💻과적합 문제?
from keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import numpy as np
import tensorflow as tf
#seed 값 설정
np.random.seed(3)
tf.random.set_seed(3)
#데이터 로드
df = pd.read_csv('/content/drive/MyDrive/AI_WINTER_STUDY/sonar.csv', header = None)
#print(df.info())
#데이터
dataset = df.values
X1 = dataset[:,0:60]
Y1_obj = dataset[:,60]
#문자열 클라스를 숫자로 변환
e1 = LabelEncoder()
e1.fit(Y1_obj)
Y1 = e1.transform(Y1_obj)
#모델의 설정
model = Sequential()
model.add(Dense(24, input_dim = 60, activation = 'relu'))
model.add(Dense(10, activation = 'relu')) #최종 출력 값 3개 중 하나
model.add(Dense(1, activation = 'sigmoid'))
#모델 컴파일
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
#Failed to convert a NumPy array to a Tensor (Unsupported object type float).
#문제가 되는 부분의 변수 타입 바꾸기
X1 = X1.astype(np.float32)
Y1 = Y1.astype(np.float32)
#모델 실행
model.fit(X1, Y1, epochs = 200, batch_size = 5)
#결과 출력
print("\n Accuracy : %.4f" %(model.evaluate(X1, Y1)[1])) 정확도가 100%?
정확도가 100%?
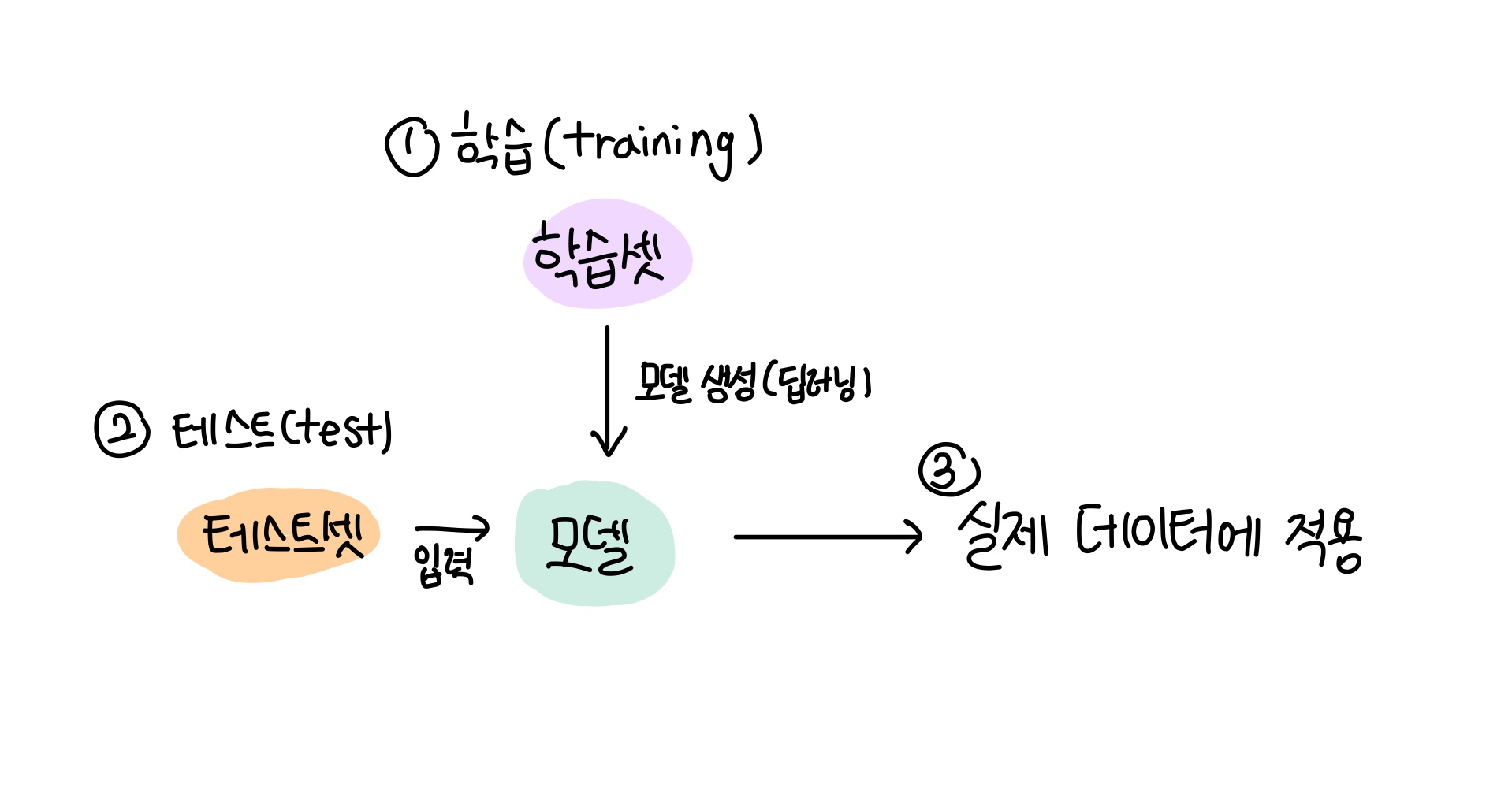
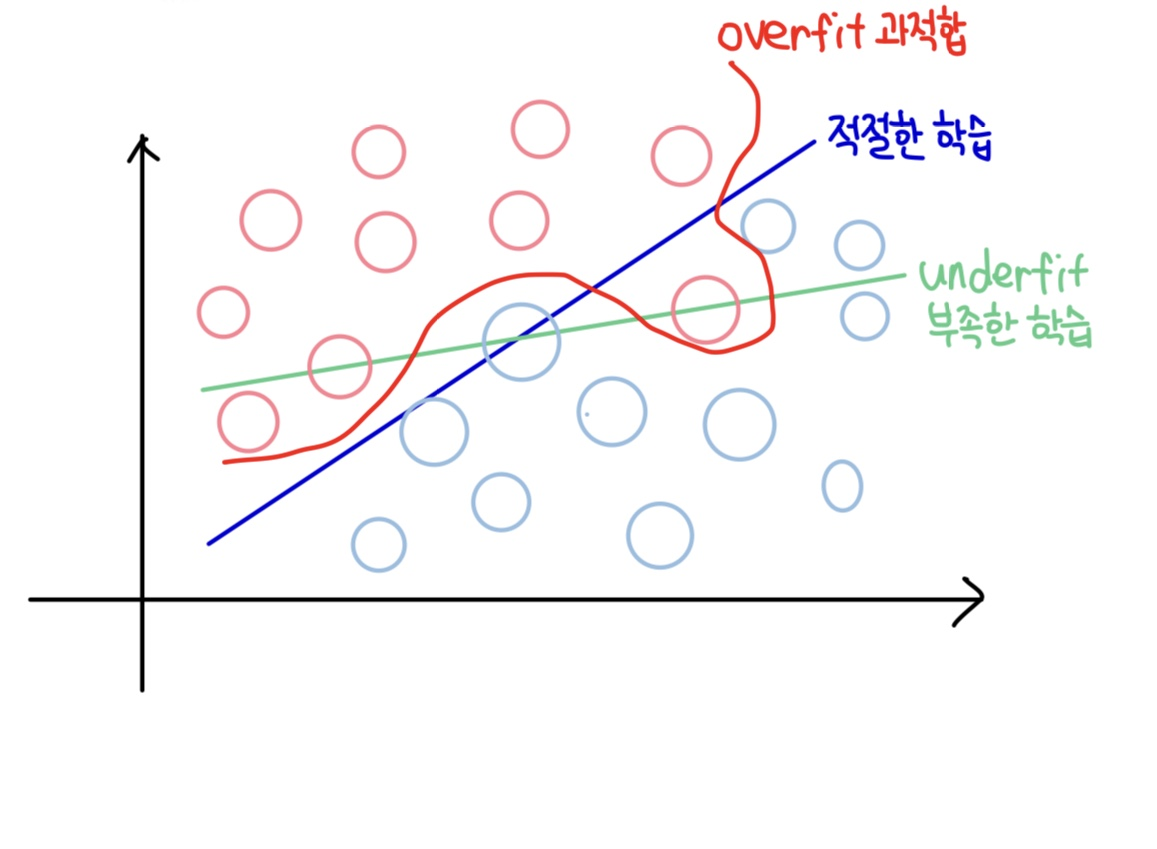
📌과적합 overfitting
모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않은 것을 의미
과적합이 생기는 경우
① 층(layer)이 많은 경우
② 변수가 복잡한 경우
③ 테스트셋과 학습셋이 중복될 경우
💻과적합을 방지하려면?
학습을 위한 데이터셋과 테스트를 위한 데이터셋을 완전히 구분한 다음
학습과 동시에 테스트를 병행하며 진행할 것!
학습의 결과가 저장된 파일을 '모델'이라고 부른다. 모델을 다른 셋에 적용할 경우 학습 단계에서 각인되었던 그대로 다시 수행한다.
#정해진 비율만큼 학습셋과 테스트셋 구분하게 해주는 라이브러리
from sklearn.model_selection import train_test_split
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(3)
#학습셋(70%)과 테스트셋(30%) 구분
X_train, X_test, Y_train, Y_test = train_test_split(X1, Y1, test_size = 0.3, random_state=seed)
model = Sequential()
model.add(Dense(24, input_dim = 60, activation = 'relu'))
model.add(Dense(10, activation = 'relu'))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'mean_squared_error',
optimizer = 'adam',
metrics = ['accuracy'])
model.fit(X_train, Y_train, epochs = 130, batch_size = 5)
#테스트셋에 모델 적용
print("\n Test Accuracy : %.4f" %(model.evaluate(X_test, Y_test)[1])) 테스트셋 실험 결과 약 80.95%의 성공률을 보인다
테스트셋 실험 결과 약 80.95%의 성공률을 보인다
💡검증셋(Validation set)
실전에서는 학습셋, 테스트셋 되의 또다른 데이터셋을 준비한다.
이 때 훈련에 쓰이는 데이터셋을 검증셋, 마지막 테스트를 위한 데이터셋을 테스트셋이라고 부른다.
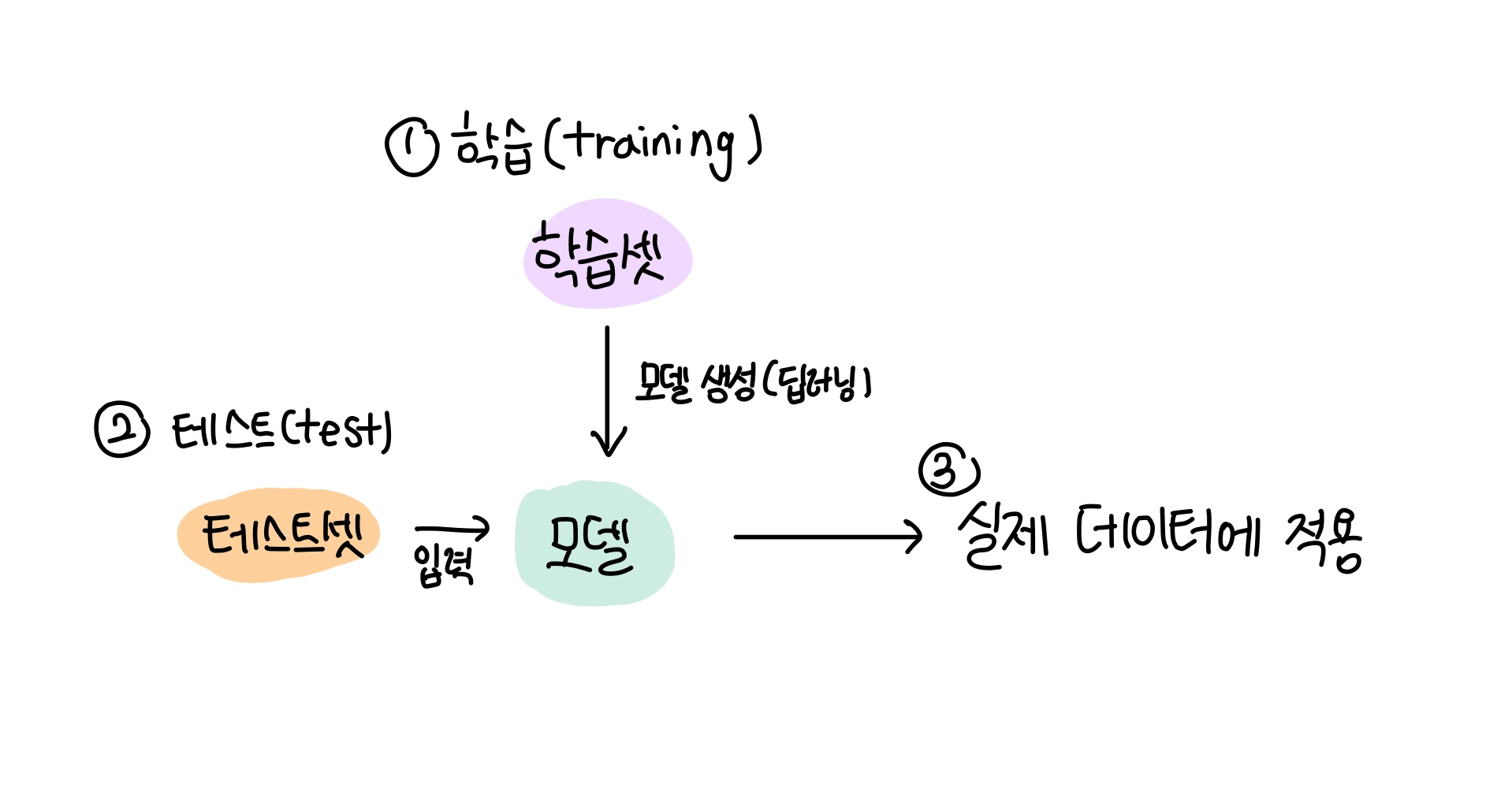 머신러닝 개발 과정
머신러닝 개발 과정
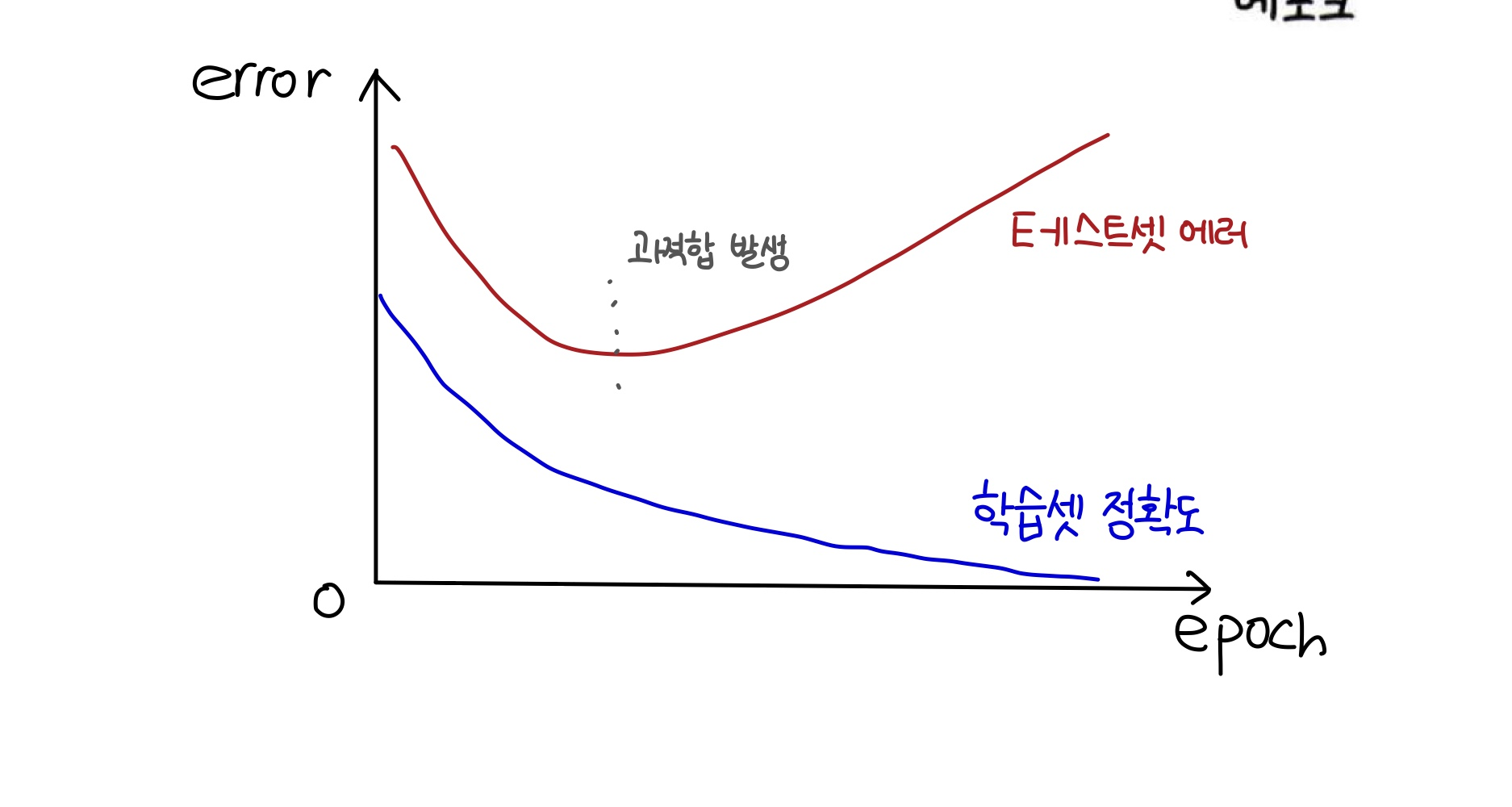 학습을 진행해도 테스트 결과가 더 이상 좋아지지 않는 지점에서 학습을 멈춰야 한다.
학습을 진행해도 테스트 결과가 더 이상 좋아지지 않는 지점에서 학습을 멈춰야 한다.
💻모델 저장과 재사용
from keras.models import load_model #모델을 저장하는 라이브러리
model2.save('my_model.h5') #모델을 저장
del model2 #메모리 내의 모델 삭제
model2 = load_model('my_model.h5') # 모델을 새로 불러오기아래의 메시지가 뜨면 성공이다
/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py:3103: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model( 불러온 모델을 다시 실행하면 아까와 같은 결과가 나온다
불러온 모델을 다시 실행하면 아까와 같은 결과가 나온다
📌K겹 교차 검증 (k-fold cross validation)
데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고, 나머지를 모두 합해서 학습셋으로 사용하는 방법
이 방법을 이용하면 가지고 있는 데이터를 모두 테스트셋으로 사용할 수 있다.
5겹 교차 검증 (5-fold cross validation) 예시
💻 k겹 교차 검증
#k겹 교차 검증 라이브러리
from sklearn.model_selection import StratifiedKFold
# 10개의 파일로 쪼갬
n_fold = 10
skf = StratifiedKFold(n_splits = n_fold, shuffle = True, random_state = seed)
# 빈 accuracy 배열
accuracy = []
# 모델의 설정, 컴파일, 실행
for train, test in skf.split(X1, Y1):
model3 = Sequential()
model3.add(Dense(24, input_dim = 60, activation = 'relu'))
model3.add(Dense(10, activation = 'relu'))
model3.add(Dense(1, activation = 'sigmoid'))
model3.compile(loss = 'mean_squared_error',
optimizer = 'adam',
metrics = ['accuracy'])
model3.fit(X1[train], Y1[train], epochs = 100, batch_size = 5)
k_accuracy = "%.4f" %(model3.evaluate(X1[test], Y1[test])[1])
accuracy.append(k_accuracy)
#결과 출력
print("\n %.f fold accuracy:"% n_fold, accuracy)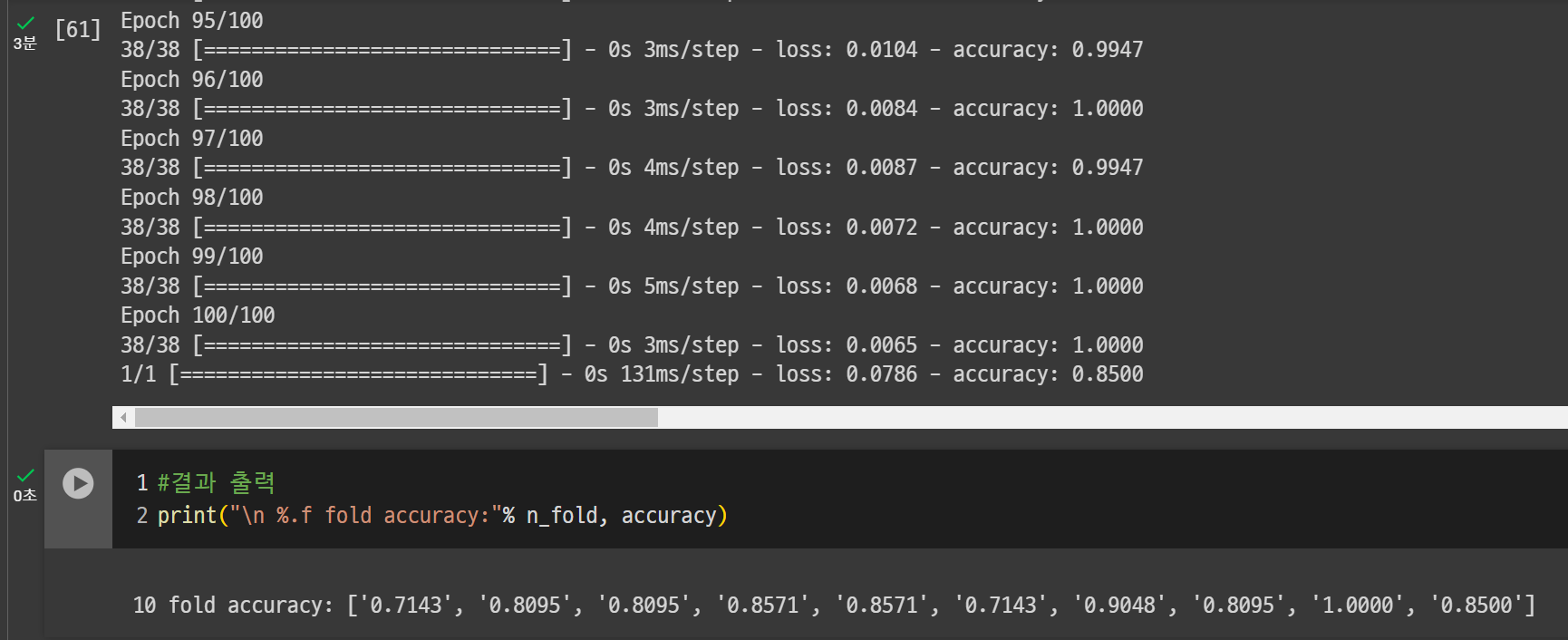 학습횟수가 늘어나다보니 평소보다 오래 걸렸다
학습횟수가 늘어나다보니 평소보다 오래 걸렸다

호로록