[1] 성능튜닝의 3대 요소
- sql파싱부하해소
- 데이터베이스 call최소화
- I/O효율화
[2] 인스턴스
SGA 공유메모리 영역과 이를 액세스하는 프로세스 집합이다.
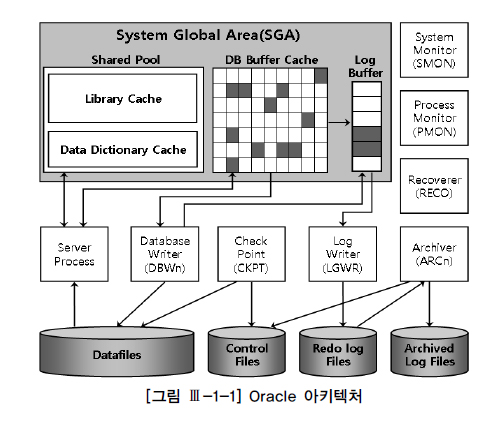
(1) 기본적으로 하나의 인스턴스가 하나의 데이터베이스를 액세스한다.
- RAC환경에서는 여러 인스턴스가 하나의 데이터베이스를 엑세스 가능
- 하나의 인스턴스가 여러 데이터 베이스를 액세스는 불가능
[3] 프로세스
서버 프로세스 + 백그라운드 프로세스
(1) 서버프로세스
- 사용자 프로세스와 통신하면서 사용자의 각종 명령을 처리한다.
- SQL Server는 Worker 쓰레드로 표현한다.
1. 서버 프로세스가 하는 일
- sql파싱하고 최적화하고 블록을 읽고 네트워크를 통해 결과를 전송하는 일련의 작업을 수행한다.
- 데이터 파일로 부터 DB 버퍼 캐시로 블록을 적재한다.
- 블록을 캐시에서 밀어냄으로써 Free 블록을 확보한다.
- Redo 로그 버퍼 비우기 등
2. 서버 프로세스로의 연결 요청 이슈
- (1) sql을 수행할때마다 연결요청을 반복하면 서버의 성능저하가 있기에 Connection Pooling 기법이 필수이다.(반복재사용)
- (1) 이 때 , Connection Pooling 기법시 Connection을 닫는 게 아니다.
- (1) 연결 요청에 대한 부하는 쓰레드 기반 아키텍처보다 프로세스 기반 아키텍처에 부하가 더 크다.
3. 서버 프로세스의 종류
종류1) 공유 서버 방식
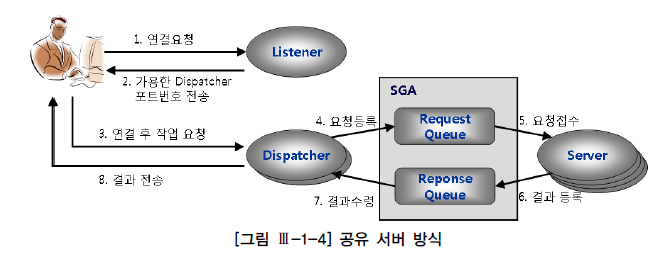
- 하나의 서버 프로세스를 여러 사용자 세션이 공유한다.
- Connection Pooling 기법
- 미리 여러개의 서버 프로세스를 띄어놓고 이를 공유해서 반복 재사용한다.
- (1) 사용자 프로세스는 서버 프로세스와 직접 통신하지 않고 Dispatcher 프로세스를 거친다.
✅ 공유 서버 작동 방식(순서)
- 사용자 명령이 Dispatcher에게 전달된다.
- Dispatcher는 이를 SGA에 있는 요청 큐(Request Queue)에 등록한다.
- 이후 가장 먼저 가용해진 서버 프로세스가 요청 큐에 있는 사용자 명령을 꺼내서 처리한다.
- 그 결과를 응답 큐(Response Queue)에 등록한다.
- 응답 큐를 모니터링하던 Dispatcher가 응답 결과를 발견하면 사용자 프로세스에게 전송한다.
종류2) 전용 서버 방식
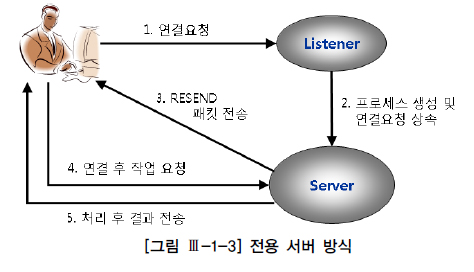
- 서버 프로세스가 단 하나의 사용자 프로세스를 위해 전용(Dedicated) 서비스를 제공한다.
- SQL을 수행할 때마다 연결 요청을 반복하면 (1) 서버 프로세스의 생성과 해제도 반복하게 되므로 DBMS에 매우 큰 부담을 주고 성능을 크게 떨어뜨린다.
- OLTP성 애플리케이션에선 Connection Pooling 기법을 필수적으로 사용해야 한다.✅ 전용 서버 작동 방식(순서)
- 사용자는 리스너에 연결을 요청한다.
- 리스너는 서버로 프로세스를 생성하고 연결 요청을 상속한다.
- 서버는 사용자에게 패킷을 전송한다.
- 연결 후 사용자는 서버로 작업을 요청한다.
- 서버는 사용자에게 결과를 전송한다.
(2) 백그라운드 프로세스
1) 백그라운드 프로세스 종류
- System Monitor(SMON): 장애후 재기동에 인스턴스 복구하고 임시 세그먼트와 익스텐트를 모니터링한다.
- Process Monitor(PMON) : 이상이 생긴 프로세스가 사용하던 리소스를 복구시킨다.
- Database Writer(DBWn) : 버퍼캐시의 Dirty버퍼를 데이터파일에 기록한다.
- Log Writer : 로그버퍼 엔트리를 Redo로그 파일에 저장한다.
- Arvhiver : Redo로그가 덮어쓰여지기 전에 Archiver로그로 백업한다.
- chechkpoint : 이전 CheckPoint 이후의 변경 사항을 데이터 파일에 기록하도록 트리거링한다.
- 이전에 Checkpoint가 일어났던 마지막 시점 이후의 데이터베이스 변경 사항을 데이터 파일에 기록하도록 트리거링한다.
- 기록이 완료되면 현재 어디까지 기록했는지를 컨트롤 파일과 데이터 파일 헤더에 저장한다.
- Write Ahead Logging 방식(데이터 변경 전에 로그부터 남기는 메커니즘)을 사용하는 DBMS는 Redo 로그에 기록해 둔 버퍼 블록에 대한 변경사항 중 현재 어디까지를 데이터 파일에 기록했는지 체크포인트 정보를 관리해야 한다.
- 이는 버퍼 캐시와 데이터 파일이 동기화된 시점을 가리키며, 장애가 발생하면 마지막 체크포인트 이후 로그 데이터만 디스크에 기록함으로써 인스턴스를 복구할 수 있도록 하는 용도로 사용된다.
- 이 정보를 갱신하는 주기가 길수록 장애 발생 시 인스턴스 복구 시간도 길어진다.
- Recover : 분산 트랜잭션 문제를 해결한다.
[4] 파일구조

(1) 데이터파일
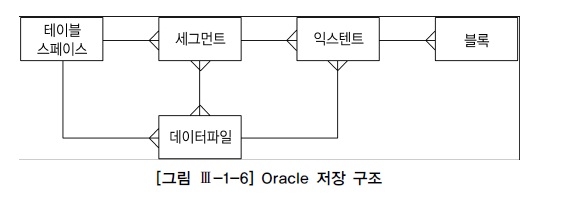
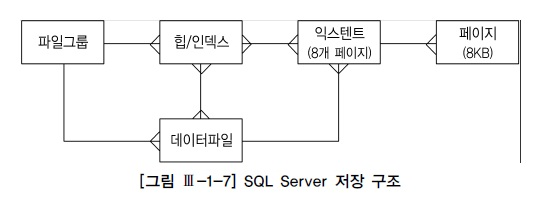
1. 블록(=페이지)
- 대부분의 DBMS에서는 I/O 블록단위로 이루어져있다.
- 데이터를 읽고 쓸때의 논리적인 단위이다.
- SQL 성능을 좌우하는 가장 중요한 성능지표이다.
- 옵티마이저의 판단에 가장 큰 영향을 미치는 요소이다.
- 오라클에서는 '블록'이라 칭한다.
- 오라클에서 블록크기는 2KB,4KB, 8KB, 16KB, 32KB, 64KB,8KB 로 정해져있다. - SQL Server '페이지'라 칭한다.
2. 익스텐트(Extent)
- 테이블스페이스로부터 공간을 할당하는 단위이다.
오라클
- 크기가 다양하다.
- 1개의 익스텐트는 1개의 오브젝트(테이블)가 사용한다.
SQL Server
- 항상 64KB이다. (페이지크기가 8KB이므로)
- 1개의 익스텐트는 2개 이상의 오브젝트(테이블)이 사용할 수 있다.
3. 세그먼트(Segment)
- 테이블, 인덱스,Undo 처럼 저장공간을 필요로하는 데이터베이스 오브젝트이다.
- 한개 이상의 익스텐트가 사용한다.
- 파티션에서는 오브젝트와 세그먼트가 1:M 관계이다.
- 파티션을 만들면 내부적으로 여러개의 세그먼트가 만들어진다.
- 한 세그먼트에 할당된 엑스텐트가 여러 데이터파일에 흩어져 저장된다.
- 디스크 경합이 감소하며 I/O 분산 효과가 나타난다.
- 오라클에서의 명칭 : 세그먼트
- SQL Server에서의 명칭 : 힙구조 또는 인덱스 구조 오브젝트
4. 테이블스페이스(Tablespace)
- 세그먼트를 담는 콘테이너로서 여러개의 데이터파일로 구성된다.
- 사용자는 데이터 파일을 직접 선택할수 없으므로 실제 파일을 선택하고 익스텐트를 할당하는것은 DBMS의 몫이다.
- 오라클에서의 명칭 : 테이블스페이스
- SQL Server에서의 명칭 : 파일그룹
(2) 임시파일
- 다음과 같은 작업시 메모리 공간이 부족해지면 중간 결과집합을 저장하는 용도로 사용된다.
- 대량의 정렬 작업시
- 해시 작업을 수행시
- 오라클에서는 임시 테이블스페이스를 여러개 생성해두고, 사용자마다 별도의 임시 테이블스페이스를 지정해 줄 수 있다.
(3) 로그파일
- DB 버퍼 캐시에 가해지는 모든 변경사항을 기록하는 파일이다.
- 로그 기록은 Append 방식으로 이루어지기 때문에 상대적으로 매우 빠름
- 빠른 커밋 지원
1. 로그파일
오라클 : 리두로그
- 트랜잭션의 데이터 유실을 방지한다.
- 캐시 복구 기능을 한다.
- 마지막 체크포인트이후 사고 발생 직전까지 수행되었던 트랜잭션을 Redo 로그를 이용해서 재현한다. - 최소 두개이상의 파일로 구성하며 round-robin 방식을 이용한다.
SQL Server: 트랜잭션 로그
- 데이터파일(데이터베이스)마다 트랜잭션 로그 파일이 하나씩 생성된다.(ldf)
- 가상 로그 파일이라고 불리는 더 작은 세그먼트 단위로 나뉜다.
- 가상 로그 파일 개수가 너무 많아지지 않도록 옵션을 지정한다.
- 로그파일을 넉넉한 크기로 만들어 자동 증가가 발생하지 않도록 하거나, 증가단위를 크게 지정한다.
2. Archved(=Offline) Redo 로그
- 오라클에서 온라인 리두로그가 재사용 되기 전에 다른 위치로 백업해둔 파일이다.
- 디스크가 깨지는 등의 물리적인 저장매채 장애에 대해서 복구하기 위해 사용된다.
- SQL Server는 Archived Redo 로그에 대응되는 개념이 없다.
[5] 메모리 구조
(1) 메모리 영역의 종류
1. 시스템 공유 메모리 영역
- 여러 프로세스가 동시에 엑세스할 수 있는 메모리 영역이다.
- 모든 DBMS는 공통적으로 사용하는 캐시 영역이 있다.
- DB 버퍼캐시, 공유풀, 로그 버퍼..
- 그 외에 Large Pool, Java Pool, 시스템 구조와 제어 구조를 캐싱하는 영역을 포함한다.
- 여러 프로세스가 공유되기 때문에 내부적으로 액세스 직렬화 매커니즘을 사용한다.
- Latch, 버퍼Lock, 라이브러리 캐시 Lock/Pin..
- 오라클에서의 명칭 : System Global Area(SGA)
- SQL Server에서의 명칭 : Memory Pool
2. 프로세스 전용 메모리영역
- 오라클은 프로세스 기반의 아키텍처로 서버 프로세스가 자신만의 전용 메모리 영역을 가진다.
- 이 영역을 Process Global Area(PGA) 라고 한다.
- 데이터를 정렬하고 세션과 커서 정보를 저장한다.
- ⭐️ 쓰레드기반의 아키텍처를 사용하는 SQL Server 는 프로세스 전용 메모리 영역을 갖지 않는다.
(2) ⭐️ DB 버퍼캐시
- 데이터파일로부터 읽어들인 데이터 블록을 담는 캐시영역이다.
- 사용자 프로세스는 서버 프로세스를 통해 DB 버퍼 캐시의 버퍼 블록을 동시에 액세스한다.
- 내부적으로 Buffer Lock을 통한 직렬화 - Direct Path Read 매커니즘이 작동하는 경우를 제외하면, ⭐️ 모든 블록 읽기는 버퍼 캐시를 통해 이루어진다.
- ⭐️ 디스크에서 읽을때도 버퍼캐시에 적재한 후 읽는다.
- ⭐️ 데이터 변경도 버퍼캐시에 적재된 블록을 통해 이루어진다.
- 변경된 블록(더티버퍼) 은 주기적으로 DBWR 프로세스에 의해 데이터파일에 기록된다.
버퍼캐시를 사용하는 이유
👉 디스크 I/O는 물리적으로 액세스암이 움직이면서 헤드를 통해 이루어지는 반면,
메모리I/O는 전기적 신호에 불과하기 때문에 디스크I/O와는 비교할수 없을 정도로 빠르다.
1. 버퍼블록 상태
- Free Buffer
- 인스턴스 기동 후에 아직 데이터가 읽혀지지 않아 비어 있는 상태
- 데이터파일과 서로 동기화 되어 언제든지 덮어써도 되는 상태
- Dirty Buffer
- 버퍼가 캐시된 이후 변경이 발생하지만, 아직 디스크에 기록되지 않아 데이터파일 블록과 동기화가 필요한 버퍼 블록이다.
- 버퍼 블록이 재사용 되려면 디스크에 먼저 기록되어야 하고 디스크레 기록된 순간 Free 버퍼로 변경된다.
- Pinned Buffer
- 읽기 또는 쓰기 작업이 현재 진행중인 버퍼 블록
2. LRU알고리즘
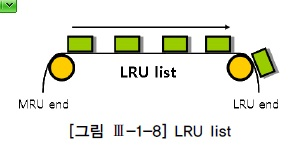
- LRU 알고리즘이란?
- 모든 버퍼 블록헤더를 LRU 체인에 연결해 사용 빈도 순으로 위치를 옮기다가(Touch count가 높을수록 MRU) Free 버퍼가 필요해지면, 엑세스 빈도가 낮은(LRU) 쪽 데이터 블록부터 밀어내는 방식이다.
- LRU 알고리즘을 사용하는 이유
- 버퍼 캐시는 유한한 자원이므로 모든 데이터를 캐싱해 둘 수 없기 때문에 사용 빈도가 높은 데이터 블록 위주로 버퍼 캐시가 구성 되도록 LRU 알고리즘을 사용한다.
(3) 공유풀(shared pool)
- 딕셔너리캐시와 라이브러리 캐시로 구성되며 버퍼 캐시처럼 LRU 알고리즘을 사용한다.
- 오라클에서의 명칭 : Shared Pool
- SQL Server에서의 명칭 : Procedure Cache
1. 딕셔너리 캐시
- 다음과 같은 메타정보를 저장한다.
- 테이블, 인덱스같은 오브젝트
- 테이블스페이스, 데이터파일, 세그먼트, 익스텐트, 사용자, 제약사항
2. 라이브러리 캐시
- SQL 실행에 관련된 모든 객체에 대한 정보를 관리한다.
- 서버 프로세스가 SQL을 작업할때 사용되는 작업공간이다.
- ⭐️ SQL에 대한 분석정보 및 실행계획을 저장한다.
- ⭐️ 공유 SQL을 저장하기 위해 사용한다.
라이브러리 캐시를 사용하는 이유
👉 캐싱된 SQL과 그 실행계획의 재사용성을 높이는 것이 수행 성능을 높이고 DBMS 부하를 최소화한다.
이 때 바인드변수 사용 및 기준에 맞는 SQL 작성으로 재사용성을 높여 줘야 한다.
(4) 로그 버퍼
- 오로지 복구를 위해 사용된다.
- ⭐️ DB 버퍼에 가해지는 모든 변경사항을 로그버퍼에 먼저 기록한다.
1. 로그 버퍼 기록 방식의 종류
Physiolosical logging
- physical logging과 logical logging의 장점을 결합한 것이다.
- 변경된 데이터에 대한 before/after 이미지를 저장하고 opcode(명세서)를 기록하여 완벽한 복구를 보장한다.
page fix rule
- 변경이 시작되는 시점부터 완료되는 시점까지 해당 블록을 보호해주는 아키텍처이다.
- os에서 세마포어를 할당받아서 세마포어가 해당 블록을 보호한다.
log a head
- 데이터 변경작업시에 DBWR에 의한 블록 변경보다 로그를 먼저 기록하는 기법이다.
⭐️ log force at commit
- 커밋시 리두로그를 먼저 기록하는 기법이다.
- 기록하는 속도가 빠른 리두를 먼저 기록하게 하여 중간에 발생하는 장애로부터 완벽한 복구를 보장한다.
logical odering of redo
- 로그를 기록할때 정해진 위치가 아닌 순서와 무관하게 기록하되, scn과 RBA 를 이용하여 복구에 대한 순서를 결정하여 빠른 복구를 보장한다.
(5) PGA(Process Global Area)
- 오라클의 서버 프로세스는 자신만의 PGA 메모리 영역을 할당받아
이를 프로세스에 종속적인 고유 데이터를 저장하는 용도로 사용한다. - PGA 는 다른 프로세스와 공유되지 않은 독립적인 메모리 공간이다.
- 똑같은 개수의 블록을 읽더라도 SGA 버퍼 캐시에서 읽는것보다 훨씬 빠르다.
1. PGA의 종류
UGA(User Global Area)
- 각 세션을 위한 독립적인 공간이다.
- Dedicated Server : PGA 에 UGA 영역을 할당한다.
- Shared Server: SGA의 Large Pool 또는 Shared Pool 에 UGA 영역을 할당한다.
CGA(Call Global Area)
- 오라클은 하나의 데이터베이스 call을 넘어서 다음 call까지 계속 참조되는 정보를 UGA 에 담는다.
- call이 진행되는 동안 필요한 데이터는 CGA에 담는다.
- Parse Call, Execute Call, Fetch Call 마다 매번 할당 받는다.
- Call이 진행되는동안 Recursive call이 발생하면 그 안에서도 Parse, Execute, Fetch 단계별로 CGA를 할당받는다.
- 할당된 공간은 call이 끝나자마자 해제되어 PGA에 반환된다.
Sort Area
- 데이터 정렬을 위해 사용되며, 부족할때마다 chunk 단위로 조금씩 할당된다.
- 세션마다
sort_area_size파라미터로 설정이 가능하다.- 9i 이상부터는
workarea_size_policy파라미터를 auto로 설졍하면 내부적으로 알아서
sort area를 할당한다.
- 9i 이상부터는
- Sort Area 할당위치
- DML은 CGA 영역에 할당한다.
- SELECT 수행 중간 단계에 필요한 sort area는 CGA에 할당한다.
- 최종 결과집합을 출력하기 직전 단계에서 필요한 sort area는 UGA에 할당한다.
- ⭐️ SQL Server는 PGA영역이 없다.
- SQL Server는 정렬을 수행할 때 Memory Pool 안에 있는 버퍼캐시에서 수행한다.
- SQL Server에서 세션 관련 정보는 Memory Pool 안의 Connection Context 영역에 저장한다.
[6] 대기이벤트
(1) 대기이벤트란?
- DBMS 내부에서 활동하는 수많은 프로세스간에서는 상호작용이 필요하다.
이 과정에서 다른 프로세스가 일을 마칠때까지 기다려야하는 상황이 발생하는데
그때마다 해당 프로세스는 자신이 일을 계속 진행할 수 있는 조건이 충족될때까지 수면(Sleep)상태로 대기한다. - 오라클에서의 명칭 : 대기이벤트(Wait Event)
- SQL Server에서의 명칭 : 대기유형(Wait Type)
(2) Response Time Analysis 성능 방법론
✅ Response Time Analysis 성능 방법론에서 정의한 서버 응답시간
Reponse Time = Service Time + Wait Time
= CPU Time + Queue Time
- 서비스시간(Service Time = CPU Time)
- 프로세스가 정상적으로 동작하며 일을 수행한 시간이다.
- 대기시간(Wait Time = Queue Time)
- 프로세스가 잠시 수행을 멈추고 대기한 시간이다.
Response Time Analysis 방법론
- Cpu Time과 Wait Time을 각각 break down 하면서 서버의 일량과 대기시간을 분석한다.
- Cpu Time 분석
- 파싱작업에 소비한 시간인지 ?
- 쿼리 본연의 오퍼레이션 수행을 위해 소비한 시간인지 ?
- Wait Time 분석
- 각가 발생한 대기 이벤트를 분석해서 가장 시간을 많이 소비한 이벤트 중심으로 해결방안을 모색한다.
(3) 대기 이벤트의 종류
1. 라이브러리캐시 부하
- 라이브러리 캐시에서 SQL 커서를 찾고 최적화 하는 과정에서 경합이 발생하여 나타난 대기이벤트이다.
- latch : shared pool
- latch : library cache
- 라이브러리 캐시와 관련해서 자주발생하는 대기이벤트
- 수행중인 SQL이 참조하는 오브젝트에 다른 사용자가 DDL문장을 수행할때 발생하는 대기이벤트
- library cache lock
- library cache pin
- 수행중인 SQL이 참조하는 오브젝트에 다른 사용자가 DDL문장을 수행할때 발생하는 대기이벤트
2. 데이터베이스 call과 네트워크 부하
- 애플리케이션과 네트워크 구간에서 소모된 시간에 의해 나타난 이벤트이다.
- SQL*Net message from client
- client로부터 다음 명령이 올때까지 idle 상태로 기다릴때 발생한다.
- 데이터베이스 경합과 관계없다.
- SQL*Net message to client
- 메시지를 보냈는데 메시지를 받았다는 신호가 늦게 도착하는경우
- 클라언트가 너무 바쁠경우
- SQL*Net more data to client
- 메시지를 보냈는데 메시지를 받았다는 신호가 늦게 도착하는경우
- 클라언트가 너무 바쁠경우
- SQL*Net more data from client
- 클라이언트로부터 더 받을 데이터가 있는데 지연이 발생한 경우
- SQL*Net message from client
3. 디스크 부하
- 디스크 I/O 발생할 때 나타나는 대기 이벤트이다.
- db file sequential read
- 한번의 I/O call에 하나의 데이터 블록만 읽는 Single Block I/O가 발생할 경우
- 인덱스 블록을 읽는 경우
- 한번의 I/O call에 하나의 데이터 블록만 읽는 Single Block I/O가 발생할 경우
- db file scattered read
- Multi Block I/O
- Table Full Scan 시
- Index Fast Full Scan 시
- Multi Block I/O
- direct path read
- direct path write
- direct path write temp
- direct path read temp
- db file parallel read
- db file sequential read
4. 버퍼캐시 경합
- 버퍼캐시에서 블록을 읽는 과정에서 경합이 발생하여 나타나는 대기 이벤트이다.
- latch : cache buffers chains
- latch : cache buffers lru chain
- buffers busy waits
- free buffer waits
- 해소 방법은 I/O부하 해소 방법과 비슷하다.
5. LOCK관련 대기이벤트
- enq : TM - contention
- enq : TX - row lock contention
- enq : TX - index contention
- enq : TX - allocate ITL entry
- enq : TX contention
- latch free
- 특정 자원에 대한 래치를 여러차례(2000번 가량) 요구했지만 해당 자원이 계속 사용중이어서 잠시 대기 상태로 빠질때마다 발생한다.
⭐️ Latch
- Lock은 사용자 데이터를 보호하는 반면, Latch는 SGA에 공유되어 있는 갖가지 자료구조를 보호할 목적으로 사용하는 가벼운 LOCK이다.
- Latch도 일종의 Lock 이지만 큐잉(Queueing) 매커니즘을 사용하지 않는다.
- 특정자원에 액세스하려는 프로세스는 래치 획득에 성공할때까지 반복해서 시도하나, 우선권은 부여받지 못한다.
- 즉, 처음시도한 래치가 맨 나중에 래치획득에 성공할수도 있다.
6. 그 외 대기이벤트
- log file sync
- checkpoint completed
- log file switch completion
- log buffer space

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’