Abstract
Natural language understanding(NLU)는 다양한 task로 구성된다.
레이블이 지정되지 않은 text corpus는 풍부하지만 레이블링된 데이터는 부족하기 때문에 이러한 다양한 task에 대해 적절하게 학습하기 어렵다.
본 논문은 다양한 unlabeled text에 대한 language model의 generative pre-training과 이를 각 특정한 task에 discriminative fine-tuning하는 방식을 고안한다.
이전의 방법론들과는 달리 모델의 구조를 최소한으로 변경하면서 효과적인 transfer를 달성하기 위한 fine-tuning 단계에서 task에 맞는 input representations을 사용한다.
이를 통해 nlu의 다양한 벤치마크에 대한 효과적인 접근법을 제공하고, 기존의 각 task 별로 학습된 모델의 성능을 능가하여 12개의 task에 대한 실험 중 9개의 task에 SOTA를 달성하였다.
1. Introduction
raw 데이터로부터 효과적으로 학습하는 능력은 NLP에서 지도학습에 대한 dependency를 완화하는 데 중요하다. 대부분 딥러닝 방법에는 상당한 manual labeled data가 필요하고, 이는 레이블링된 데이터가 부족한 도메인에서는 적용되기 어렵다. 따라서 unlabeled 데이터를 활용할 수 있는 모델은 수동으로 레이블링하는 비용을 절약하는 대안이 된다. 또한 기존 방법에 비해 성능이 향상될 수 있다. 그 예로는 다양한 NLP task에서 성능을 향상시키기 위해 광범위하게 적용된 pre-trained word embedding이 있다.
하지만 unlabeled text로부터 단어 수준 이상의 정보를 얻는 데에는 두 가지 어려움이 있다.
1) 어떤 objective function이 transfer에 유용한 text representation을 학습하는 데 가장 효과적인지 불분명하다.
2) 학습된 representations를 가장 효과적으로 다른 task에 transfer 할 수 있는 방법이 불명확하다.
NLP를 위한 효과적인 semi-supervised learning의 개발에 위와 같은 challenges가 있었다.
본 논문에서는 unsuperviese pre-training과 supervised fine-tunning을 함께 사용하여 language understanding tasks를 위한 semi-supervised 방법을 제안한다.
논문의 목표는 약간의 조정으로 넓은 범위의 task에 대해 범용적으로 활용할 수 있는 representation을 학습하는 것이다.
논문은 대량의 unlabeled text corpus와 labled text 데이터셋을 가정한다.
두 단계의 학습 절차를 사용한다.
1) neural network 모델의 초기 parameters를 학습하기 위해 unlabeled data의 objective function을 사용한다.
2) 1)과 같은 방식으로 학습된 parameters를 supervised fune-tuning을 사용하여 target task에 적용시킨다.
다양한 task에 대해 좋은 성능을 냈던 Transformer를 모델의 아키텍처로 사용하였다.
Transformer를 사용함으로써 long-term dependencies 문제를 해결하는 구조적인 memory를 적용할 수 있고, 하나의 연속적인 토큰의 sequence를 입력으로 사용하여 task-specific하게 input을 조정하여 사용할 수 있다.
이러한 방법을 통해 pre-trained model의 구조를 최소한으로 변경하며 효과적인 fine-tuning 할 수 있다.
본 논문은 natural language inference, question answering, semantic similarity, text classification 네 가지 task에 대해 평가한다. 그 결과 각 task에 대해 specific하게 학습된 모델의 성능을 뛰어넘어 12개의 task 중 9개의 SOTA를 달성하였다.
3. Framework
본 논문의 training 절차는 두 단계로 구성된다.
첫 번째, (Unsuperviese pre-training)
대량의 unlabeled 데이터를 통해 large language model을 학습한다.
두 번째, (Supervised fine-tuning)
labeled 데이터를 통해 특정 task에 맞는 fine-tuning을 한다.
3.1 Unsupervised pre-training
U = {u1, . . . . un}의 토큰으로 구성된 unsupervised corpus가 주어졌을 때,
다음과 같은 likelihood를 maximize하는 objective function을 사용한다.
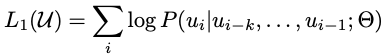
k: context window의 size
P: parameter()의 neural network로 설계된 조건부확률
이는 SGD를 통해 train된다.
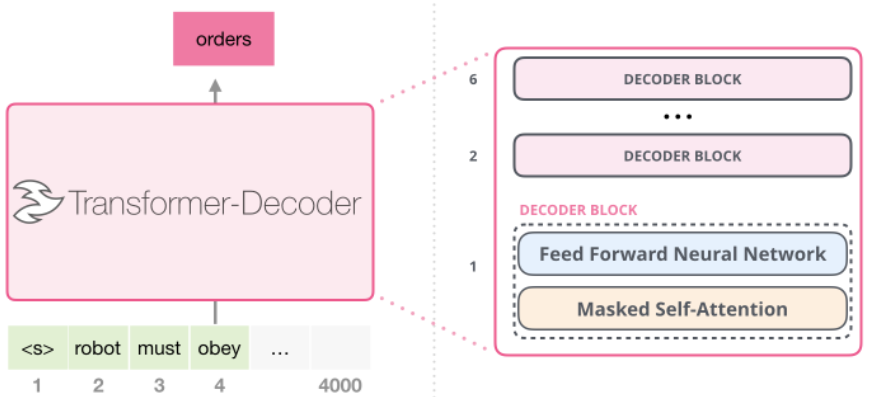
모델은 transformer 모델의 decoder를 변형한 구조를 사용한다.
이 모델은 multi-headed self-attention과 position-wide feedforward layer로 구성된 decoder block 여러 층으로 구성되고, target token에 대한 분포를 출력한다.
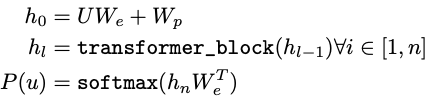
n: layer 개수
We: token embedding matrix
Wp: position embedding matrix
h0: decoder에 입력되는 sequence tokens.
hl: transformer block을 통과하여 얻은 hidden state
P(u): target toekn u에 대한 예측 확률
3.2 Supervised fine-tuning
위의 unsupervised pre-training을 통해 모델을 학습한 후, parameter를 각 task에 맞게 fine-tuning 한다.
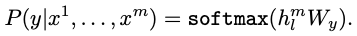
이는 pre-trained 모델을 통해 최종 transformer block의 출력 분포인 hlm을 얻고 이를 linear layer를 하나 통과한 후 (hlmWy) y에 대한 예측을 위해 softmax를 적용시킨 것이다.
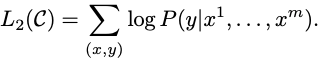
C: labeled dataset
x1~xm: 입력 sequence
y: target token
따라서 위와 같은 objective function을 최대화하여 학습한다.
하지만 fine-tuning만의 objective function 뿐만 아니라 unsupervised pre-training의 objective function을 보조 objective function으로 사용하였더니 superveise model의 일반화 성능을 향상시키고 수렴 속도를 가속화하였다.
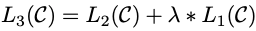
따라서 위와 같이 람다에 대한 objective function을 최대화하여 최적화한다.
전체적으로 fine-tuning 단계에서 필요한 추가 parameter는 linear layer의 weight matrix(Wy)와 구분자 token의 embedding이다.
3.3 Task-specific input transformations
text classification 같은 task는 위에서 설명한 방법으로 처리할 수 있지만 question and answering과 같은 task는 Input 문장이 여러 개인 경우 등에는 따로 Input의 형태를 처리해주어야 한다.
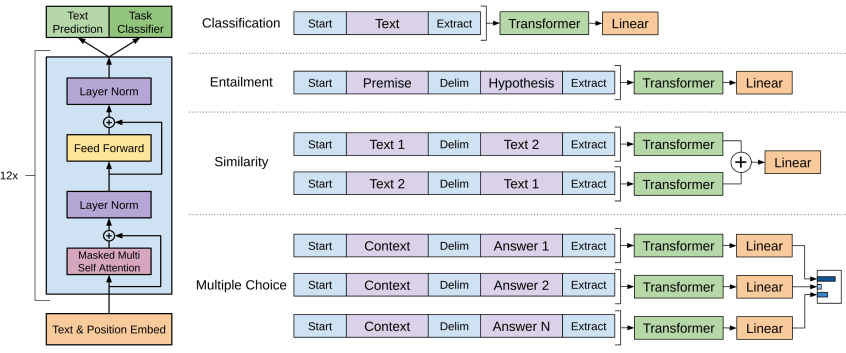
그림과 같이 다양한 작업에 대한 fine-tuning을 위해 task별로 input을 구조화된 token sequence로 변환하여 pre-trained 모델에 적용한 후 linear layer와 softmax를 통과한다.
4. Experiments
4.1 Setup
-
Unsupervised Pre-training
1) BookCorpus 데이터셋 사용
다양한 장르의 unique한 7000권 이상의 미발행 서적이 포함된 데이터셋
2) 1 Billion Word Language Model BenchMark 데이터셋 사용 -
Supervised fine-tuning

네 가지 task에 대해 위의 datasets을 사용
Results
1) Natural Language Inference
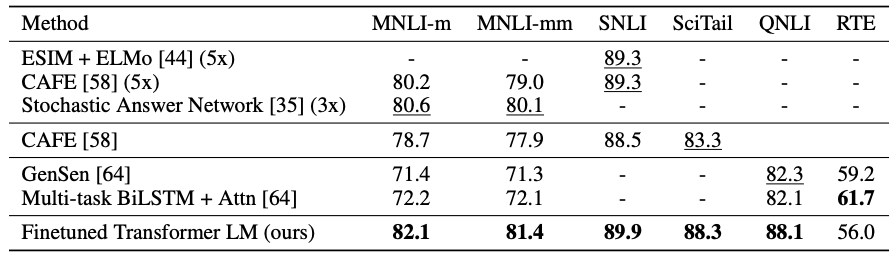
2) Question & Answersing
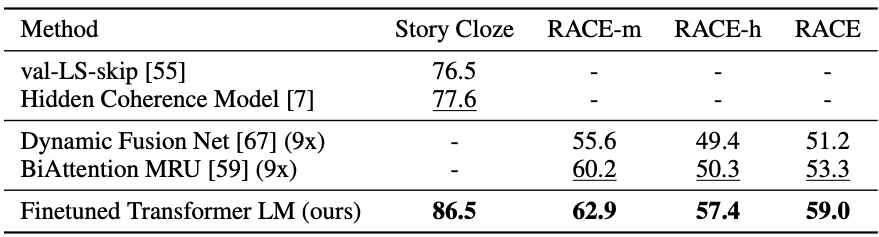
3) Sementic Similarity & Classification
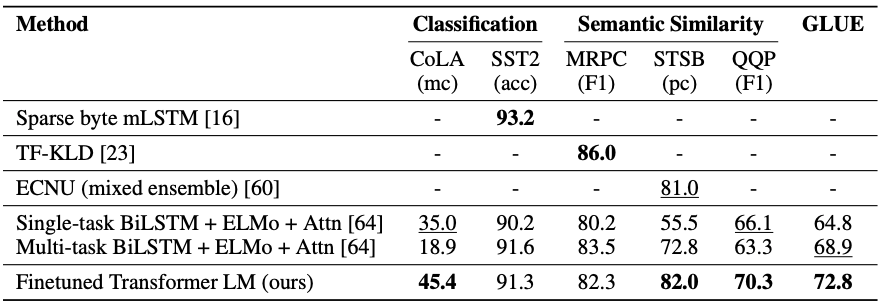
=> GPT가 당시 SOTA 모델의 성능을 대부분 뛰어넘음. (몇 가지 데이터셋에 대해서만 낮은 경우가 있음)
5. Analysis
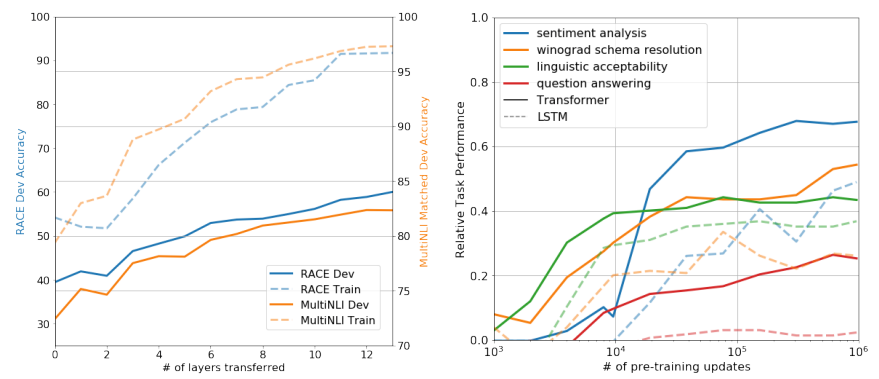
왼쪽: GPT에서 쌓은 transformer block의 개수에 대한 실험 (두 가지 데이터셋에 대함)
-> 쌓을수록 성능이 올라감
오른쪽: unsupervised learning으로 만든 모델을 zero-shot을 통해 학습했을 때와 fine-tuning을 통한 점차적인 학습에 대한 비교 실험
-> fine-tuning이 더 좋음
