[1] 쿼리변환
(1) 쿼리변환이란?
- 옵티마이저가 SQL을 분석해 의미적으로 동일(결과가 동일)하면서도 더 나은 성능이 기대되는 형태로 SQL을 재작성하는 것
- 실행계획 생성/비용 산정 전에 SQL을 최적화에 유리한 형태로 재작성
- 옵티마이저의 sub엔진중에 하나인 Query Transformer가 담당
✅ 옵티마이저의 SQL 최적화 과정 (비용기반 옵티마이저 기준)
- Parser : SQL문장을 이루는 개별 구성요소를 분석하고 파싱해서 파싱 트리를 만든다.
( Syntax(문법), Semantic(의미) ) - Query Transformer(옵티마이저) : 파싱된 SQL을 좀 더 일반적이고 표준적인 형태로 변환
- Estimator(옵티마이저) : 오브젝트 및 시스템 통계정보를 이용해 쿼리 수행 각 단계의 선택도, 카디널리티, 비용을 계산하고, 궁극적으로는 실행계획 전체에 대한 총비용을 계산
- Plan Generator(옵티마이저) : 하나의 쿼리를 수행하는데 있어, 후보군이 될만한 실행계획들을 생성
- Row-Source Generator : 옵티마이저가 생성한 실행계획을 SQL 엔진이 실제 실행할 수 있는 코드(또는 프로시저) 형태로 포맷팅
- SQL Engine : SQL을 실행
- Parser : SQL문장을 이루는 개별 구성요소를 분석하고 파싱해서 파싱 트리를 만든다.
(2) 쿼리변환 종류
1. 휴리스틱(Heuristic) 쿼리 변환
- 결과만 보장된다면 무조건 쿼리 변환을 수행
- 일종의 규칙 기반 최적화 기법
2.비용기반(Cost-based) 쿼리 변환
- 변환된 쿼리의 비용이 더 낮을 때만 수행
[2] 서브쿼리 unnesting
- 중첩된 서브쿼리를 메인 쿼리와 같은 레벨로 풀어내는 것
- 다양한 액세스 경로와 조인 메소드를 평가한다.
- 옵티마이저는 많은 조인 테크닉을 가지기 때문에 조인 형태로 변환했을 때 더 나은 실행계획을 찾을 가능성이 높아짐
(1) 서브쿼리
- 중첩된 서브쿼리는 관계가 종속적-계층적 이다.
- 논리적인 관점에서는 메인쿼리에서 읽히는 레코드마다 서브쿼리를 반복 수행해야하지만
이와 같은 필터방식이 속도를 보장하지 못한다.
옵티마이저의 필터 방식 대안
서브쿼리 unnesting
- 동일한 결과를 보장하는 조인문으로 변환 하고나서 최적화
- 메인쿼리와 서브쿼리가 M:1관계이고 서브쿼리 컬럼이 PK/Unique 컬럼일때 일반 조인문으로 바꿔도 결과가 보장됨
select * from employees where department_id in ( select department_id from departments);
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106 | 7632 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 106 | 7632 | 3 (0)| 00:00:01
| 2 | TABLE ACCESS FULL| EMPLOYEES | 107 | 7276 | 3 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN| DEPT_ID_PK | 1 | 4 | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DEPARTMENT_ID"="DEPARTMENT_ID")filter
- 서브쿼리를 unnesting하지 않고 원상태에서 최적화
- 메인쿼리와 서브쿼리 각각 최적화. 이때 서브쿼리에 필터 오퍼레이션이 나타난다.
select * from employees where department_id in ( select /*+ no_unnest */ department_id from departments);
------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 680 | 3 (0)| 00:00:01
|* 1 | FILTER | | | | |
| 2 | TABLE ACCESS FULL| EMPLOYEES | 107 | 7276 | 3 (0)| 00:00:01
|* 3 | INDEX UNIQUE SCAN| DEPT_ID_PK | 1 | 4 | 0 (0)| 00:00:01
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "DEPARTMENTS"
"DEPARTMENTS" WHERE "DEPARTMENT_ID"=:B1))(2) 서브쿼리 unnesting과 관련된 힌트(오라클)
- unnest : 서브쿼리를 unnesting함으로 조인방식으로 최적화 유도
- no_unnest : 서브쿼리를 그대로 둔 상태에서 필터 방식으로 최적화
(3) 상황에 따른 서브쿼리 Unnesting (in절)
1. 서브쿼리가 M쪽 집합이거나 서브쿼리 컬럼이 Nonunique인덱스일 때
- 일반 조인문 형태로 변환할경우 M쪽 집합인 emp 테이블 단위의 결과집합이 생성되므로 오류
- 서브쿼리에 모든 값이 다 있어야 되는 게 아니다.
- 다만 유니크한 값으로 이루어져있어야한다는 거 ! 안그러면 조인할때 막 두개세개씩 생기니깐!
select * from dept where deptno in (select deptno from emp);
select * from (select deptno from emp) a, dept b where a.deptno = b.deptno;2. PK/Unique 제약 또는 Unique 인덱스가 없는 서브쿼리 쪽 테이블이 먼저 드라이빙되는 경우
- 먼저 Sort unique 오퍼레이션을 수행함으로써 1쪽 집합으로 만든 다음에 조인한다.
select * from emp where deptno in (select deptno from dept) ;3. 메인 쿼리 쪽 테이블이 드라이빙된다면 세미 조인( Semi Join ) 방식으로 조인한다.
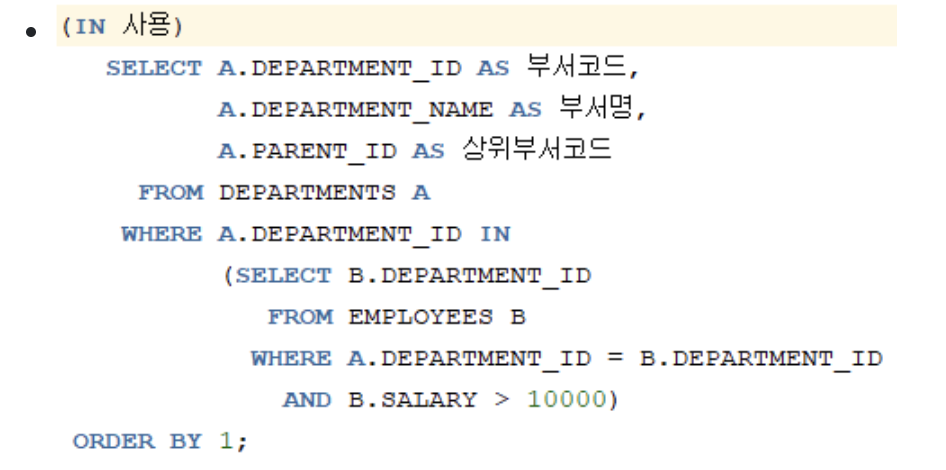
- 세미 조인(Semi Join) : 서브쿼리를 사용하여 서브쿼리에 존재하는 데이터만 메인쿼리에서 추출하는 조인
- 세미 조인(Semi Join)이 탄생하게 된 배경이다.
4. 서브쿼리 컬럼(deptno)이 PK/Unique제약이나 Unique인덱스가 없을경우
select * from emp where deptno in (select deptno from dept) ;- emp와 dept간의 관계를 알수없기 때문에 일반 조인문으로 쿼리 변환을 시도 하지 않음.
5. exists 서브쿼리의 캐싱효과
- exists 서브쿼리가 NL 세미 조인이나 필터방식으로 처리된다면 거기서도 캐싱 효과 발생한다.
- exists 서브쿼리는 unnesting 하지 않으면 , 서브쿼리에 대한 캐싱 기능이 작동한다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’