- pandas를 사용하여 데이터셋을 다루는 간단한 방법을 포스팅하고자 합니다.
- 저는 Kanggle에서 제공하는 항공기 센서 데이터셋을 사용하였습니다.
pandas를 사용하기 위한 준비 단계
- pandas를 사용하기 위해서 cmd 창에서 pandas를 다운로드합니다.
pip install pandas- 다음으로 pandas를 사용하기 위해서 라이브러리를 불러옵니다.
import pandas as pd위의 과정으로 pandas를 사용할 준비를 마쳤다면
데이터 셋 불러오기(Read)
df_train = pd.read_csv(r'[Dataset]Train.csv')'[Dataset]Train.csv' : 사용하는 데이터셋 파일 이름
' '안에 들어가는 데이터셋(csv파일)은 사용하실 데이터셋으로 변경하시면 됩니다.
데이터셋의 첫 10행 출력하여 데이터 탐색하기
head()를 사용하여 DateFrame에서 첫 10행을 출력하여 데이터를 탐색할 수 있습니다.
df_train.head(10)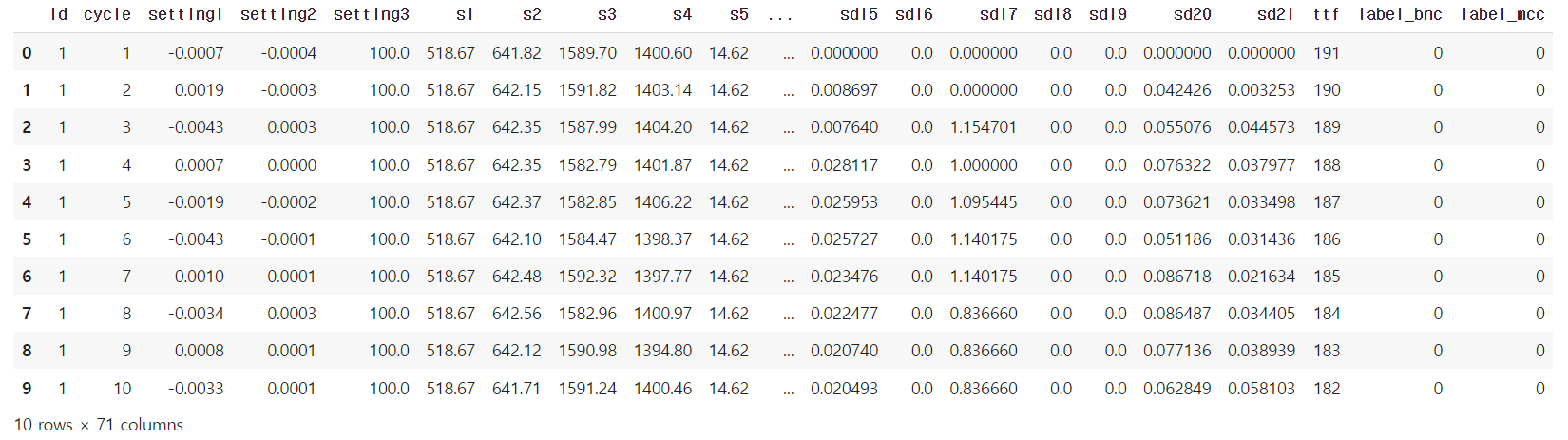
df_train.head()
head() 함수의 default 값은 5이기에 df_train.head()를 하게 되면 첫 5행을 출력합니다.
데이터셋 칼럼의 정보 출력
df_train.describe()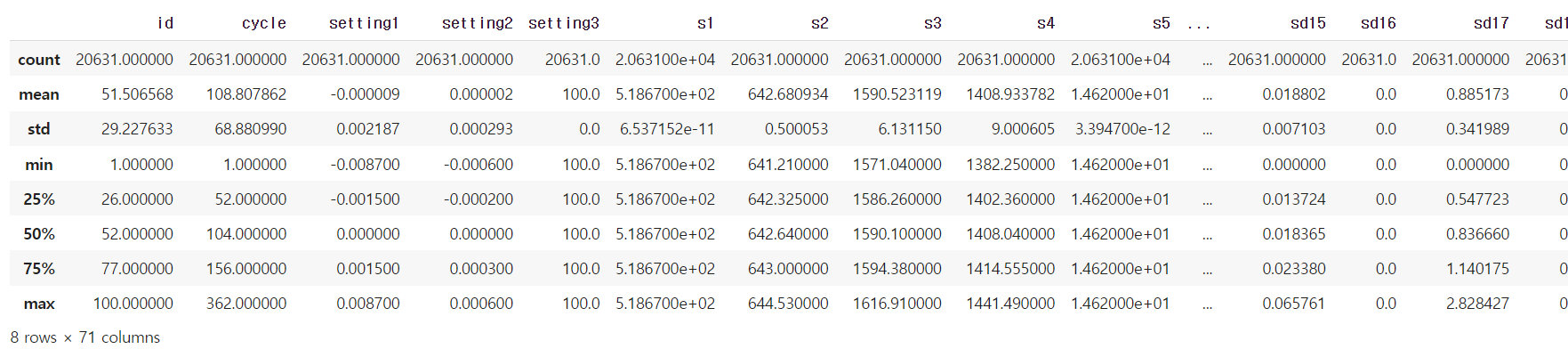
describe() 함수는 통계량을 나타내주는 메서드이고,
데이터 프레임 칼럼별 카운트, 평균, 표준편차, 최소값, 4분위 수, 최대값을 보여줍니다.
칼럼별 결측값 구하기
df_train.isnull().sum()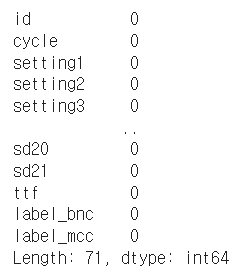
이후에 모델에 학습을 시키고 데이터셋을 사용하기 위해서는 결측값 즉, 비어있는 값을 찾아내 채울 수 있는 값은 채우고, 그렇지 못한 값들은 삭제해 주는 것이 모델의 정확도나 데이터의 신뢰성을 높이기 위해서는 중요합니다.
그렇기 때문에 데이터셋을 분석하는 과정에서 결측값을 찾아내 확인하고 삭제하는 것입니다.
결측값이 들어있는 행 전체 삭제하기
df_train.dropna(axis=0)dropna() 함수를 사용하여 결측값이 들어있는 행 전체를 삭제합니다.
제가 사용하는 데이터 셋에는 결측값이 없어 삭제를 진행하지는 않았습니다.
결측값이 들어있는 열 전체 삭제하기
df_train.dropna(axis=1)dropna() 함수를 사용하여 결측값이 들어있는 열 전체를 삭제합니다.
이상으로 데이터 셋을 분석하는 간단한 방법에 대한 포스팅을 마치겠습니다!
추가로 궁금한 점이나 포스팅 내용 중에 수정할 내용이 있다면 편하게 댓글 달아주시면 감사하겠습니다!!
