[1] 인덱스 구조
(1) 인덱스 탐색
1. 수직적 탐색
- 수평적 탐색을 위한 시작 지점을 찾는 과정
- 루트에서 리프 블록까지 아래쪽으로 진행
2.수평적 스캔
- 인덱스 리프 블록에 저장된 레코드끼리 연결된 순서에 따라 좌에서 우, 또는 우에서 좌로 스캔
[2] 다양한 인덱스 스캔방식
(1) Index Range Scan
- 인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후에 리프 블록을 필요한 범위(Range)만 스캔하는 방식
- B*Tree 인덱스의 장 일반적이고 정상적인 형태의 액세스 방식
- Index Range Scan 실행계획
Execution Plan ------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE)
2 1 INDEX (RANGE SCAN) OF 'EMP_DEPTNO_IDX' (INDEX)(2) Index Full Scan
- 수직적 탐색없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식
- 대개는 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택
- Index Full Scan 실행계획
Execution Plan ----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE)
2 1 INDEX (FULL SCAN) OF 'EMP_IDX' (INDEX)1. Index Full Scan의 효용성
- 인덱스 선두 칼럼(ename)이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려
- 대용량 테이블이어서 Table Full Scan의 부담이 크다면 ?
- 데이터 저장공간은 ‘가로×세로’ 즉, ‘칼럼길이×레코드수’에 의해 결정되므로
대개 인덱스가 차지하는 면적은 테이블보다 훨씬 적게 마련
연봉이 5,000을 초과하는 사원이 전체 중 극히 일부라면?
- 만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하는 경우
=> 옵티마이저는 Index Full Scan 방식을 선택한다.
인덱스를 이용한 소트 연산을 대체하는 경우
- Index Full Scan은 Index Range Scan과 마찬가지로 그 결과집합이 인덱스 칼럼 순으로 정렬된다.
=> Sort Order By 연산을 생략할 목적으로 사용될 수도 있다.
SQL> select /*+ first_rows */ * from emp where sal > 1000 order by ename;
Execution Plan --------------------------------------------------
0 SELECT STATEMENT Optimizer=HINT: FIRST_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE)
2 1 INDEX (FULL SCAN) OF 'EMP_IDX' (INDEX)- 대부분 사원의 연봉이 1,000을 초과하므로 Index Full Scan을 하면 거의 모든 레코드에 대해 테이블 액세스가 발생한다. 따라서 Table Full Scan 보다 오히려 불리하다.
- 만약 SAL이 인덱스 선두 칼럼이어서 Index Range Scan 하더라도 마찬가지다.그럼에도 여기서 인덱스가 사용된 것은 사용자가 first_rows 힌트를 이용해 옵티마이저 모드를 바꾸었기 때문이다.
- 소트 연산을 생략함으로써 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 Index Full Scan 방식이 선택되었다.
- 사용자가 그러나 처음 의도와 다르게 데이터 읽기를 멈추지 않고 끝까지 fetch 한다면 Full Table Scan한 것보다 훨씬 더 많은 I/O를 일으키면서 서버 자원을 낭비하게 된다.
(3) Index Unique Scan
- 수직적 탐색만으로 데이터를 찾는 스캔 방식
- Unique 인덱스를 ‘=’ 조건으로 탐색하는 경우에 작동
- Index Unique Scan 실행계획
SQL> select empno, ename from emp where empno = 7788;
Execution Plan -----------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (UNIQUE SCAN) OF 'PK_EMP' (UNIQUE)(4) Index Skip Scan
- 인덱스 선두 칼럼이 조건절에 빠졌어도 인덱스를 활용하는 새로운 스캔방식(Oracle 9i버전 이상)
- 인덱스 선두 칼럼이 조건절로 사용되지 않으면 옵티마이저는 기본적으로 Table Full Scan을 선택한다.
- 또는, Table Full Scan보다 I/O를 줄일 수 있거나 정렬된 결과를 쉽게 얻을 수 있다면 Index Full Scan 방식을 사용한다.
- Index Skip Scan 실행계획 : 성별과 연봉 두 칼럼으로 구성된 결합 인덱스에서 선두 칼럼인 성별 조건이 빠진 SQL문이 Index Skip Scan 방식으로 수행될 때
SQL> select * from 사원 where 연봉 between 2000 and 4000;
Execution Plan --------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF '사원' (TABLE)
2 1 INDEX (SKIP SCAN) OF '사원_IDX' (INDEX)1. Index Skip Scan 내부 수행원리
- 루트 또는 브랜치 블록에서 읽은 칼럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 “가능성이 있는”
하위 블록(브랜치 또는 리프 블록)만 골라서 액세스하는 방식 - 조건절에 빠진 인덱스 선두 칼럼의 Distinct Value 개수가 적고 후행 칼럼의 Distinct Value 개수가 많을 때 유용하다.
2. Index Skip Scan 대안 : In-List
- Index Skip Scan에 의존하는 대신, 아래와 같이 성별 값을 In-List로 제공하는 방식
- INLIST ITERATOR라고 표시된 부분 => 조건절 In-List에 제공된 값의 종류만큼 인덱스 탐색을 반복 수행
- 직접 성별에 대한 조건식을 추가해 주면 Index Skip Scan에 의존하지 않고도 빠르게 결과집합을 얻을 수 있다.
단, 효과를 발휘하려면 In-List로 제공하는 값의 종류가 적어야 한다.
SQL> select * from 사원 where 연봉 between 2000 and 4000 and 성별 in ('남', '여')
Execution Plan --------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 INLIST ITERATOR
2 1 TABLE ACCESS (BY INDEX ROWID) OF '사원' (TABLE)
3 2 INDEX (RANGE SCAN) OF '사원_IDX' (INDEX)(5) Index Fast Full Scan
- Index Full Scan보다 빠르다.
- Index Fast Full Scan이 Index Full Scan보다 빠른 이유
=> 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔
(6) Index Range Scan Descending
- 인덱스를 뒤에서부터 앞쪽으로 스캔하기 때문에 내림차순으로 정렬된 결과집합을 얻는다.
SQL> select * from emp where empno is not null order by empno desc
Execution Plan -------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE)
2 1 INDEX (RANGE SCAN DESCENDING) OF 'PK_EMP' (INDEX (UNIQUE))- max 값을 구하고자 할 때도 해당 칼럼에 인덱스가 있으면 인덱스를 뒤에서부터 한 건만 읽고 멈추는 실행계획이 자동으로 수립된다.
SQL> create index emp_x02 on emp(deptno, sal);
SQL> select deptno, dname, loc 2 ,(select max(sal) from emp where deptno = d.deptno) 3 from dept d
Execution Plan -------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 SORT (AGGREGATE)
2 1 FIRST ROW
3 2 INDEX (RANGE SCAN (MIN/MAX)) OF 'EMP_X02' (INDEX)
4 0 TABLE ACCESS (FULL) OF 'DEPT' (TABLE)[3] 인덱스 종류
(1) B*Tree 인덱스
- 맨 위쪽 뿌리(Root)에서부터 가지(Branch)를 거쳐 맨 아래 나뭇잎(Leaf)까지 연결되는 구조
1. 인덱스 깊이(Height)
- 루트에서 리프 블록까지의 거리
- 인덱스를 반복적으로 탐색할 때 성능에 영향을 미침
2. 루트와 브랜치 블록
- 각 하위 노드들의 데이터 값 범위를 나타내는 키 값과, 그 키 값에 해당하는 블록을 찾는 데 필요한 주소 정보를 가진다.
3. 리프 블록
- 인덱스 키 값과, 그 키 값에 해당하는 테이블 레코드를 찾아가는 데 필요한 주소 정보(ROIWD)를 가진다.
- 키 값이 같을 때는 ROWID순으로 정렬된다.
- 항상 인덱스 키(Key) 값 순으로 정렬되어 ‘범위 스캔(Range Scan, 검색조건에 해당하는 범위만 읽다가 멈추는 것을 말함)’이 가능하다.
- 정방향과 역방향 스캔이 둘 다 가능하도록 양방향 연결 리스트 구조로 연결되어있다.
4. null인 레코드는 인덱스에 저장하지 않는다.
- Oracle에서 인덱스 구성 칼럼이 모두 null인 레코드는 인덱스에 저장하지 않는다.
- 인덱스 구성 칼럼 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장된다.
- null 값을 Oracle은 맨 뒤에 저장한다.
5. B*Tree 인덱스 구조에서 나타날 수 있는 Index Fragmentation
- Unbalanced Index
- delete 작업 때문에 인덱스가 불균형 상태에 놓일 수 있다.
- 즉 다른 리프 노드에 비해 루트 블록과의 거리가 더 멀거나 가까운 리프 노드가 생길 수 있다는 것인데,
B*Tree 구조에서 이런 현상은 절대 발생하지 않는다.
- Index Skew
- 불균형은 생길 수 없지만 Index Fragmentation에 의한 Index Skew 또는 Sparse 현상이 생기는 경우는 종종 있고, 이는 인덱스 스캔 효율에 나쁜 영향을 미칠 수 있다.
- 인덱스 엔트리가 왼쪽 또는 오른쪽에 치우치는 현상이 보인다.
- 예를 들어, 아래와 같이 대량의 delete 작업을 마치고 나면 인덱스 왼쪽에 있는 리프 블록들은 텅 비는 반면 오른쪽은 꽉 찬 상태가 된다. - Index Skew 발생 예시
SQL> create table t as select rownum no from big_table where rownum <= 1000000 ;
SQL> create index t_idx on t(no) ;
SQL> delete from t where no <= 500000 ;
SQL> commit;- 텅 빈 인덱스 블록은 커밋하는 순간 freelist로 반환되지만 인덱스 구조 상에는 그대로 남는다.
- 상위 브랜치에서 해당 리프 블록을 가리키는 엔트리가 그대로 남아 있어 인덱스 정렬 순서상 그 곳에 입력될 새로운 값이 들어오면 언제든 재사용될 수 있다.
- 새로운 값이 하나라도 입력되기 전 다른 노드에 인덱스 분할이 발생하면 그것을 위해서도 이들 블록이 재사용된다.
- 이때는 상위 브랜치에서 해당 리프 블록을 가리키는 엔트리가 제거된다.- 다른 쪽 브랜치의 자식 노드로 이동하고, freelist에서도 제거된다.
- 레코드가 모두 삭제된 블록은 이처럼 언제든 재사용 가능하지만, 문제는 다시 채워질 때까지 인덱스 스캔 효율이 낮다.
- SQL Server에선 Index Skew 현상이 발생하지 않는다.
- 주기적으로 B*Tree 인덱스를 체크함으로써 지워진 레코드와 페이지를 정리해 주는 메커니즘을 갖기 때문이다.
- 인덱스 레코드를 지우면 리프페이지에서 바로 제거되는 것이 아니라 'Ghost 레코드’로 마크(mark)되었다가 이를 정리해 주는 별도 쓰레드에 의해 비동기 방식으로 제거한다.- 이 과정에서 텅 빈 페이지가 발견되면 인덱스 구조에서 제거된다.
- Index Sparse
- 인덱스 블록 전반에 걸쳐 밀도가 떨어지는 현상
- 예를 들어, 아래와 같은 형태로 delete 작업을 수행하고 나면 t_idx 블록의 밀도는 50% 정도 밖에 되질 않는다.
- 100만 건 중 50만 건을 지우고 나서도 스캔한 인덱스 블록 수가 똑같이 2,001개인 것을 확인할 수 있다.
- 지워진 자리에 인덱스 정렬 순서에 따라 새로운 값이 입력되면 그 공간은 재사용되지만 위와 같은 대량의 delete 작업이 있고 난 후 한동안 인덱스 스캔 효율이 낮다.
- 왼쪽, 오른쪽, 중간 어디든 Index Skew처럼 블록이 아예 텅 비면 곧바로 freelist로 반환돼 언제든 재사용이 가능하다.
- Index Sparse는 지워진 자리에 새로운 값이 입력되지 않으면 영영 재사용되지 않을 수도 있다.
- 총 레코드 건수가 일정한데도 인덱스 공간 사용량이 계속 커지는 것은 대개 이런 현상에 기인한다.
- 인덱스 재생성
- Fragmentation 때문에 인덱스 크기가 계속 증가하고 스캔 효율이 나빠지면 인덱스를 재생성하거나 DBMS가 제공하는 명령어를 이용해 빈 공간을 제거하는 것이 유용하다.
- 인덱스 블록에는 어느 정도 공간을 남겨두는 것이 좋다.
- 빈 공간을 제거해 인덱스 구조를 슬림(slim)화하면 저장 효율이나 스캔 효율엔 좋겠지만 인덱스 분할이 자주 발생해 DML 성능이 나빠질 수 있기 때문이다. - 인덱스 분할에 의한 경합을 줄일 목적으로, 초기부터 빈 공간을 남기도록 옵션을 주고 인덱스를 재성성할 수도 있다.
- 하지만 그 효과는 일시적이다. 언젠가 빈 공간이 다시 채워지기 때문! - 결국 적당한 시점마다 재생성 작업을 반복하지 않는 한 근본적인 해결책이 되지는 못한다.
- 인덱스를 재생성하는 데 걸리는 시간과 부하도 무시할 수 없다.
- 인덱스의 주기적인 재생성 작업은 아래와 같이 예상효과가 확실할 때만 시행하는 것이 바람직하다.
- 자주 사용되는 인덱스 스캔 효율을 높이고자 할 때. 특히 NL Join에서 반복 액세스되는 인덱스 높이(height)가 증가했을 때
- 인덱스 분할에 의한 경합이 현저히 높을 때
- 대량의 delete 작업을 수행한 이후 다시 레코드가 입력되기까지 오랜 기간이 소요될 때
- 총 레코드 수가 일정한데도 인덱스가 계속 커질 때
(2) 비트맵 인덱스
- 읽기 위주의 대용량 DW(특히, OLAP) 환경에 아주 적합
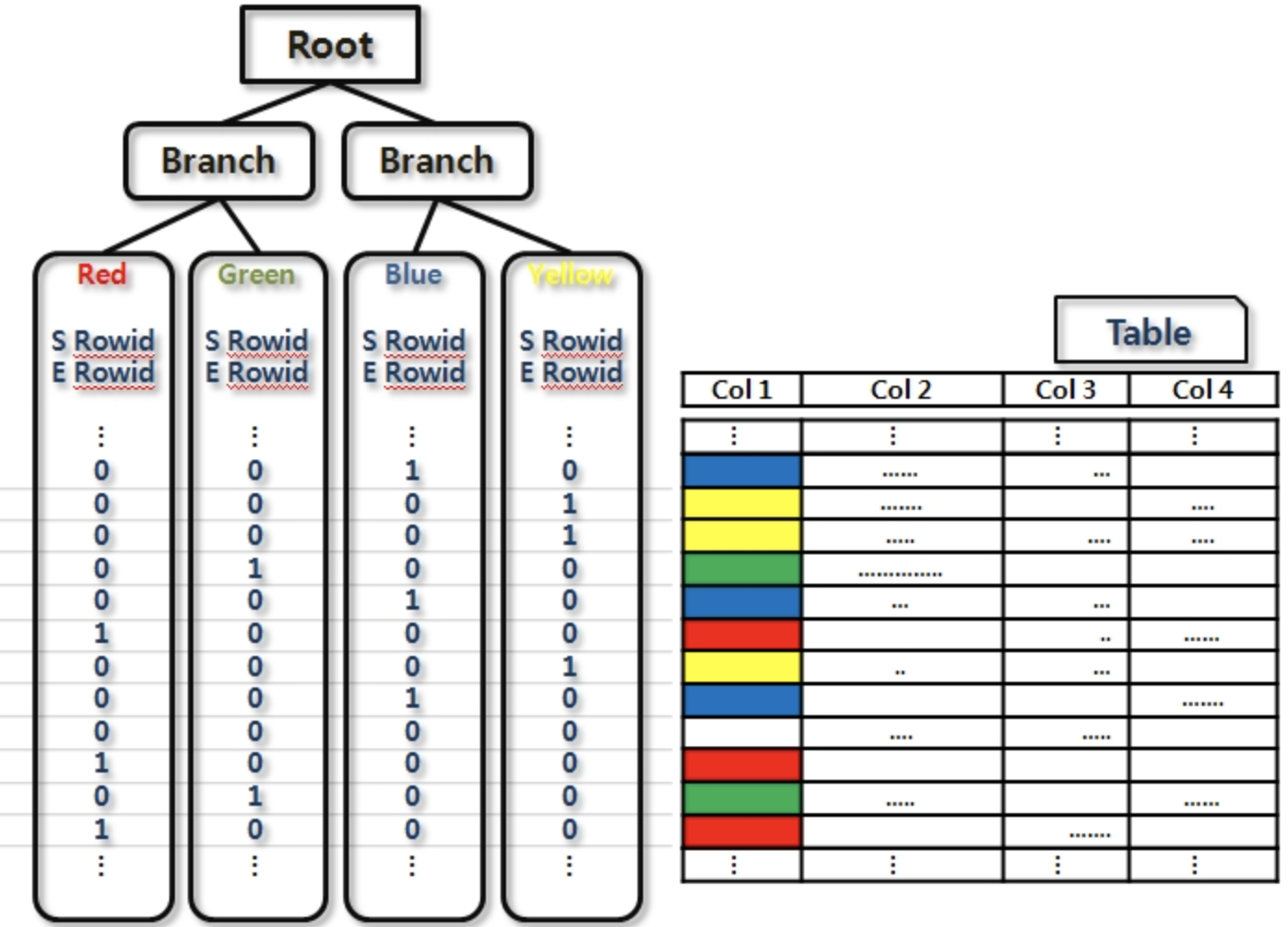
1. Distinct Value 개수
적을 때
- 칼럼의 Distinct Value 개수가 적을 때 비트맵 인덱스를 사용하면 저장효율이 매우 좋다.
- B*Tree 인덱스보다 훨씬 적은 용량을 차지하므로 인덱스가 여러 개 필요한 대용량 테이블에 유용하다.
- 다양한 분석관점(Dimension)을 가진 팩트성 테이블이 주로 여기에 속한다.
많을 때
- 반대로 Distinct Value가 아주 많은 칼럼이면 오히려 B*Tree 인덱스보다 많은 공간을 차지한다.
- Distinct Value 개수가 적은 칼럼일 때 저장효율이 좋지만 테이블 Random 액세스 발생 측면에서는 B*Tree 인덱스와 똑같기 때문에 그런 칼럼을 비트맵 인덱스로 검색하면 그다지 좋은 성능을 기대하기 어렵다.
2. 이점
- 스캔할 인덱스 블록이 줄어드는 정도의 성능 이점만 얻을 수 있다. 따라서 하나의 비트맵 인덱스 단독으로는 쓰임새가 별로 없다.
- 여러 비트맵 인덱스를 동시에 사용할 수 있는 특징 때문에 대용량 데이터 검색 성능을 향상시키는 데에 효과가 있다.
- 예컨대, 여러 개 비트맵 인덱스로 Bitwise 연산을 수행한 결과, 테이블 액세스량이 크게 줄어든다면 큰 성능 개선을 기대할 수 있다.
select 지역, sum(판매량), sum(판매금액)
from 연도별지역별상품매출
where (크기 = 'SMALL' or 크기 is null)
and 색상 = 'GREEN'
and 출시연도 = '2010' group by 지역;- 비트맵 인덱스는 여러 인덱스를 동시에 활용할 수 있다는 장점이 있다.
- 다양한 조건절이 사용되는, 특히 정형화되지 않은 임의 질의(ad-hoc query)가 많은 환경에 적합하다.
3. OLTP성 환경에 비트맵 인덱스를 쓸 수 없는 이유
- Lock에 의한 DML 부하가 심한 것이 단점이다.
- 레코드 하나만 변경되더라도 해당 비트맵 범위에 속한 모든 레코드에 Lock이 걸린다.
(3) 함수기반 인덱스
- 칼럼 값 자체가 아닌, 칼럼에 특정 함수를 적용한 값으로 B*Tree 인덱스를 만든다.
create index emp_x01 on emp( nvl(주문수량, 0) );
select * from 주문 where nvl(주문수량, 0) < 100;- 주문수량 칼럼에 인덱스가 있어도 위처럼 인덱스 칼럼을 가공하면 정상적인 인덱스 사용이 불가능하다.
하지만 조건절과 똑같이 NVL 함수를 씌워 아래 처럼 인덱스를 만들면 인덱스 사용이 가능하다. - 주문수량이 NULL인 레코드는 인덱스에 0으로 저장된다.
1. 함수기반 인덱스가 유용한 가장 흔한 사례
- 대소문자를 구분해서 입력 받은 데이터를 대소문자 구분 없이 조회할 때 :: upper(칼럼명) 함수를 씌워 인덱스를 생성하고 upper(칼럼명) 조건으로 검색하는 것.
2. 사용시 유의할 점
- 함수기반 인덱스는 데이터 입력, 수정 시 함수를 적용해야 하기 때문에 다소 부하가 있을 수 있으며, 사용된 함수가 사용자 정의 함수일 때는 부하가 더 심하다. 따라서 꼭 필요한 때만 사용.
(4) 리버스 키 인덱스
create index 주문_x01 on 주문( reverse(주문일시) );- 입력된 키 값을 거꾸로 변환해서 저장하는 인덱스
- 함수기반 인덱스를 상기하면서, 아래와 같이 reverse 함수에서 반환된 값을 저장하는 인덱스라고 생각하면 쉽다.
1. 리버스 키 인덱스의 사용 배경
- 일련번호나 주문일시 같은 칼럼에 인덱스를 만들면, 입력되는 값이 순차적으로 증가하며 가장 오른쪽 리프 블록에만 데이터가 쌓인다.(‘Right Growing(또는 Right Hand) 인덱스’ 현상)
- 동시 INSERT가 심할 때 인덱스 블록 경합을 일으켜 초당 트랜잭션 처리량을 크게 감소시킨다. - 순차적으로 입력되는 값을 거꾸로 변환해서 저장하면 데이터가 고르게 분포한다.
- 따라서 리프 블록 맨 우측에만 집중되는 트랜잭션을 리프 블록 전체에 고르게 분산시키는 효과가 생김.
2. 단점
- 리버스 키 인덱스는 데이터를 거꾸로 입력하기 때문에 ‘=’ 조건으로만 검색이 가능하다.
- 즉, 부등호나 between, like 같은 범위검색 조건에는 사용할 수 없다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’