은 타겟 단어와 문맥상 관련된 단어들(긍정적인 예시)만을 학습하는 것이 아니라, 무작위로 선택된 단어들(부정적인 예시)도 함께 학습하여 단어 간의 관계를 더 잘 파악할 수 있도록 돕습니다.
네거티브 샘플링은 특히 큰 데이터셋을 다룰 때 매우 유용한데, 이는 전체 단어 집합에 대해 연산을 수행하는 것보다 훨씬 적은 계산으로 비슷한 효과를 낼 수 있기 때문입니다. 이 방법은 소프트맥스(Softmax) 함수를 사용할 때 발생하는 계산량 문제를 해결하는 데 도움을 줍니다.
모든 노드의 하위 집합을 계산하는 방식 대신, 시그모이드의 특성을 활용하는 방식으로 나타내는 것입니다.
이 때, 샘플 는 노드의 차수에 비례하여 선택되며, k값은 보통 5에서 20사이 작은 수로 선택된다고 합니다. 높은 k값은 편향성이 높아진다고 하네요. overfitting의 개념인 것 같습니다.

여기서 최적화 문제를 해결할 수 있는 방법으로 Gradient Descent(확률적 경사 하강법)을 활용하는데요, 해당 부분은 자세히 다루지는 않겠습니다.
간략하게 설명 드리자면 주어진 지점에서 경사를 계산한 후, Step을 통해 가중치를 부여하는 방식입니다. 수식으로 나타내면 이며, 이 때, 는 하강폭(learning rate)을 나타냅니다.
그럼 우리는 이 random walk를 어떻게 적용해야 할까요? 더 최적화 된 random walk를 시도하려면 어떻게 해야 할까요?
여기서 node2vec의 아이디어를 적용할 수 있습니다.
Node2Vec
node2vec의 아이디어는 2차 random walk 을 생성하여, 네트워크 이웃을 생성하고, 최적화 문제를 적용합니다.
조금 더 풀어쓰자면, 그래프의 노드들을 저차원의 feature 공간으로 매핑하는 방법입니다. 이 방법은 그래프의 노드들의 관계를 최대한 보존하면서, 우도(likelihood)를 최대화하는 방식으로 학습됩니다.
여기서 node2vec의 핵심 아이디어는 random walk를 사용하는 것입니다. 즉, 이전 내용과 비교해보면, 그래프의 로컬 구조를 캡처하면서도 노드 간의 유사성을 고려하는 것처럼 보이네요.
node2vec의 학습 과정은 다음과 같습니다.
- Encoder 정의: 각 노드를 저차원 벡터로 임베딩하는 방법을 정의합니다. 이 때, 로 표현됩니다.
- 노드 유사도 함수 정의: 원본 그래프의 노드 간 유사도를 측정하는 함수를 정의합니다. 이 함수는 로 표현됩니다.
- Encoder의 파라미터 최적화: 임베딩 공간상의 유사도와 원본 그래프의 유사도가 최대한 동일하게 만드는 방향으로 encoder의 파라미터를 최적화합니다.
이러한 방식을 통해, node2vec은 그래프의 복잡한 구조를 저차원의 feature 공간으로 효과적으로 변환할 수 있습니다.
node2vec: Biased Walks
node2vec에서는 2가지 random walk 방식이 있습니다. 코딩테스트 알고리즘을 많이 풀어보신 분이라면 익숙하실 텐데요, BFS와 DFS입니다.
이 개념을 Graph random walk에 적용해보면, 노드가 주어졌을 때, BFS 및 DFS기법은 아래 이미지와 같습니다.
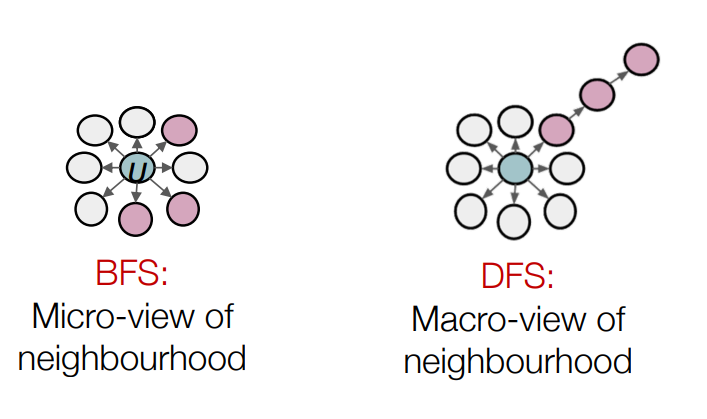
interpolation BFS and DFS
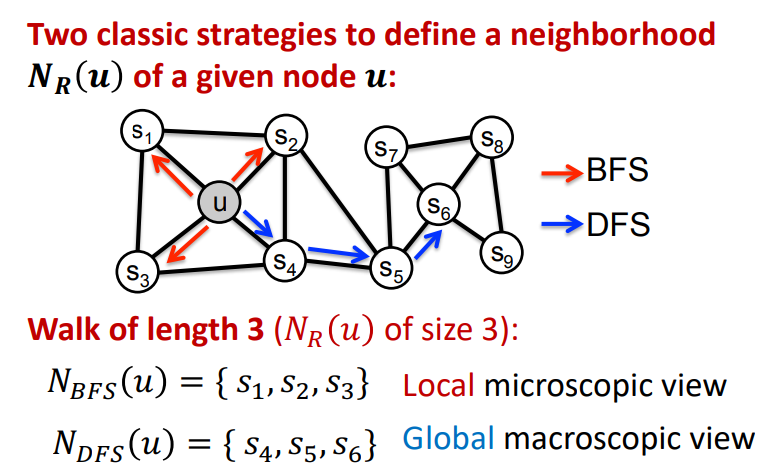
BFS와 DFS를 적용하기 위해서 주어진 노드의 이웃 를 생성하도록 해야합니다. 이 때, 와 두 개의 파라미터를 조정해야 합니다.
- Return : Random walk가 이전 노드로 되돌아갈 가능성이 얼마나 되는지 알려주는 변수이며, p가 높을수록 이전 노드로 돌아가는 경향이 더 커집니다. 이는 random walk가 그래프의 특정 부분을 더 자주 방문하도록 하는데 도움이 됩니다.
- In-out : BFS와 DFS 방법을 결정하는 변수(의역일 수 있습니다)라고 생각됩니다. q가 높을수록 random walk는 이웃이 아닌 노드로 이동하는 경향이 더 커집니다. 그래프의 다양한 부분을 넓게 탐색하도록 하는데 도움이 됩니다.
이러한 BFS, DFS random walk는 2차 random walk라고 합니다.
예시를 들어 자세하게 설명하겠습니다. 우선 아래 이미지를 참고해주세요.
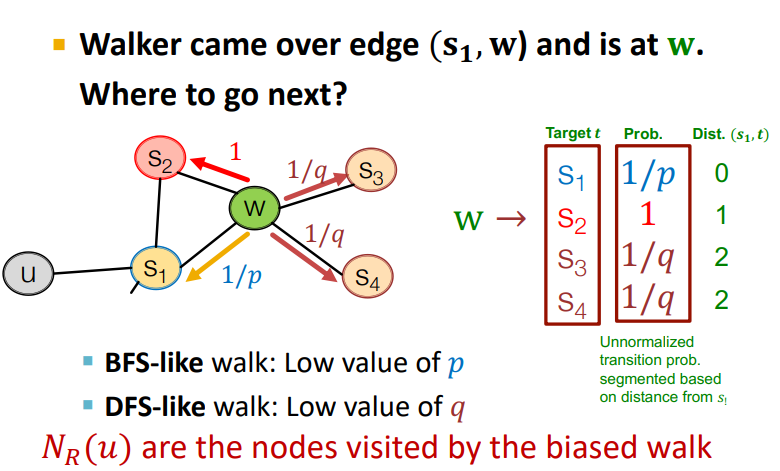
노드가 로 갔을 때, 으로 갈 확률은 이고, 과 로 갈 확률은 입니다. 여기서 의 값을 낮게 설정하면 random walk가 돌아올(이전 항으로) 가능성이 높습니다. 가 낮으면, 및 로 이동할 확률이 높다는 것을 의미합니다.
(는 biased walk(random walk)가 방문하는 노드입니다)
실제 node2vec 알고리즘의 작동방식은 아래와 같습니다.
- 위와 같이, random walk의 확률을 계산합니다.
- 각 노드 에서 시작하여, 길이 의 random walk 을 시뮬레이션 합니다.
- 경사 확률 하강법(Stochastic Gradient Descent)를 사용하여, node2vec의 목적함수를 최적화합니다.
이 때, Linear-time 복잡도를 가지며, 3단계 모두 개별적으로 병렬 실행 가능합니다. 그리고 다른 종류의 random walk 방식도 있다고 하네요.
