Abstract
- recurrence와 convolution을 제거하고 오로지 attention에만 기반한 새로운 network 제안.
- 병렬 처리 가능, 학습 시간 단축, 2014년 WMT 영어-독일어 번역 대회에서 sota 달성.
- 다른 task에도 일반화 가능.
1. Introduction
- recurrent 모델의 sequential한 특성은 훈련 과정에서 병렬화를 배제. -> 샘플간 배치화를 제한하여 처리할 시퀀스의 길이가 길수록 치명적.
- attention mechanisms도 아직까지 recurrent network와 함께 사용됨.
- recurrnet 모델의 제약 사항을 극복하고 입력과 출력의 전역 의존성을 이끌어내기 위해 Transformer 제안.
3. Model Architecture
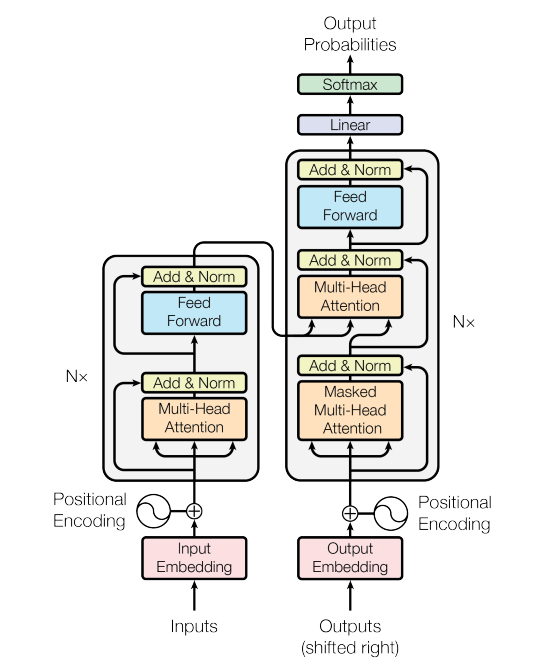
- 가장 경쟁력 있는 신경망 기반 시퀀스 변형 모델은 encoder-decoder 구조를 가지고 있음. -> Auto-Regressive
- Transformer도 이와 같은 encoder-decoder 구조 사용.
- self-attention과 point-wise fully connected layer를 encoder와 decoder 에 쌓아서 사용.
3.1. Encoder and Decoder Stacks
Encoder
- N = 6 의 동일한 layer로 구성.
- multi-hear self-attention mechanisms와 단순 position-wise FC feed-forward network의 sub-layer로 구성.
- sub-layer마다 residual connection, layer normalization 사용. 이를 위해 512의 output 차원을 가짐.
Decoder
- N = 6 의 동일한 layer로 구성.
- 2개의 sub-layers 외에도 Encoder 스택의 출력을 통해 multi-head self-attention을 수행하는 sub-layer 사용.
- 순차적인 결과를 도출하기 위해 masking 기법을 통해 position i보다 작은 output 위치에만 의존.
3.2. Attention
- attention 함수는 query, key, value, output이 모두 벡터일 때, query와 key-value 쌍의 집합을 output에 mapping 하는 것.
- query와 대응되는 key의 compatibility function에 의해 계산된 attention 가중치로 value를 weighted sum하여 output 계산.
3.2.1. Scaled Dot-Product Attention
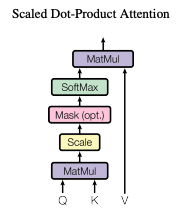
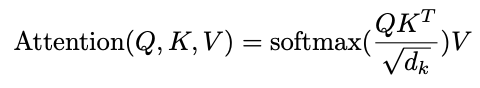
3.2.2. Multi-Head Attention
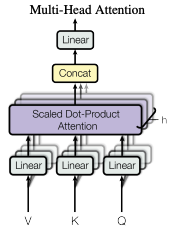

- query, key, value를 각각의 차원으로 변환하는 서로 다른 h개의 학습이 가능한 linear projection 후, 각각의 projected version에 대해 병렬적으로 attention을 진행하는 것이 단일 attention function을 수행하는 것보다 더 좋음.
- 다른 position에 더 attend 할 수 있다.
- 여러 representation subspaces의 정보를 사용할 수 있다.
- computational cost는 단일 attention과 같다.
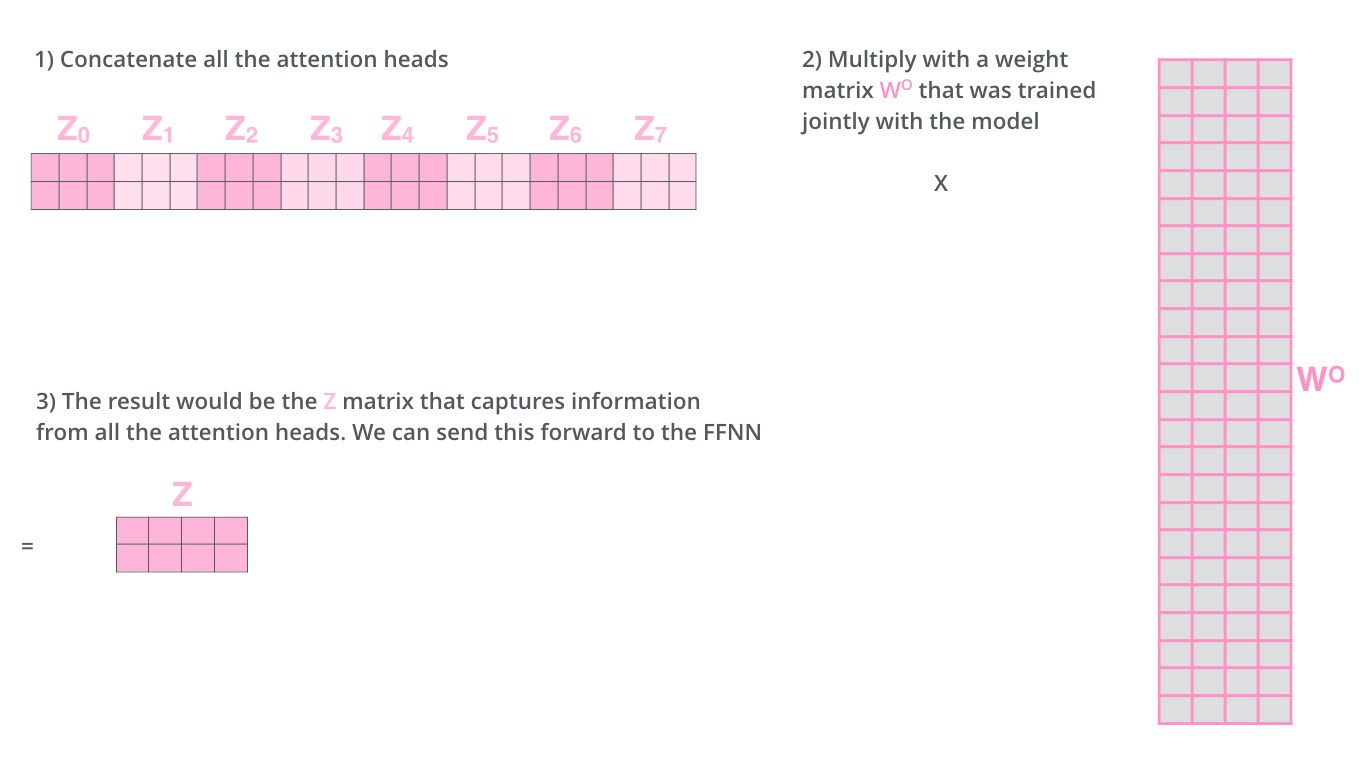
- 입력의 차원이 512이고 head가 8개라면 각 헤드의 Q,K,V는 512/8=64차원
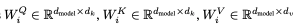
위 Wq, Wk, Wv는 기존의 512차원을 64차원으로 나누기 위한 가중치 행렬 - Wo은 각 헤드의 결과인 latent vectors를 concat하고 이를 input의 차원과 같게 바꾸기 위한 가중치 행렬
3.2.3. Applications of Attention in our Model
- encoder-decoder attention layers
- Q는 decoder, K와 V는 encoder로부터
- encoder의 self-attention layers
- decoder의 self-attention layers
- Masked Multi-Head Attention
- 현재 단어의 이전 단어들만 보고 이후 단어는 masking
softmax 입력을 -inf로 변경하여 연산 결과 0이 나오게 함.
3.3. Position-wise Feed-Forward Networks
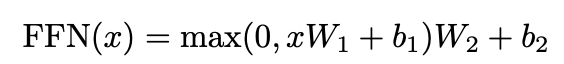
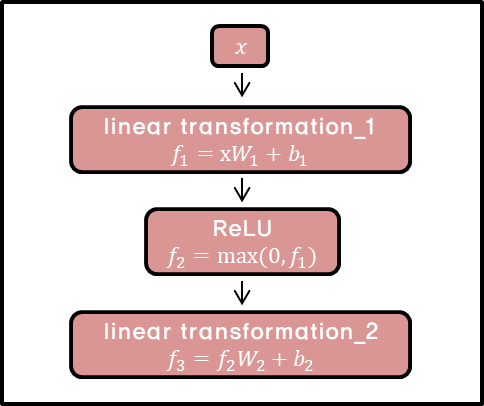
- linear transformation을 적용하고 ReLU를 거친 결과를 또다른 linear transformation에 적용.
- 같은 layer에서는 각 position마다 같은 W,b가 적용됨.
- kernel size가 1인 두 개의 convolutions처럼 이해할 수 있음.
3.4. Embeddings and Softmax
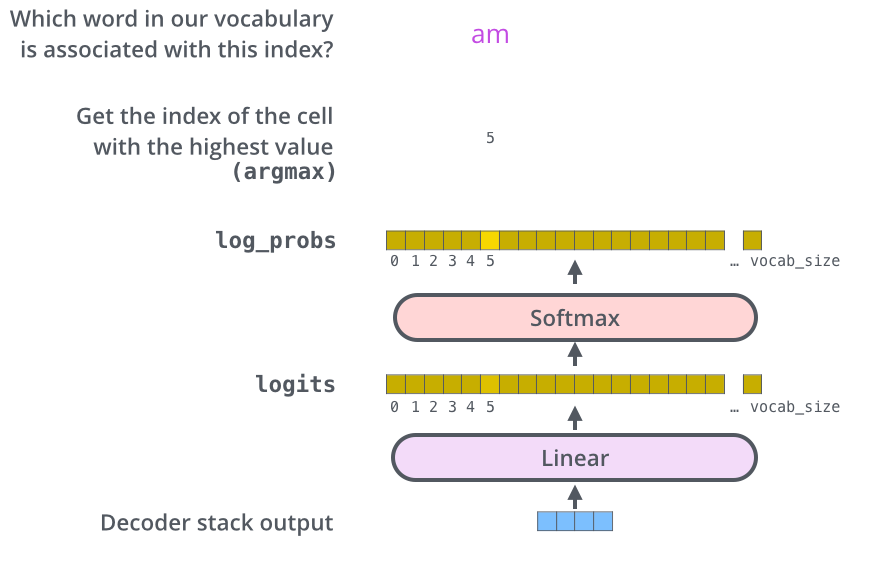
- 다른 sequence 모델들처럼 입력과 출력 토큰에 대해 임베딩 벡터를 사용한다.
- decoder의 output을 vocab size 차원의 벡터로 출력하기 위해 linear transformation과 이를 0과 1 사이의 확률값으로 나타내기 위해 softmax를 사용한다.
3.5. Positional Encoding
- 제안하는 모델이 recurrence나 convolution을 포함하지 않기 때문에 순차적인 시퀀스의 위치 정보를 주입하기 위해 encoder 및 decoder stack 하단에 positional encodings을 추가함.
- positional encodings는 dmodel과 동일한 차원을 가지기 때문에 이를 더하는 작업이 가능.
- positional encoding의 조건
- 각 time-step(토큰의 위치)마다 유일한 값
- 서로 다른 문장에 대해 time-step 간 거리는 일정한 의미가 있어야 한다. (일관성)
- 더 긴 문장에도 일반화되어야 한다.
- 매번 같은 값이 나와야 한다.
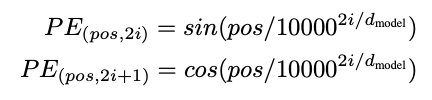
- 해당 연구에는 위의 조건을 만족하는 방법으로 다른 주기의 싸인, 코싸인 함수 (sinusodial version)를 사용함.
- 차원을 짝수, 홀수에 따라 싸인, 코싸인을 사용하는 이유: 주기함수의 특성상 위치가 커짐에 따라 다시 값이 작아져 특정 두 토큰의 값이 동일해질 수 있는 것을 방지하기 위함.
- 이 방법 말고 학습된 positional embedding을 사용하였을 때 비슷한 결과가 나왔다.
- 하지만 모델이 훈련한 시퀀스의 길이보다 더 긴 시퀀스에 대해서도 추론할 수 있는 sinusodial version을 선정
(position 간 가까우면 내적이 크고 멀면 작아져 거리 관계를 대칭적으로 대략 유추할 수 있다고 함)
Why Self-Attention
- 레이어 당 총 계산 복잡도가 줄어듦.
- 병렬처리 될 수 있는 계산량이 늘어남.
- rnn보다 훨씬 먼 거리의 시퀀스를 학습할 수 있음.
- 해석 가능성이 높아짐.
.
.

NLP Researcher / Information Retrieval / Search