🧩 동치 분할 기법
동치 분할은 모듈에 입력되는 데이터와 이를 이용하여 수행되는 기능 간 관계를 이용하여 테스트 데이터를 생성한다.
입력 도메인(입력 데이터의 영역)은 동등한 연산에 의해 처리되는 데이터들의 부분집합으로 분할된다.
이렇게 분할된 부분집합을 동치 클래스라고 부르는데 같은 클래스에 속하는 모든 입력 데이터는 동등한 연산 과정을 통해 처리된다.
입력 조건이 일정 값의 영역을 갖는 경우
예를 들어, 입력 변수의 범위가 1 ~ 99의 값으로 정의되었다면 {50, 120}과 같은 테스트 데이터를 선정할 수 있다.
입력 조건이 데이터 타입으로 정의된 경우
예를 들어 입력 변수 X가 정수형으로 정의되었다면 {5, 5.0}과 같은 테스트 데이터를 선정할 수 있다.
입력 조건이 제약 조건을 갖는 데이터 타입으로 정의된 경우
예를 들어 변수가 인덱스 변수로 사용되는 경우 {1, -5}와 같은 테슽트 데이터를 선정할 수 있다.
동치 클래스 내에서 제약 조건을 갖는 경우
동치 클래스에 속한 멤버들이라고 해도 동등한 연산에 의해 처리되지 않는다면 하위 동치 클래스로 더 세분화할 수 있다.
🎯 경계치 커버리지 분석
동치 분할에 의해 분리된 동치 클래스의 경계에 해당하는 값을 테스트 데이터로 선정하는 방법이다.
입력 변수 특정 영역이 [-1.0, +1.0]으로 정의된 경우 {-1.1, -1.0, +1.0, +1.1}과 같이 4개의 데이터로 테스트 데이터를 선정할 수 있다.
🧪 특수치 커버리지 분석
모듈의 인터페이스가 아닌 모듈의 기능을 중심으로 테스트 케이스를 선정하는 방법이다.
모듈 알고리즘에 대한 특징을 반영하거나 내부적으로 특수한 함수를 사용하는 경우 특수한 커버리지를 적용한다.
동일한 y값을 가지는 sin(x)의 x값들을 예로 들 수 있다.
🔁 원인 결과 커버리지 분석
입력 조건에 따라 결과가 다르게 나타날 때 해당 입력 조건을 각각 테스트 데이터로 선정하는 방법이다.
원인 결과 커버리지를 표현하는 방법으로는 다음 두 가지가 있다.
1. 의사결정 테이블
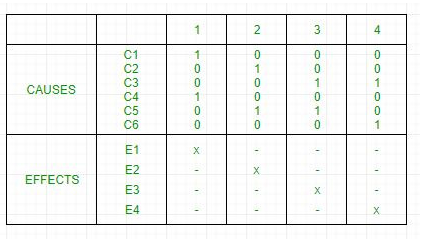
동치 클래스와 이들의 조합 클래스 구조를 테이블 형태로 쉽게 표현한 테스트 데이터 선정 방법이다.
테이블 상단에는 입력 변수 조건을 나열하고 하단에는 상단 조건에 의해 수행될 수 있는 동작을 기술한다.
각 컬럼은 하나의 테스트 데이터가 될 수 있다.
출처
의사결정 테이블을 통해 주어진 입력 변수에 대해 서로 다른 처리(동작)을 수행하는 테스트 데이터를 선정할 수 있따.
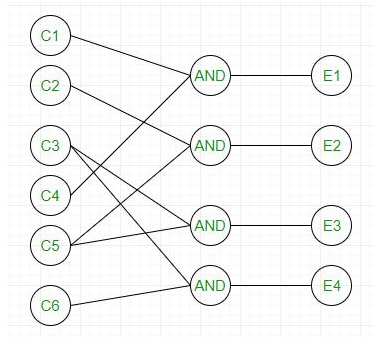
2. 원인 - 결과 그래프
그래프에는 원인 노드와 결과 노드가 있고 이들 간의 처리 관계를 나타내는 edge가 있다.
출처
🧱 블랙박스 테스트 케이스 생성
1. 동치 분할
입력 변수들에 대한 분할이 이루어져야 하고 분할 과정에서 반드시 고려할 사항은 정상 처리 클래스뿐 아니라 비정상 처리 클래스도 함께 나타내야 한다는 것이다.
2. 커버리지 매트릭스 작성
동치 분할 결과에 대한 테스트 케이스를 식별하는 데 사용된다.
3. 경계치 분석
입력 변수들에 대한 경계치를 고려할 수 있다.
4. 테스트 케이스 작성
커버리지 매트릭스에 나타난 각각의 테스트 케이스와 경계치 분석에서 식별된 추가적인 테스트 케이스를 고려하여 프로그램의 테스트 과정에 입력할 실제 값들을 선정해야 한다.
각 테스트 케이스에는 입력값에 의한 예상 출력값도 함께 표시하여 추후 테스트 실행 결과에 대한 성공/실패의 오라클로 사용한다.
