1.지식 넣기
일단은 agent 에 앞서 먼저 RAG 부터 해보면서 체험해 보려고하는데요.
여기서 지식 이라는 부분에 외부 자료를 넣을 수 있습니다.
바로 NotebookLM에서 미리 자료 업로드하는 것과 정확히 같은 이유입니다.
즉 RAG를 위해 필요한 저희가 원하는 정보를 DB에 넣어 두잖아요. 그게 바로 이 첨부자료가 되는 겁니다.
원하시는 자료를 넣어서 진행하면 될 것 같아요. 저는 AI 동향에 관한 PDF자료 첨부했습니다.
2. 청크 설정
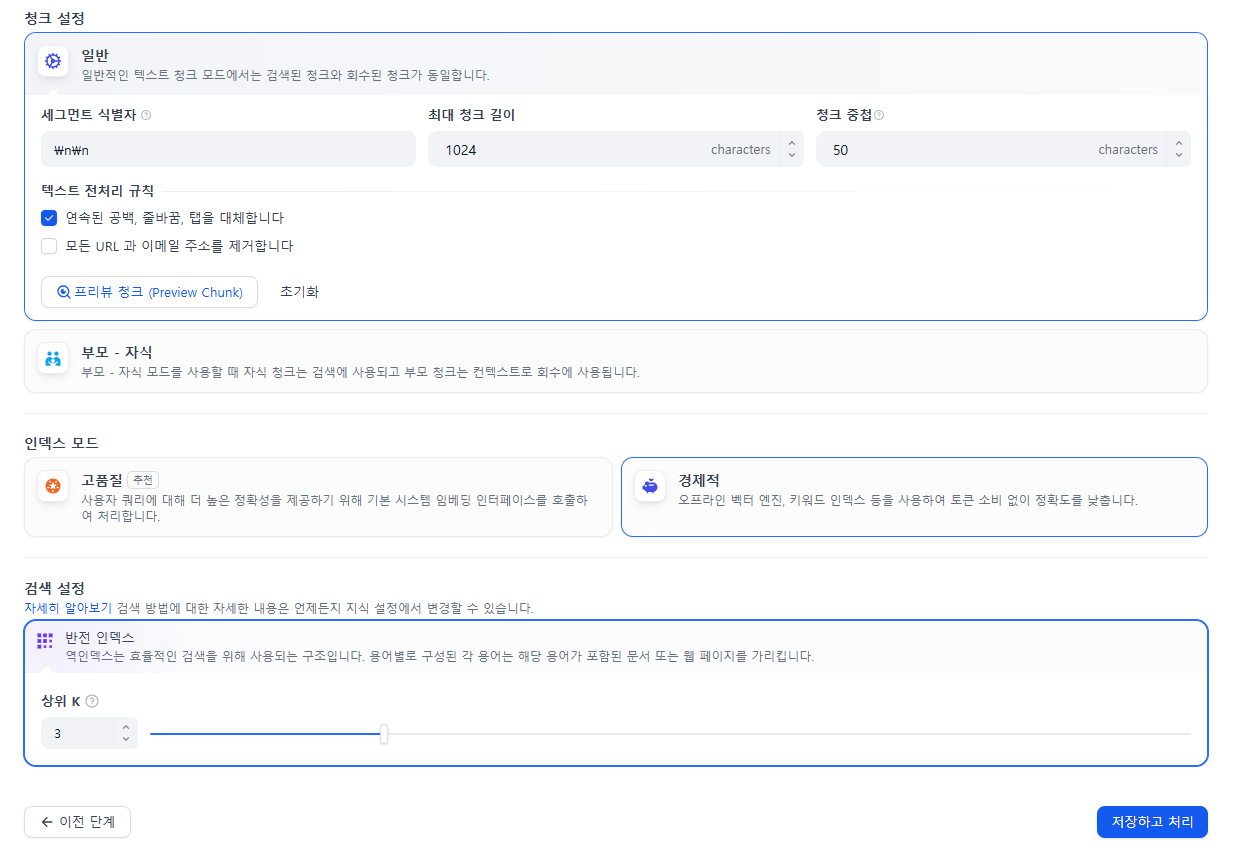
식별자는 문서를 구분할때 그 기준입니다.
\n\n 라는 것은 두번 줄 바뀌었을때 말하는 거가 되는 거죠최대 청크 길이는 말그대로 청크의 최대 길이입니다. 나누는 그 글의 조각의 길이를 의미합니다청크 중첩은 나누는 청크들을 얼마만큼 겹치냐는 겁니다. 칼같이 쪼개지 않고 버퍼를 두는 겁니다. 문맥의 의미적 연관성을 고려한 것입니다.

저는 500의 최대 청크 길이에 청크 중첩은 50 정도로 해서 preview chunk 를 통해서 제가 첨부한 자료가 어떻게 나뉘게 될 것인지 미리 보았는데요.
각 청크가 최대 500character 이내로 나뉘었으며, 또한 설정했던 대로 청크 중첩이 같은 색으로 표시한것 처럼 잘 chunking 한 것을 볼 수 있습니다.
그렇다면 청크를 어떤 사이즈와 중첩을 어느 정도 하는게 과연 효과적 일까요?
저도 궁금해서 찾아봤는데 결국 답은 없고
최적의 값을 찾으려면 대상 데이터, 쿼리 유형, 벡터 DB/LLM 제약을 파악한 뒤, 여러 가지 설정을 A/B 테스트하며 측정해보는 것이 효과적입니다라고 합니다.
작게 쪼개면 retrieval precision이 좋아지지만 문맥 일부가 분리될 수 있고, 너무 크게 하면 context는 풍부해지나 검색 정확도가 떨어질 수 있습니다. 흔히 보이는 아이러니한 상황이네요.
청크 경계는 의미 단위로 나뉘어서 문단 중간에서 끊지 않는 것이 답변 질을 높이는게 당연하게 저도 생각 되는데, 실제 현업에서는 어떻게 해결 할까요? 크게 7가지 방안이 있다고 합니다.
주요 실전 해결 방안
Recursive Chunking: 복수의 구분자(문단 → 문장 → 마침표/물음표 → 단어 → 글자 순)로 우선순위를 두고 재귀적으로 쪼개는 방식입니다. 먼저 문단 단위로 시도하고, 크기가 너무 크면 문장 단위 등 아래 단계로 내려가며 구조를 최대한 보존합니다. 크기 제한을 만족할 때까지 점진적으로 쪼갭니다.
Semantic Chunking: 임베딩 기반으로 인접 문장(또는 문단)들의 의미적 유사도를 계산해, 의미적 단위가 바뀔 때(새로운 주제가 등장) 청크를 나눕니다. 즉, 실제 의미 경계를 직접 감지해 chunk를 잘라 contents split 문제를 완화합니다. 도메인 특화 시스템(법률, 의료 등)에서 많이 쓰입니다.
Sliding Window/Overlap: 고전적이지만 강력한 방법으로, chunk 간 겹침(overlap)을 둬서 (중간에 끊겨도) 문맥 일부를 다음 chunk에 중복 저장합니다. 중복 chunk들이 쿼리에 함께 나오며, 정보손실을 줄입니다.
Sentence Splitter 활용: spaCy, NLTK 등 NLP 패키지에서 문장/문단 분리기를 적극 활용해 자연스러운 경계에서 청크를 분할하고, code나 표는 별도 전처리 규칙 적용(함수/클래스별, 헤더별 분리 등)합니다.
문서 구조 활용: 이미 구조화된 데이터를 쓸 수 있다면(Markdown 헤더, HTML tag, 테이블 schema 등) 구분자(헤더, 구획, 표 등)를 chunk 단위 삼아 가장 의미 있는 단위별로 쪼갭니다. 코드/테이블은 기능별/행별로 쪼개는 전처리를 적용합니다.
계층적(Hierarchical) Chunking: 문서의 계층 구조를 meta data로 붙여, retrieval 단계에서 단편(chunk) 하나만 보여주지 않고 인접 상위 단위(부모 chunk, section 등)까지 함께 보여주는 방법도 증가하고 있습니다.
실제 산업/논문 적용 사례
논문 및 실전 현장에서는 위 전략을 조합하는 것이 대세입니다. 예를 들어, 1차로 semantic chunking/recursive splitting을 하고, 2차로 중첩(overlap)을 더해 retrieval 정확도를 올립니다.
의미 경계 분할(Sentence Splitter/Embedding clustering)이 가장 retrieval 효과가 높았다는 평가도 있습니다. 실제 SQuAD, HotpotQA 등 데이터셋 실험에서 sentence splitter 기반 chunk와 의미 기반 구분 chunk가 성능이 높다는 사례가 다수 있습니다.
raw 데이터(스크립트, 로그 등)는 sliding-window + semantic chunking을 병행해 노이즈를 줄이고, 기술문서/매뉴얼/Knowledge Base는 문단/포맷 구조 혜택을 적극 사용합니다.
무작정 잘라서 정보가 끊기지 않게 하려면, 구문 구조를 적극 이용하고 NLP/Embedding/Overlap 복합전략을 결합하는 것이 최신 현업과 연구 중인 내용들 이네요.
지금 제가 해보는 dify에서는 기본적으로 재귀적 분할(Recursive Chunking) 기반의 전략을 사용하며, 사용자가 고정된 토큰 크기(max_tokens)와 중첩(chunk_overlap)을 설정할 수 있도록 지원 한거고, 추가적으로Parent-Child Chunking기능도 지원하네요.
3. 인덱스 모드

인덱스 모드는 보이는 것 처럼 2가지가 있는데
고품질은 방금 만든 청크를 의미와 맥락을 담아서 수치화 시켜주는 것 입니다. 이것을 통해 검색 할때유사도로 검색하게 되는 것이고,
경제적은 임베딩을 하지 않는 것입니다.키워드를 통해서 검색하는 것 입니다.
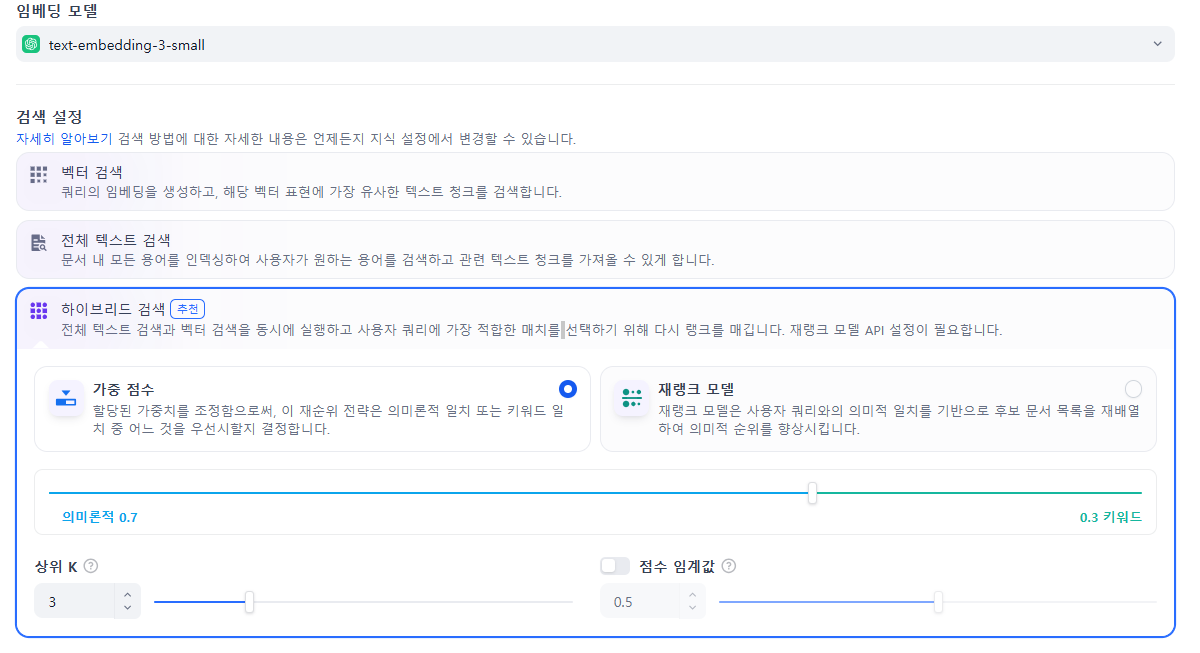
4. 모델 선택 및 검색 설정
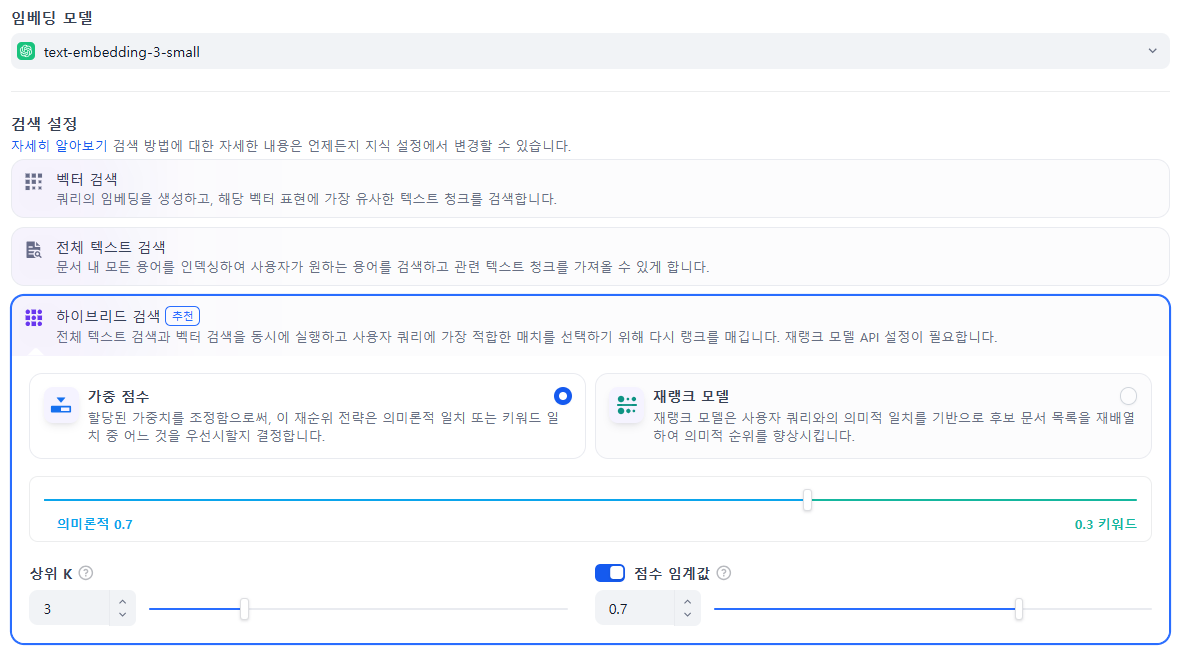
모델 설정 해주시고, 검색 방법을 선택 할 수 있습니다.
이중 하이브리드 검색이 추천되어있는데 여기서 하단의 의미론적 , 키워드 이렇게 되어있는데 가중치를 조절할 수 있도록 제공하고 있네요.
이후에 저는 임계값 0.7 이상의 top 3에 대해서 가져와 라고 설정했습니다.
5. 임베딩
임베딩이 완료되면 Dify 문서에서 제가 방금 작업했던 결과를 볼수 있습니다.
6. 테스트
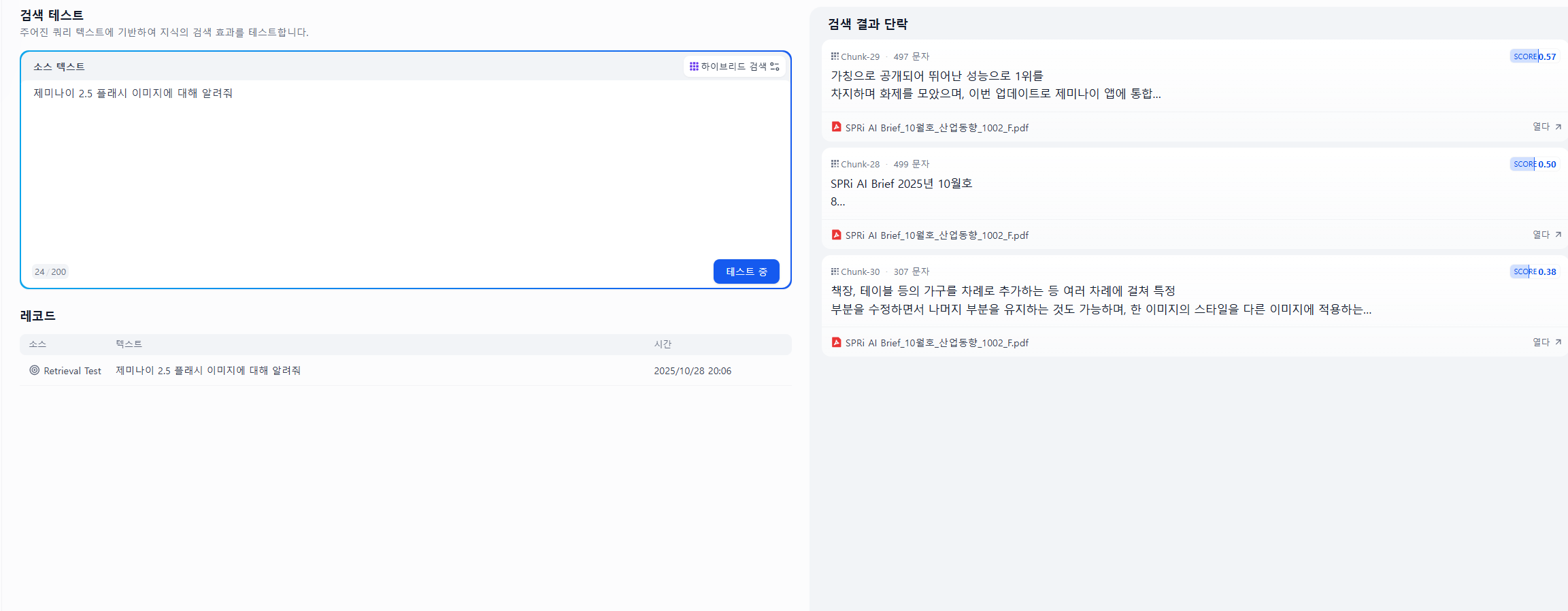
사실 처음에 같은 질문을 했는데 에러가 발생해서 생각 해보다가, 내가 임계값을 너무 높게 잡았나 싶어서 관련 설정을 없애니까 이렇게 답변이 나오네요.
제가 했던 대로 TOP 3 청크에 대한 정보와 각각의 score가 0.57 0.5 0.38 이렇게 낮아서 안나온게 맞았습니다.
7. 채팅 플로우에 적용
이전에서 챗봇 만들때 플로우 사용했던 것 처럼 방금 만들었던 것을 플로우에 넣어서 동작 해보겠습니다.
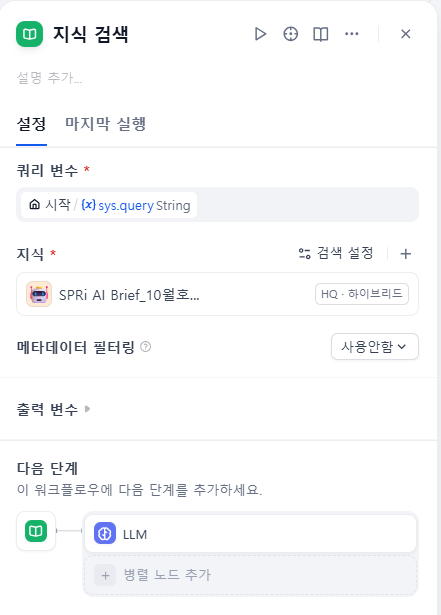
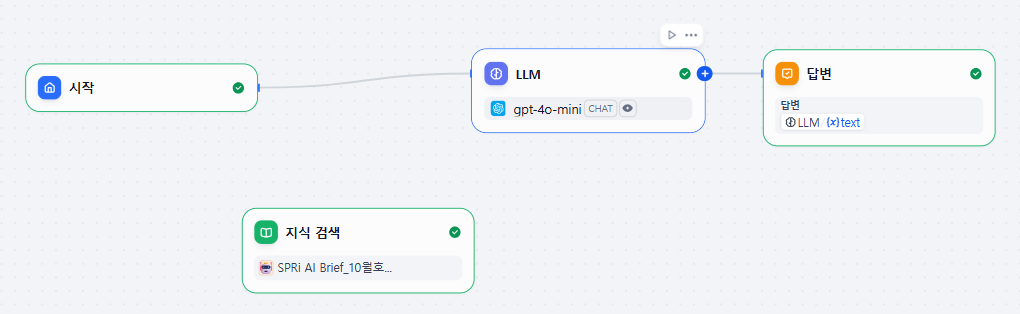
제가 방금까지 만든게 지식 이잖아요. 그래서 지식 검색 노드를 생성하고 제가 방금 생성했던 지식을 넣어 주었습니다.
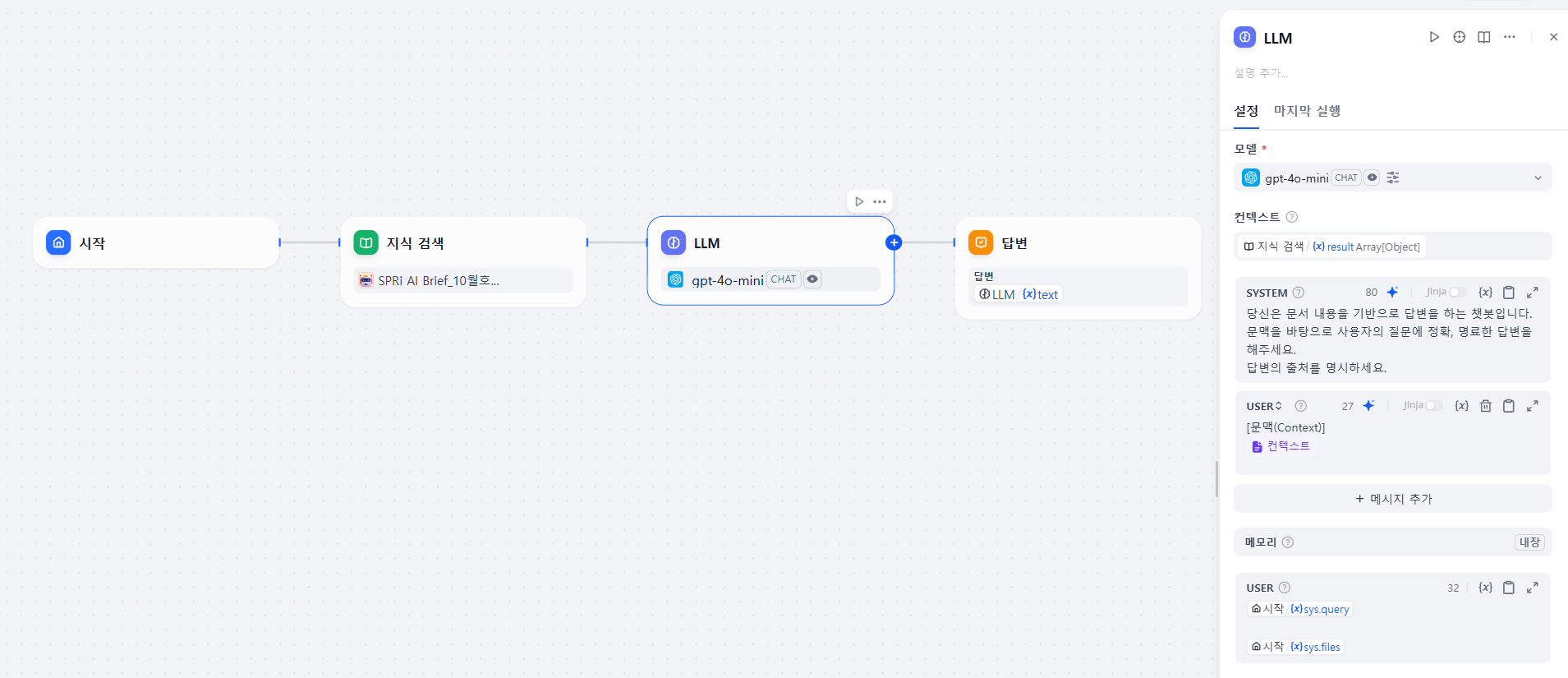
이전 글에서 챗봇 만들었을때와 유사한 점이 많아서 노드 생성, 연결 하는 부분의 설명은 지나가겠습니다. 위의 사진 처럼 플로우를 작성했습니다.
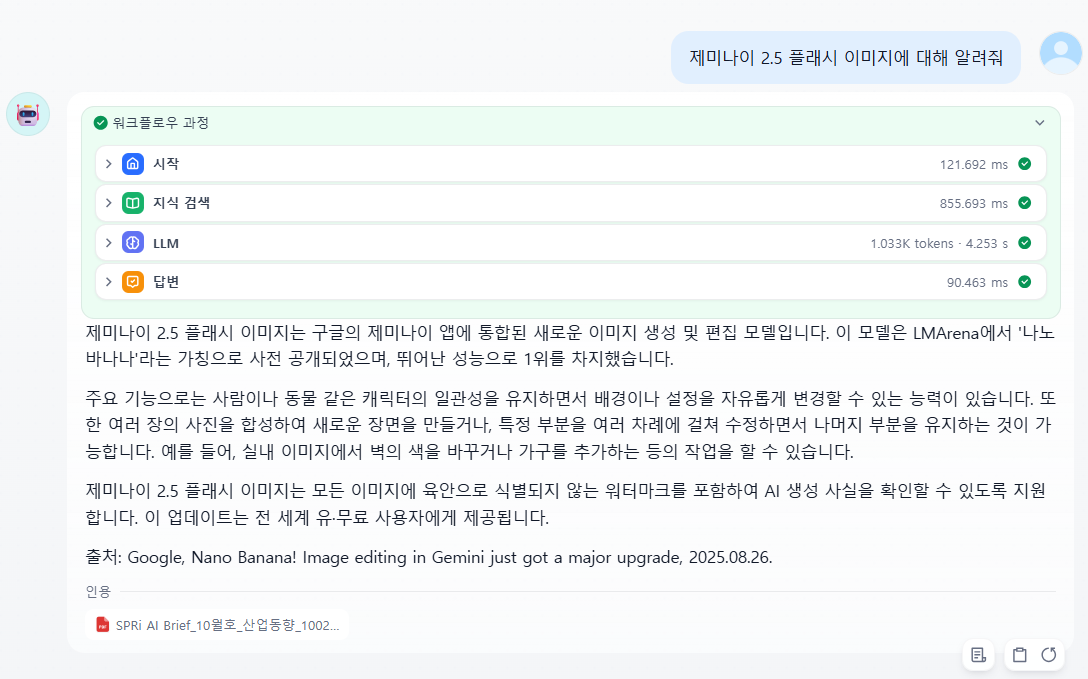
RAG 테스트했을때와 동일 질문을 했고 다음과 같은 답변을 해주네요.
8. 소감
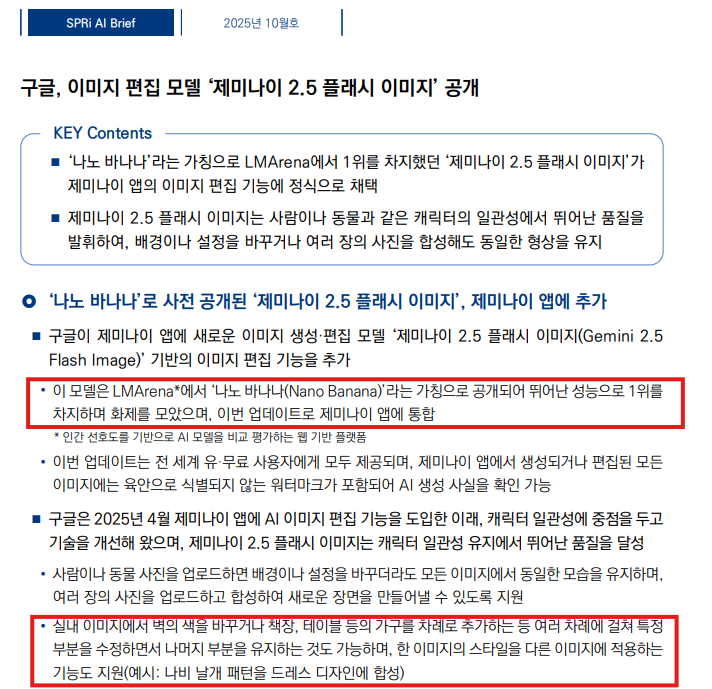
답변을 보았을때 실제 자료에서의 빨간 박스 내용들이 사용되었겠구나 라는 것을 짐작 할 수 있네요.
이번엔 만약 제가 방금 생성했던 지식이 없이 플로우 진행하면 어느 수준의 답변이 나올지 보겠습니다.
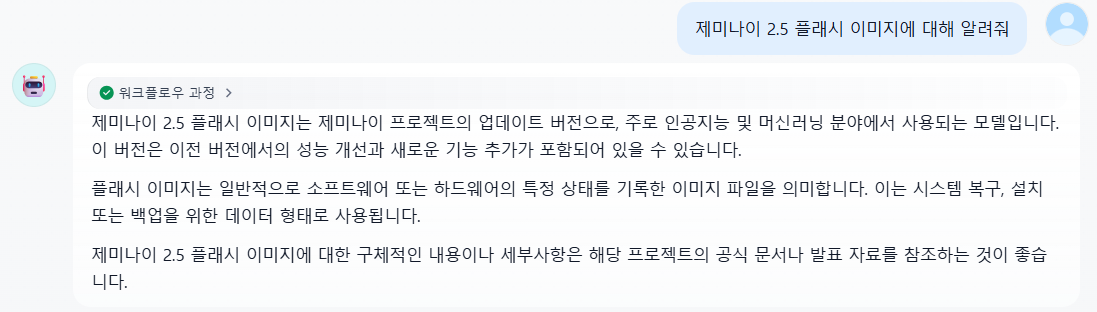
네 이런식으로 답변의 차이가 나네요.
이렇게 본인이 원하는 특정 지식이나 도메인에 대한 정보를 넣어보고 사용해 보았습니다.
