
FourChak
정리 된 링크 및 파일
- 깃허브 링크
https://github.com/YejinY00n/FourChak.git - 트러블 슈팅
https://rudtjs2.tistory.com/50
https://velog.io/@soonch6/최적화Indexing
https://velog.io/@todok0317/Redis-캐시-도입기-검색-속도-개선을-위한-성능-최적화-트러블슈팅
https://velog.io/@todok0317/Jenkins-기반-CICD-구축-시도-및-트러블슈팅
https://velog.io/@yoon17710/MySQL-기반-분산락-구현-트러블슈팅-요약
최종본 : https://velog.io/@todok0317/FourChak-프로젝트-통합-트러블슈팅2 - 시연 영상 링크
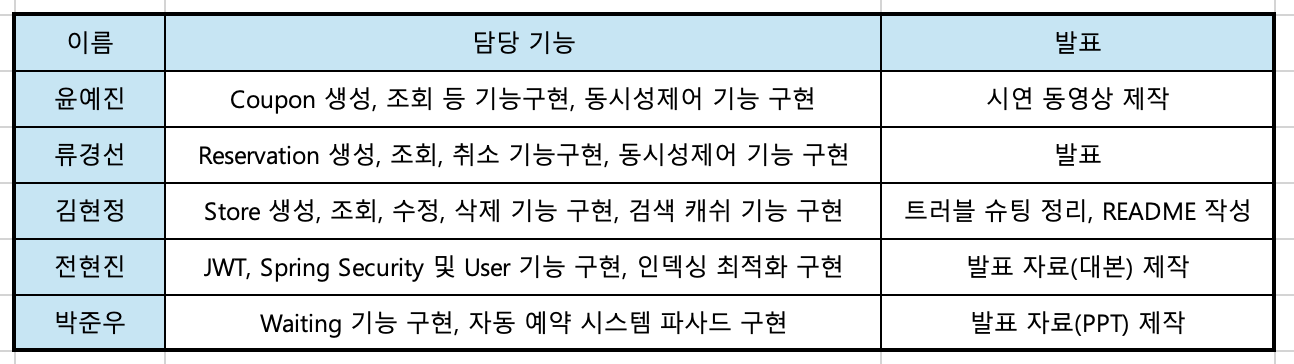
팀원 및 역할
프로그램 설명
FourChak은 4조가 만든 좌석에 착하고 앉는 예약 프로그램으로 FourChak입니다.
FourChak은 사용자가 원하는 식당을 검색하고 실시간으로 예약 할 수 있도록 도와주는 식당 예약 플랫폼입니다. 실시간 예약 시스템을 통해 빠르고 편리한 외식 예약을 할 수 있게 구현하였습니다.
주요 구현 기능
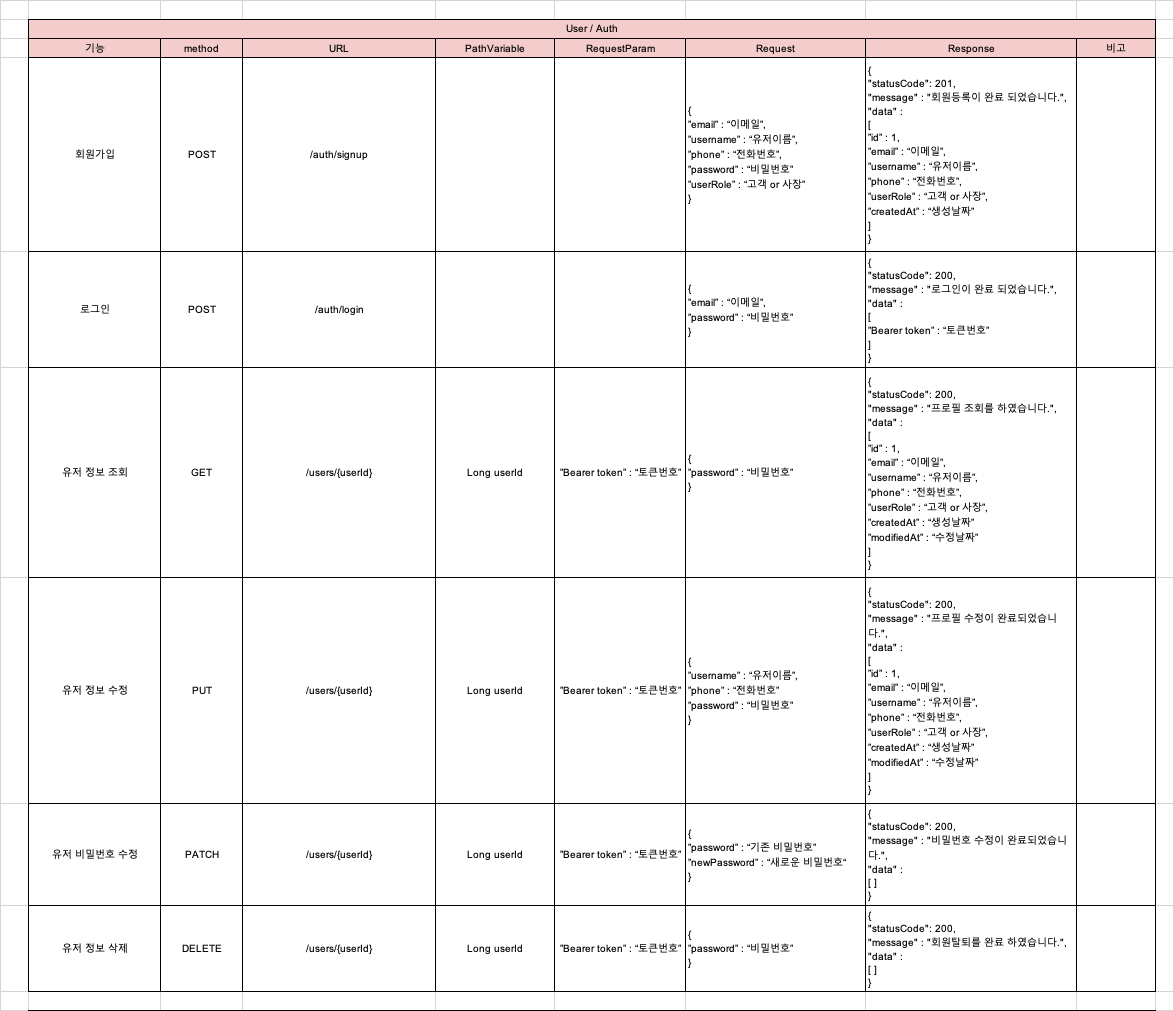
1. 회원가입/로그인
- 이메일 형식 아이디 + 영문 대소문자/숫자 조합 8자 이상 비밀번호로 회원가입
- JWT를 활용한 인증 방식 구현
- 가입 시 USER(일반 사용자) / OWNER(가게 소유자) 역할 선택
- 회원 정보 수정 (이름, 전화번호) 및 비밀번호 변경 기능
- 회원 탈퇴 시 소프트 딜리트 처리
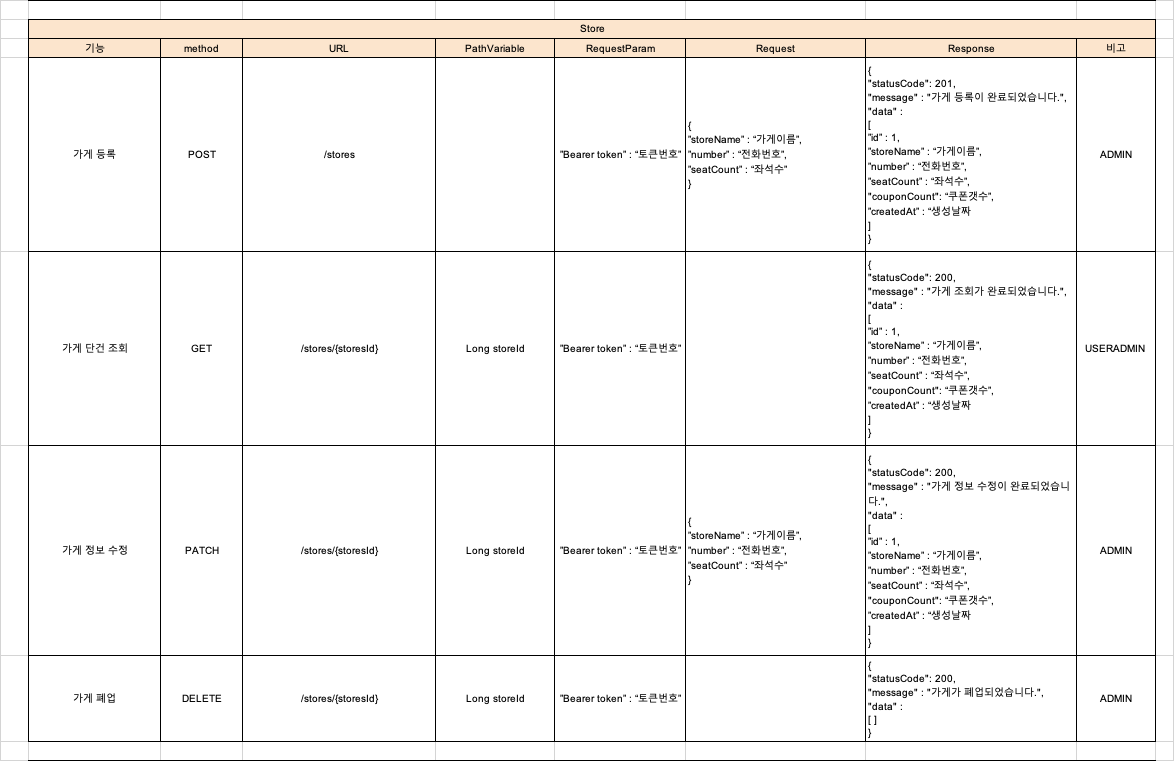
2. 가게 관리
- OWNER 권한을 가진 사용자만 가게 등록 가능
- 가게 정보 (이름, 전화번호, 좌석 수) 관리
- 가게 조회 시 남은 좌석 수 실시간 확인 가능
- 가게 폐업 처리 (소프트 딜리트)
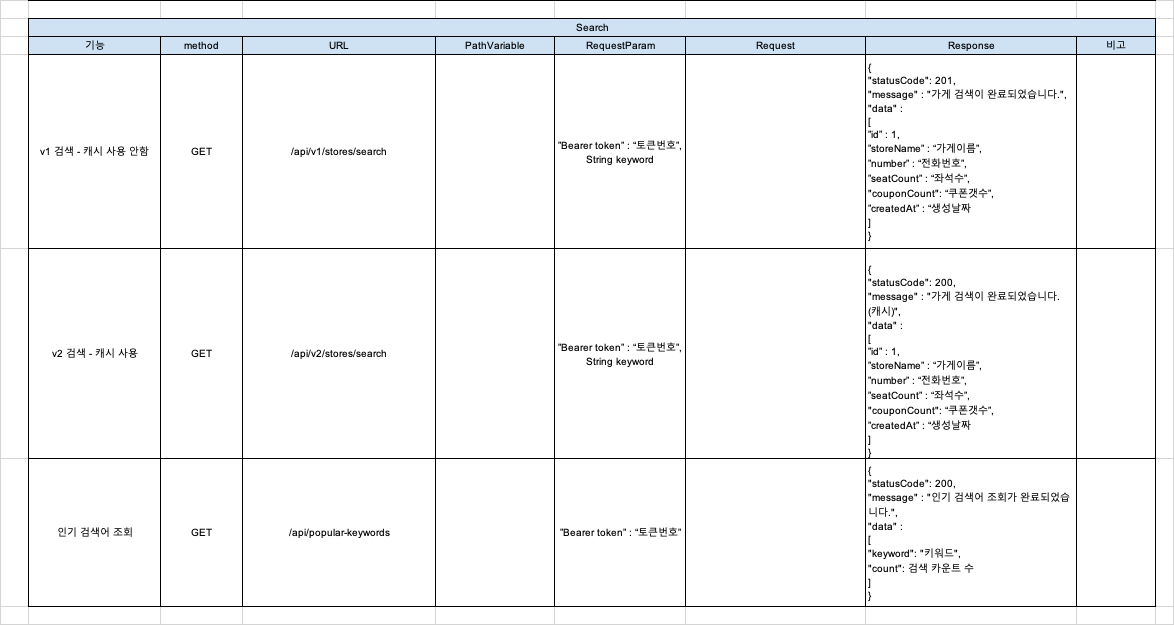
- 가게 검색 기능 (이름 기준 LIKE 검색)
- 인기 검색어 기능 (검색 횟수 기준 상위 10개)
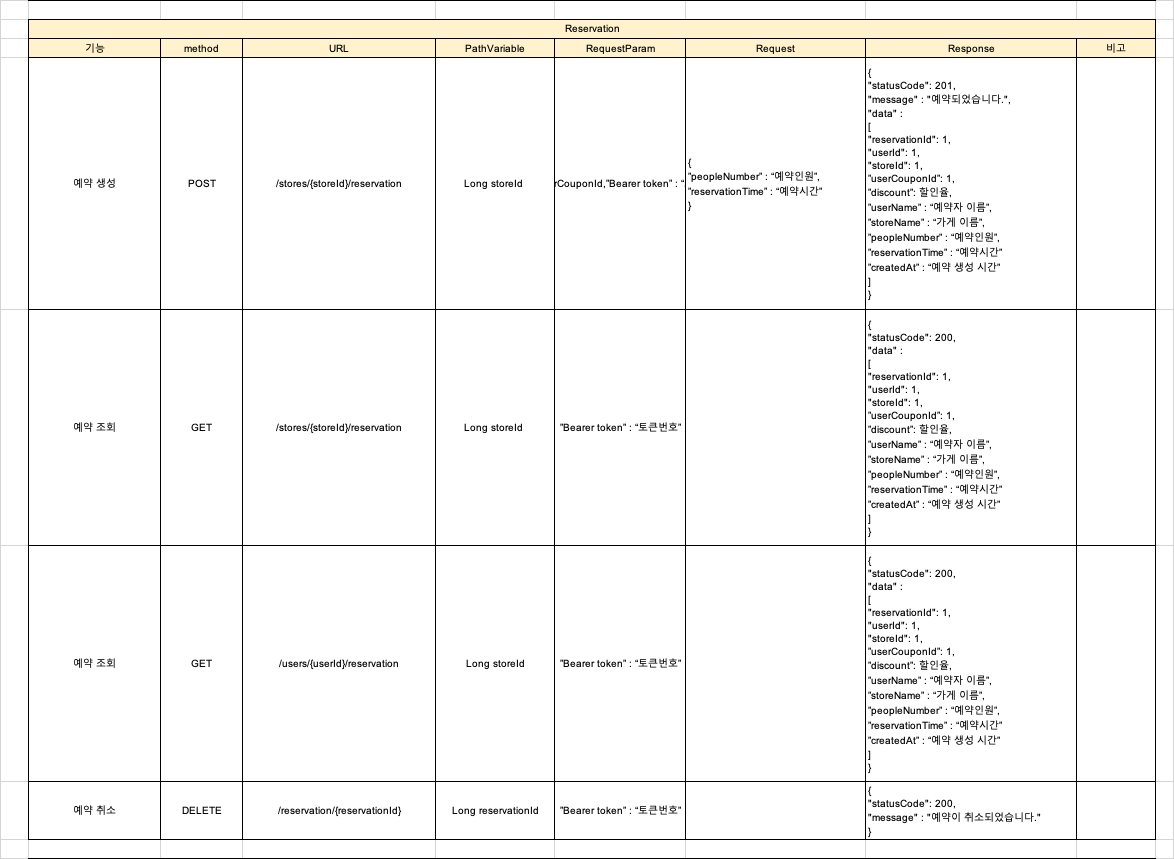
3. 예약 시스템
- 사용자는 원하는 시간과 인원 수로 가게 예약 가능
- 현재 가용 좌석 수에 따라 예약 가능 여부 실시간 확인
- 예약 시간이 지나면 자동으로 만료 처리
- 사용자별 예약 내역 조회
- 가게별 예약 내역 조회 (가게 소유자만 가능)
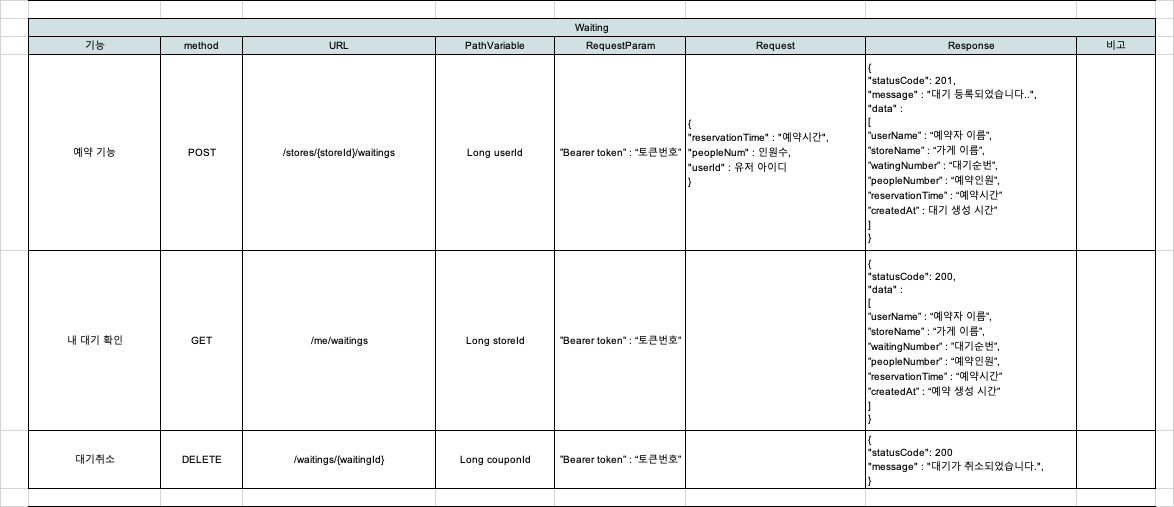
4. 대기 시스템
- 예약이 불가능한 경우 대기 등록 가능
- 대기 번호 자동 발급 및 상태 관리
- 사용자별 대기 내역 조회
- 대기 상태 변경 (대기 중, 입장 완료, 취소)
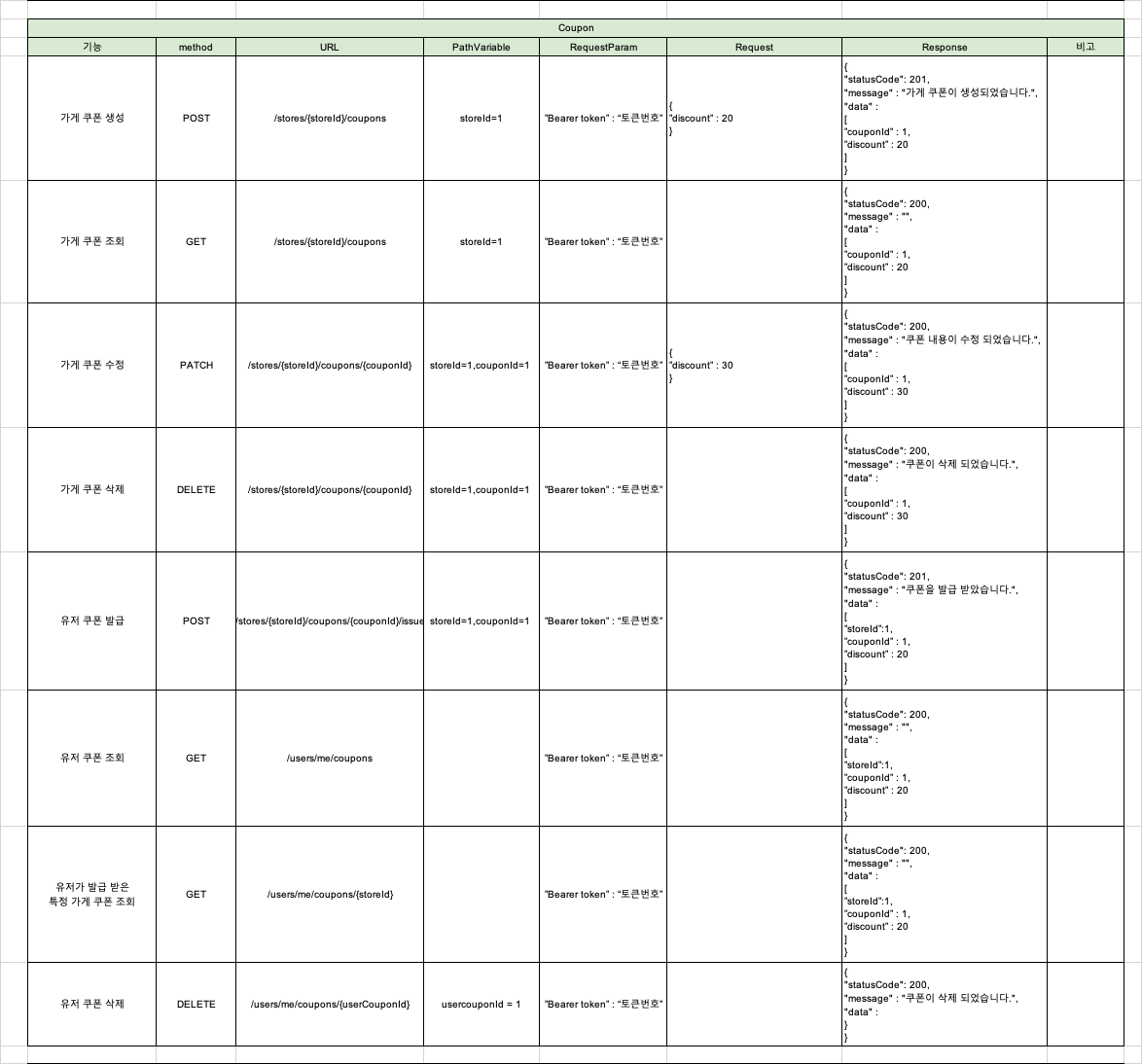
5. 쿠폰 시스템
- 가게 소유자는 할인 쿠폰 발행 가능
- 쿠폰 수량 및 할인율 설정
- 가게별 발행된 쿠폰 조회
6. 캐싱 성능 최적화
- 검색 API에 Local Memory Cache 적용
- Redis를 활용한 Remote Cache 구현
- 캐시 무효화 전략 적용
- 캐시 TTL 설정으로 데이터 일관성 유지
7. 보안 기능
- Spring Security 기반 인증/인가 구현
- JWT 토큰을 활용한 사용자 인증
- 비밀번호 암호화 저장
- API 엔드포인트별 권한 설정
8. 부가 기능
- 인기 검색어 순위 제공
- 시간대별 예약 현황 조회
- 사용자 활동 이력 관리
- 만료된 예약 자동 정리 배치 작업
기술적 포인트
1. JWT 기반 로그인 구현
- Spring Security와 JWT(Json Web Token)를 활용한 인증 시스템 구현
- Stateless한 구조로 세션 서버 부담 없이 사용자 인증 처리
- 사용자 로그인 시 JWT 발급, 이후 모든 요청에 헤더를 통해 인증 처리
2. Cache 검색 기능 구현
Redis 캐시 적용 배경
- 검색 특성: 동일 키워드 반복 검색 빈번
- DB 부하: LIKE 쿼리의 높은 비용
- 사용자 경험: 빠른 검색 응답 필요
캐시전략
// 검색 결과 캐싱 (5분 TTL)
@Cacheable(value = "storeSearch", key = "#keyword + '_' + #pageable.pageNumber + '_' + #pageable.pageSize")
public Page<StoreResponseDto> searchStoreWithCache(String keyword, Pageable pageable)
// 인기 검색어 캐싱 (30분 TTL)
@Cacheable(value = "popularKeywords")
public List<PopularKeywordResponseDto> getPopularKeywords()3. 동시성 제어
문제 상황
- 예약 요청이 동시에 집중될 경우 데이터 정합성 유지 필요
- 예: 동일 시간대에 같은 테이블에 대한 중복 예약 시도
해결 방법
- Redisson 분산 락 적용
- Redisson을 사용하여 락 획득/해제의 원자성 보장
- Lettuce보다 코드 간결하고 안정적인 락 처리 가능 - 트랜잭션보다 락이 먼저 해제되는 문제 예방
- 트랜잭션 격리 수준을 READ_COMMITTED로 설정하여 데이터 정합성 강화
4. 인덱싱
개념 요약
- 인덱스는 DB에서 데이터를 더 빠르게 조회할 수 있도록 돕는 저장 방식
- MySQL에서는 기본적으로 B+Tree 인덱스 사용
적용방식
- Entity 내에서 @Id 또는 @Column(unique = true) 어노테이션 활용
- 자주 검색되거나 정렬에 사용되는 컬럼에 인덱스를 적용하여 쿼리 성능 개선
5. CI/CD
목적
- 코드 변경 시 자동으로 빌드 및 배포되도록 하여 개발 효율성과 배포 안정성 향상
- 수동 배포로 인한 실수 및 반복 작업 최소화
Jenkins 기반 CI/CD 파이프라인 구축
- Jenkins가 프로젝트 변경 된 사항을 감지하여 ./gradlew build를 통해 .jar 파일 생성 (자동 빌드화)
서버 배포 (CD) -> 할 예정
- 빌드된 .jar 파일을 AWS EC2 서버에 전송 (scp)
- 기존 애플리케이션 종료 후 새 버전 실행 (pkill, nohup java -jar)
- 필요한 경우 Nginx 또는 도메인 설정 연동
기술 스택

- Java 17
- Spring Boot
- MySQL
- Redis
- Cache
- Spring Data JPA
- Postman (API 테스트용)
- JWT 기반 로그인, 인증/인가
- IntelliJ IDEA
- Lombok, Jakarta Validation
- GitHub
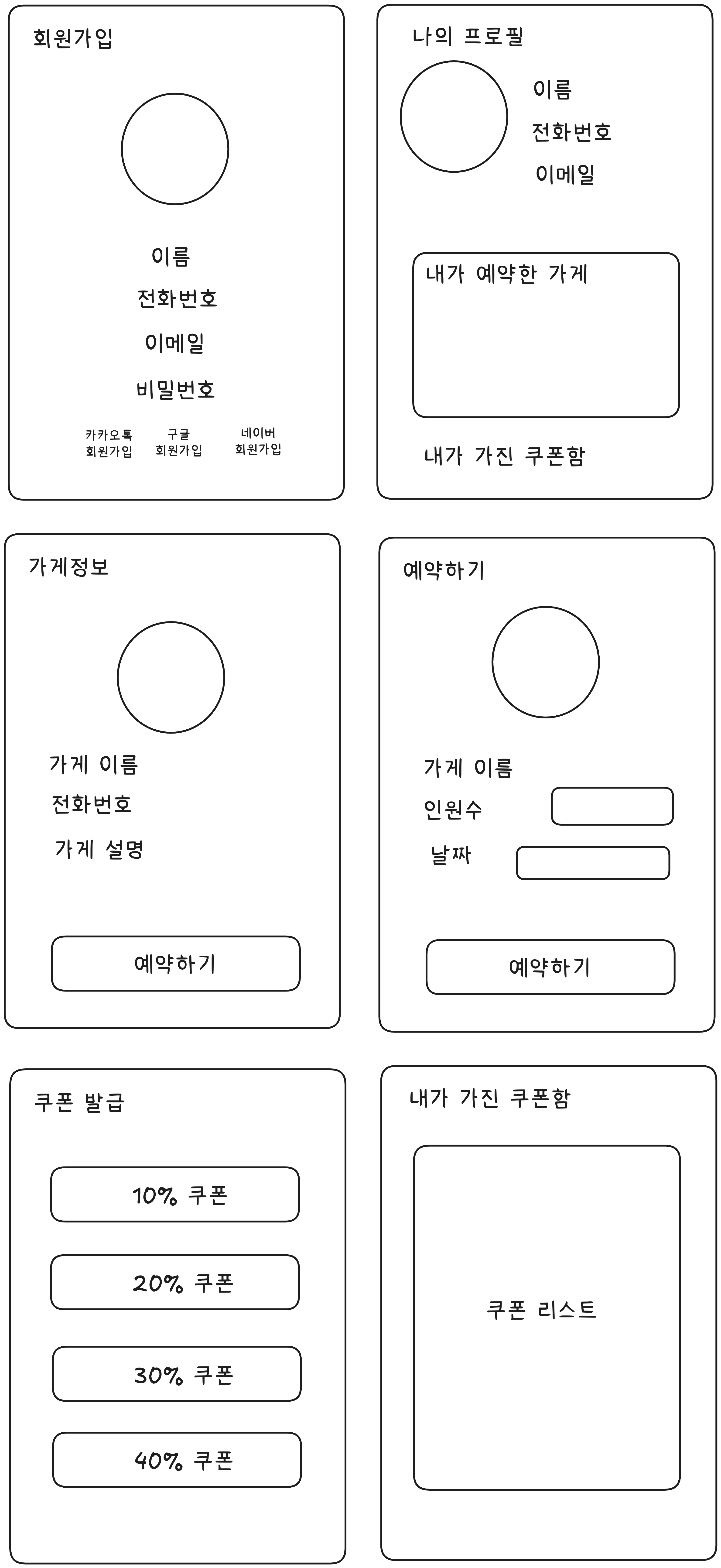
와이어 프레임
변수 선언표
연관관계
API 명세서
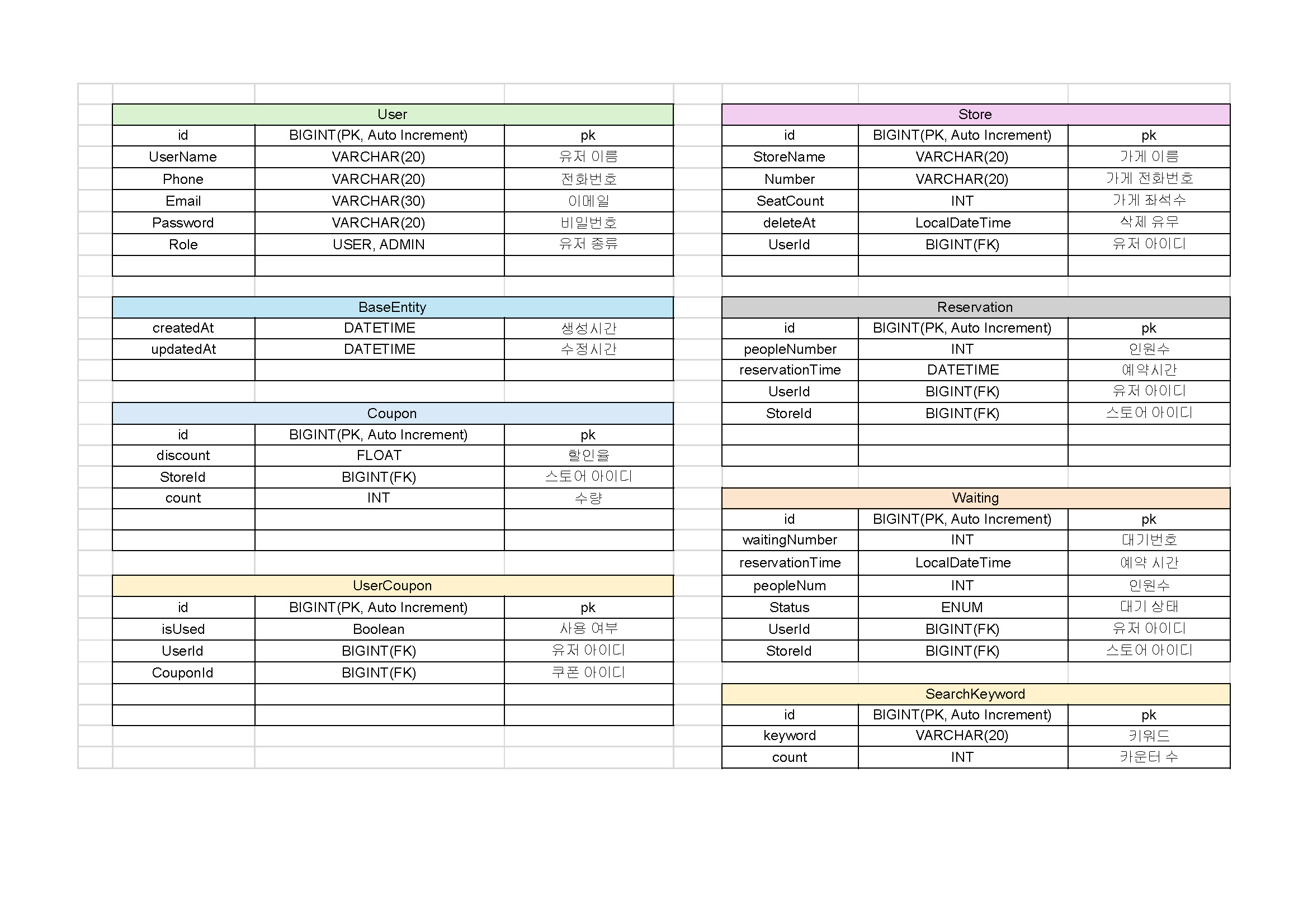
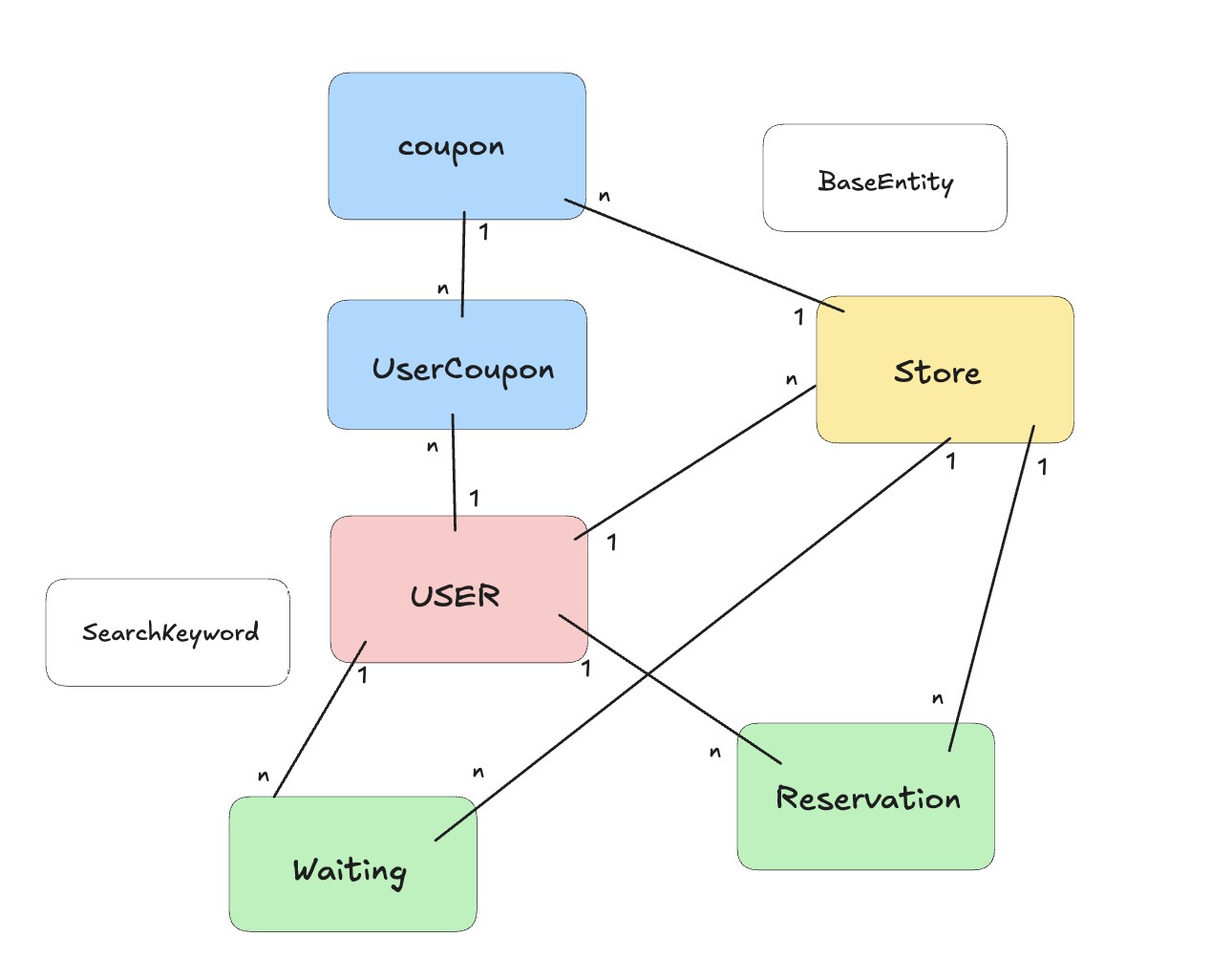
ERD 작성

SQL 작성
CREATE TABLE `store` (
`ID` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`storename` VARCHAR(10) NULL,
`number` VARCHAR(20) NULL,
`seatCount` INT NULL,
`deletedat` DATETIME NULL,
`userId` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK
);
CREATE TABLE `baseentity` (
`createdat` DATETIME NULL,
`modifiedat` DATETIME NULL
);
CREATE TABLE `user` (
`ID` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`email` VARCHAR(30) NULL,
`username` VARCHAR(20) NULL,
`phone` VARCHAR(20) NULL,
`password` VARCHAR(20) NULL,
`role` ENUM NULL
);
CREATE TABLE `Untitled2` (
`PK` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`FK` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`FK,` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`field 1` int NULL,
`field 2` DateTime NULL,
`field 3` Int NULL,
`field 4` ENUM NULL
);
CREATE TABLE `coupon` (
`id` BIGINT NOT NULL,
`ID` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`discount` INTEGER NULL,
`count` INTEGER NULL
);
CREATE TABLE `searchkeyword` (
`ID` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`keyword` VARCHAR(20) NULL,
`count` INT NULL
);
CREATE TABLE `Untitled3` (
`Key` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`PeopleNumber` Int NULL,
`DateTime` DateTime NULL,
`userId` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`storeId` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`Id2` BIGINT NOT NULL
);
CREATE TABLE `UserCoupon` (
`Id` BIGINT NOT NULL,
`couponId` BIGINT NOT NULL,
`storeId` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`userId` BIGINT(PK, Auto Increment) NOT NULL DEFAULT PK,
`isUsed` BOOLEAN NULL
);
ALTER TABLE `store` ADD CONSTRAINT `PK_STORE` PRIMARY KEY (
`ID`
);
ALTER TABLE `user` ADD CONSTRAINT `PK_USER` PRIMARY KEY (
`ID`
);
ALTER TABLE `Untitled2` ADD CONSTRAINT `PK_UNTITLED2` PRIMARY KEY (
`PK`,
`FK`,
`FK,`
);
ALTER TABLE `coupon` ADD CONSTRAINT `PK_COUPON` PRIMARY KEY (
`id`,
`ID`
);
ALTER TABLE `searchkeyword` ADD CONSTRAINT `PK_SEARCHKEYWORD` PRIMARY KEY (
`ID`
);
ALTER TABLE `Untitled3` ADD CONSTRAINT `PK_UNTITLED3` PRIMARY KEY (
`Key`
);
ALTER TABLE `UserCoupon` ADD CONSTRAINT `PK_USERCOUPON` PRIMARY KEY (
`Id`,
`couponId`,
`storeId`,
`userId`
);
ALTER TABLE `Untitled2` ADD CONSTRAINT `FK_user_TO_Untitled2_1` FOREIGN KEY (
`FK`
)
REFERENCES `user` (
`ID`
);
ALTER TABLE `Untitled2` ADD CONSTRAINT `FK_store_TO_Untitled2_1` FOREIGN KEY (
`FK,`
)
REFERENCES `store` (
`ID`
);
ALTER TABLE `coupon` ADD CONSTRAINT `FK_store_TO_coupon_1` FOREIGN KEY (
`ID`
)
REFERENCES `store` (
`ID`
);
ALTER TABLE `UserCoupon` ADD CONSTRAINT `FK_coupon_TO_UserCoupon_1` FOREIGN KEY (
`couponId`
)
REFERENCES `coupon` (
`id`
);
ALTER TABLE `UserCoupon` ADD CONSTRAINT `FK_coupon_TO_UserCoupon_2` FOREIGN KEY (
`storeId`
)
REFERENCES `coupon` (
`ID`
);
ALTER TABLE `UserCoupon` ADD CONSTRAINT `FK_user_TO_UserCoupon_1` FOREIGN KEY (
`userId`
)
REFERENCES `user` (
`ID`
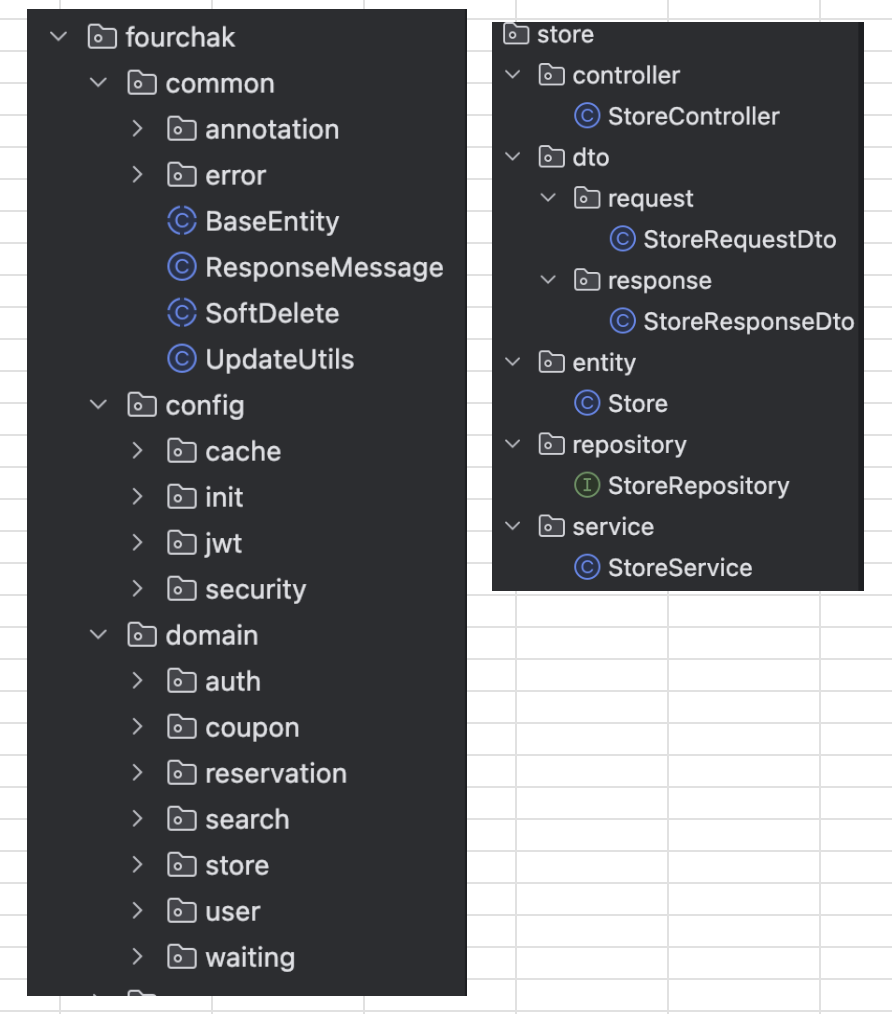
);패키지 구조
검색 API 캐시 적용
문제 상황
- 실시간 검색의 특성: 사용자들이 같은 키워드로 반복 검색 (예: "치킨", "피자")
- DB 부하 증가: 매번 LIKE 쿼리로 전체 테이블 스캔
- 응답 지연: 복잡한 검색 쿼리로 인한 성능 저하
- 동시 요청: 많은 사용자가 동일한 인기 검색어로 동시 검색
캐시 적용 이유
1. 검색 결과 캐싱 (storeSearch)
@Cacheable(value = "storeSearch", key = "#keyword + '_' + #pageable.pageNumber + '_' + #pageable.pageSize")- 반복 검색 최적화: "치킨" 검색 시 5분간 DB 조회 없이 즉시 응답
- 페이지네이션 고려: 키워드 + 페이지 정보로 세밀한 캐시 키 설정
- DB 부하 감소: LIKE 쿼리 실행 횟수 대폭 감소
2. 인기 검색어 캐싱(popularKeywords)
@Cacheable(value = "popularKeywords")- 자주 조회되는 데이터: 인기 검색어는 모든 사용자가 확인하는 공통 데이터
- 집계 쿼리 최적화: COUNT 기반 정렬 쿼리는 비용이 높음
- 실시간성 vs 성능: 30분 주기 업데이트로 충분한 실시간성 확보
3. API 버전 분리
- v1 API: 캐시 미적용 (비교 및 테스트용)
- v2 API: 캐시 적용 (실제 서비스용)
성능 비교 분석
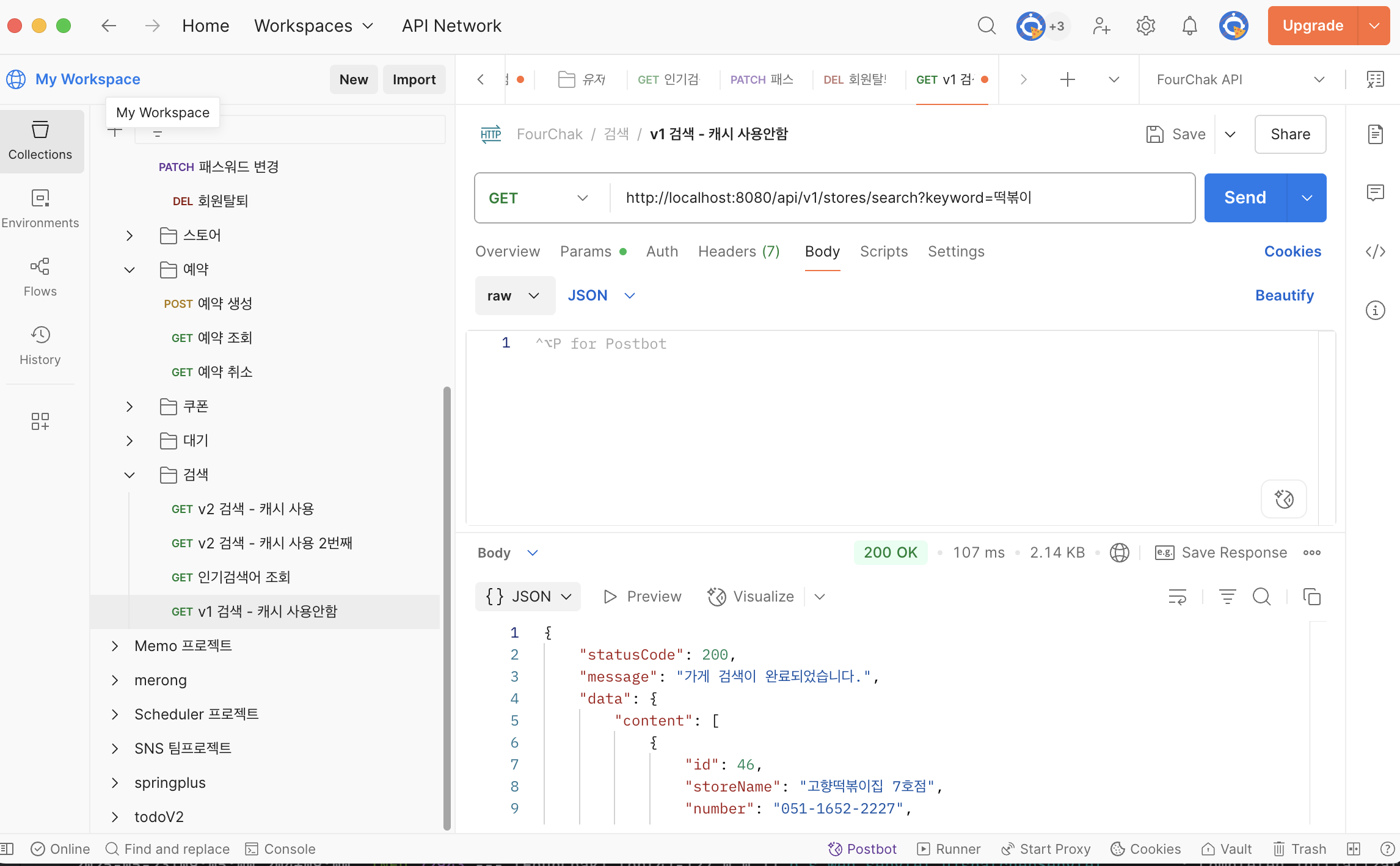
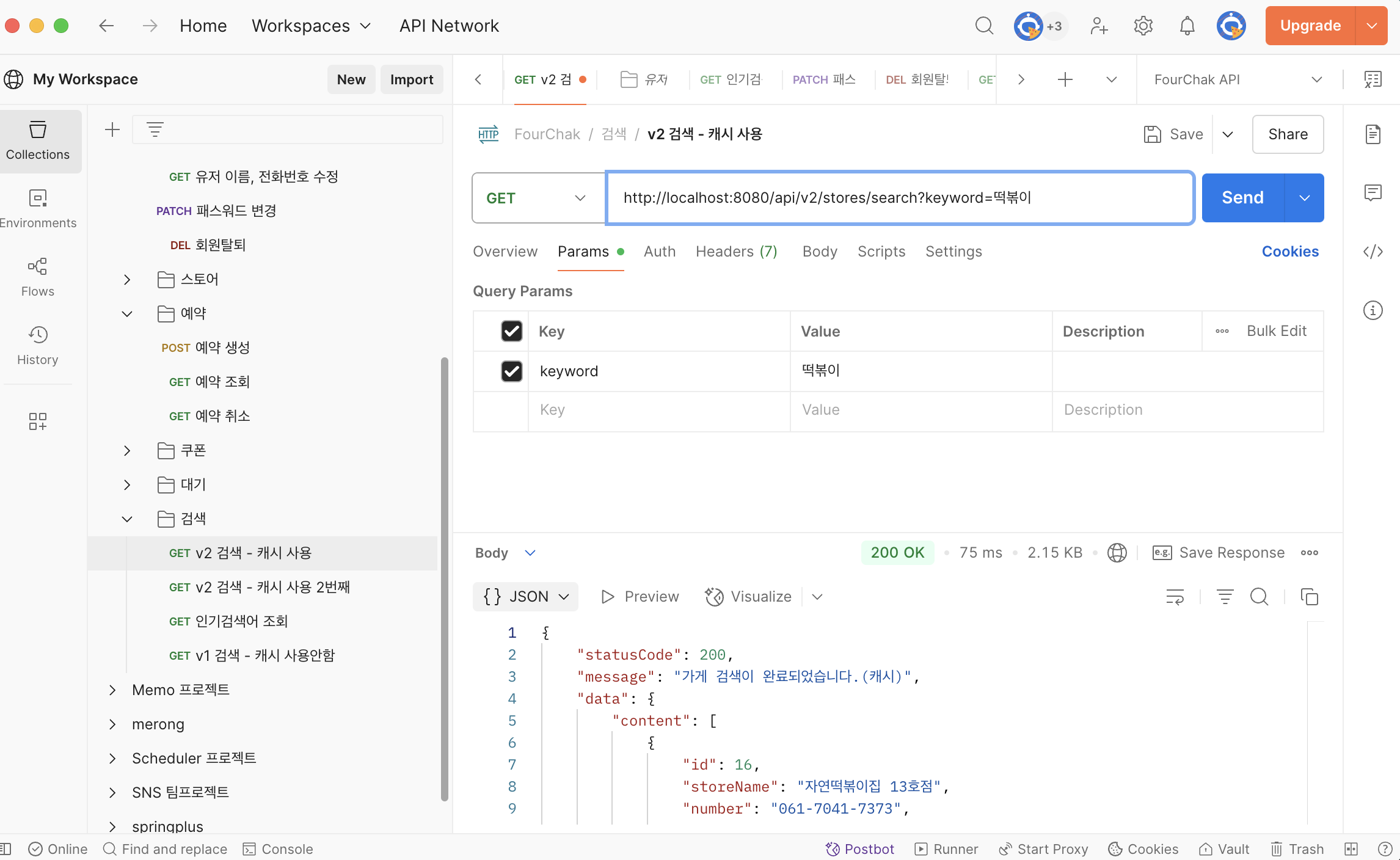
- v1 검색 (캐시 미사용)
응답 시간: 107ms
데이터 크기: 2.14 KB
결과: 가게 ID 46, 가게명 "고향떡볶이집 7호점" - v2 검색 (캐시 사용)
응답 시간: 75ms
데이터 크기: 2.15 KB
결과: 가게 ID 16, 가게명 "지인떡볶이집 13호점"
성능 향상 결과
캐시를 사용한 v2가 약 30% 더 빠른 성능을 보여주고 있습니다:
- 시간 단축: 107ms → 75ms (32ms 감소)
- 성능 향상률: 약 29.9%
KPT회고
Keep
- Reddison을 이용한 동시성 제어를 사용하여 다수의 요청에도 정확한 응답을 함
- 팀원간에 커밋 컨벤션을 맞추고 응답 형식을 정하여 코드 스타일이 일관적이게 함
- PR시 동의가 2명 이상일때 merge가 가능하도록 하여 서로의 코드를 점검 할 수 있게함
- 인덱스가 적용된 저장 정보로 데이터 조회
Problem
- Lecttuce의 락 원자성 확보 실패로 인한 동시성 제어 실패
- DB 락의 직접적 이용으로 락 설정을 수동으로 하다보니 오류가 발생
- 테스트 코드 작성 시 다양한 방식의 데이터 주입 방법과 DB이용 방식을 적용하여 충돌이 남
- 여러 도구들 및 기능을 많이 구현하다보니 서로의 기능을 자세히는 알지 못하여 조금 아쉬움
- 도메인 적 기능 개발에 중심을 두어 core 기능을 중복 개발하게 됨
Try
- 대용량 데이터 더미를 넣어 캐시 성능테스트를 다른 도구를 활용하여 테스트 할 예정
- CI/CD 환경 구성 및 운영 자동화로 개발 생산성 및 릴리즈 관리 효율성 강화 필요
- 테스트시 공통된 환경 컨테이너를 구성하거나 깃 이그노어를 활용하기
Feel
- 김현정 : 여러 서드파티로 여러 기능을 구현하여 저 스스로 공부가 많이되는 프로젝트였습니다. 더 깊이 공부하는 시간을 충분히 가질 수 있고 소통도 잘 되어서 하고싶은 구현을 해봐서 너무 좋았습니다.
- 윤예진 : 이번 프로젝트에서는 깊이 있게 동시성 제어 기술을 적용하면서 많이 배울 수 있는 프로젝트였습니다. 구현 후 각자 맡은 기술에 대해 서로 공유하는 시간을 가졌습니다. 덕분에 제가 직접 다루지 않았던 기술들도 배울 수 있어 유익한 시간이었습니다.
- 전현진 : JWT와 Spring Security를 이용한 인증/인가 구현 과정을 통해 보안 로직에 대한 학습을 할 수 있었습니다. 인덱스 적용 차이를 테스트 코드로 확인하며 성능 개선 관점도 확인하였으나, 테스트 코드 숙련도가 부족해 시간이 오래 걸린 점은 아쉬웠습니다.
- 류경선 : 그동안 강의로만 들었던 동시성 제어를 직접 해봐서 와닿았습니다. 해보고 싶었던 것 전부를 하지는 못했지만 한가지라도 제대로 해보아서 좋았습니다.

백엔드 개발도 락이다