Abstract
- 큰 데이터셋으로부터 단어의 vector representations를 연산하는 두 가지 모델 제안
- 단어 유사도를 척도로 이전 다른 유형의 신경망 기반 모델의 최고 성능과 결과를 비교했다.
- 훨씬 낮은 computational cost, 높은 accuracy
- test set에 대한 syntactic, sementic 단어 유사도를 기준으로 sota를 달성했다.
1. Introduction
- 많은 NLP 기술들은 단어 간 유사성에 대한 개념 없이 단어를 원자 단위(개별적인 가장 작은 단위)로 취급했다.
- 방대한 양의 데이터를 학습한 단순한 모델이 적은 양의 데이터를 학습한 복잡한 모델보다 더 나은 경우가 관측되었고, 단순하고 robust하기 때문에
- ex) N-gram
- 위와 같은 기법은 여러 한계가 존재
- machine learning 기술이 발전하면서 더 큰 데이터 셋을 더 복잡한 모델에 학습할 수 있게 되었고, 일반적으로 단순한 모델들의 성능을 능가.
- Distributed representation 방식을 사용하는 것이 아마 가장 성공적인 방식
Distributed Representation
- 단어의 의미를 여러 차원에 분산하여 표현하는 방식
- Distributional Hypothesis
: Words that occur in similar contexts tend to have similar meanings
즉, 비슷한 분포를 가지는 단어들은 비슷한 의미. 주로 같이 많이 나오는 단어들은 비슷하다는 가정.- 단어를 공간 상 매핑
- 각 단어를 벡터로 표현 -> 벡터 간 연산을 통해 단어 간 관계를 추론 가능
- One-Hot encoding처럼 sparse 하지 않음.
1.1 Goals of the Paper
- 거대한 데이터셋으로부터 높은 수준의 word vector를 학습하는 기술을 제안
- 이전에 제안된 구조들은 수억개의 단어를 학습하지 못함.
- vector representations의 결과를 측정하기 위해 최근에 제안된 기법 사용
- 유사한 단어는 서로 가까워야 하고 각 단어는 다양한 의미의 유사도를 가짐 - vector("King") - vector("Man") + vector("Woman") = vector("Queen")
- 단어 간 linear regularities을 보존하고 벡터 연산의 accuracy를 최대화
- syntactic, semantic regularites을 측정하기 위한 test set을 설계
- 학습시간과 정확도에 word vector의 차원과 train data의 양이 어떤 영향을 주는지 논의
1.2 Previous Work
Feed Forward Neural Network Language Model (NNLM)
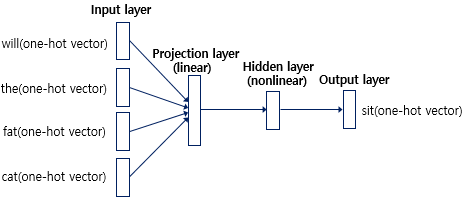
- 이전의 단어들을 통해 현재 단어를 예측
- Input layer: n개의 단어의 one-hot vector가 입력으로 들어감.
- Projection layer: 가중치 행렬과의 곱셈은 이루어지지만 활성화 함수가 존재하지 않음. (=> Linear)
- Hidden layer
- Output layer: 출력값과 정답값의 오차로부터 손실함수를 통해 backpropagation 수행-> weight update
- sparsity problem 문제 해결
- 계산복잡도 Q = N x D + N x D x H + H x V
- 한계: 고정된 History 단어 개수(n) / 미래 시점은 고려 불가 / 계산복잡도 큼
Recurrent Neural Network Language Model (RNNLM)
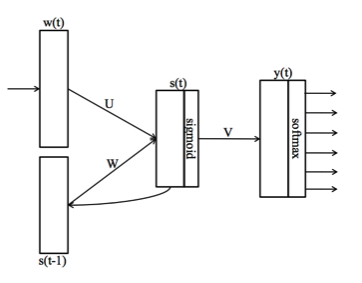
- Projection layer 없음.
- Hidden layer의 값이 다시 input이 되는 recurrent 구조 -> 일종의 short-term memory 역할로 과거의 단어를 고려함.
- History 단어 개수를 설정하지 않음.
- 계산복잡도 Q = H x H + H x V
=> 본 논문에서 제시한 모델은 위 모델들보다 계산복잡도를 줄여 computational cost를 줄였다.
2. Model Architectures
내용 추가 예정

NLP Researcher / Information Retrieval / Search