💻 와인의 종류 예측하기 : 데이터 확인과 실행
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import ModelCheckpoint, EarlyStopping
import pandas as pd
import numpy
import tensorflow as tf
import matplotlib.pyplot as plt
df_pre = pd.read_csv('/content/drive/MyDrive/AI_WINTER_STUDY/wine.csv', header=None)
#sample() 원본 데이터에서 정해진 비율만큼 랜덤으로 뽑아오는 함수
#frac = 1이면 원본 데이터의 100% 불러오는 함수
df = df_pre.sample(frac=1)
print(df.head(5))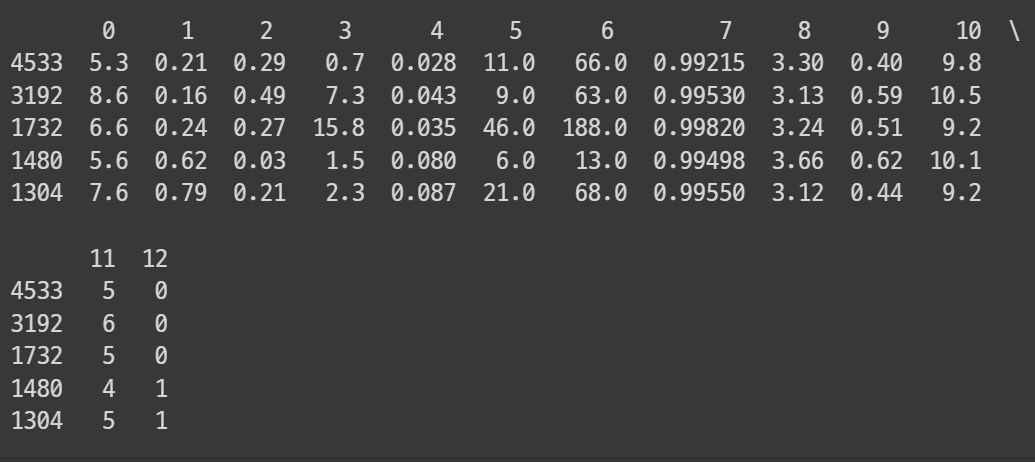
# seed set
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(3)
# data set
dataset = df.values
X = dataset [:,0:12]
Y = dataset [:,12]
# model set
model = Sequential()
model.add(Dense(30, input_dim=12, activation = 'relu'))
model.add(Dense(12, activation = 'relu'))
model.add(Dense(8, activation = 'relu'))
model.add(Dense(1, activation = 'sigmoid'))
#model compile
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
#model fit
model.fit(X, Y, epochs = 200, batch_size = 200)💻 모델 업데이트
from keras.callbacks import ModelCheckpoint
import os
#model save
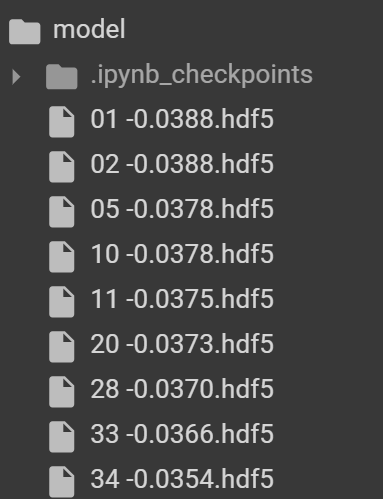
MODEL_DIR ='./model/' #모델 저장하는 폴더
if not os.path.exists(MODEL_DIR): #만일 위의 폴더가 존재하지 않으면
os.mkdir(MODEL_DIR) # 이 이름의 폴더를 만들어 준다
#모델 저장 조건 설정
modelpath = "./model/{epoch:02d} -{val_loss:.4f}.hdf5"
#테스트 오차는 keras 내부에서 val_loss로 기록
#정확도 (acc), 테스트셋 정확도(val_acc), 학습셋 오차(loss)
#함수의 모델이 앞서 저장한 모델보다 나아졌을 때만 저장하기 위해 save_best_only 설정
checkpointer = ModelCheckpoint(filepath = modelpath, monitor = 'val_loss',
verbose = 1, save_best_only = True) #verbose = 1, 해당 함수의 진행 사항 출력
#모델 학습할 때마다 위에서 정한 checkpointer의 값을 받아서 저장된 곳에 모델 저장
model.fit(X, Y, validation_split=0.2, epochs = 200, batch_size = 200,
verbose = 0, callbacks = [checkpointer])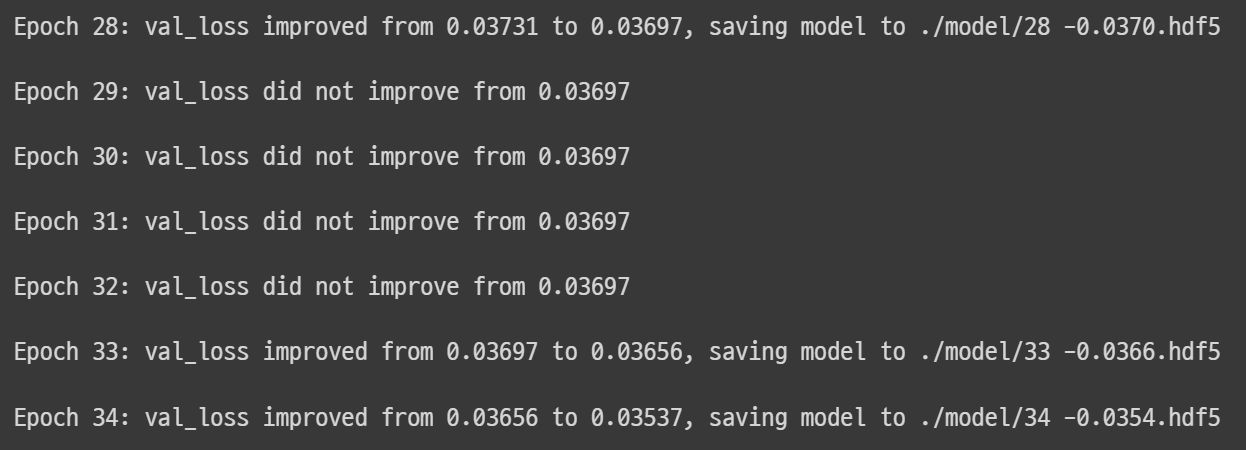
 테스트 오차를 실행한 결괏값이 향상되었을 때만 저장되는 것을 확인 가능
테스트 오차를 실행한 결괏값이 향상되었을 때만 저장되는 것을 확인 가능
💻 그래프로 확인
#y_vloss에 테스트셋으로 실험 결과의 오차 값을 저장
y_vloss = history.history['val_loss']
#y_acc에 학습셋으로 측정한 정확도의 값을 저장
y_acc = history.history['accuracy']
#x 값을 저장하고 정확도를 파란색으로, 오차를 빨간색으로 표시
x_len = numpy.arange(len(y_acc))
plt.plot(x_len, y_vloss, "o", c="red", markersize = 3) # 테스트셋
plt.plot(x_len, y_acc, "o", c="blue", markersize = 3) # 학습셋
plt.show()keras 2.3.0 release note:
acc 대신 accuracy 쓴 이유
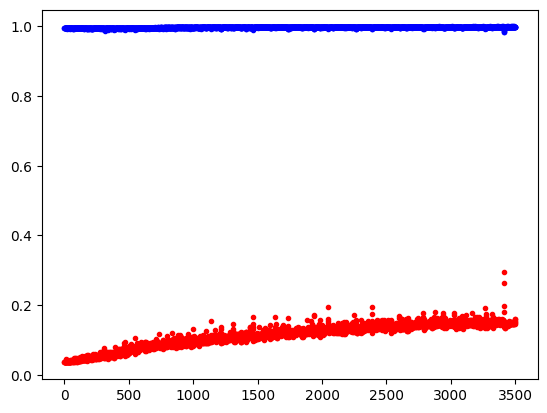 교재에는 학습셋의 정확도는 올라가지만 과적합 때문에 테스트셋의 실험 결과가 점점 나빠지게 된다고 쓰여있다. 실제로 내가 돌렸을 때에도 테스트셋 오차는 비슷한 양상을 보이고 있다. 아무래도 이 부분은 교재와 비슷하게 다시 도전해보아야 할 것 같다
교재에는 학습셋의 정확도는 올라가지만 과적합 때문에 테스트셋의 실험 결과가 점점 나빠지게 된다고 쓰여있다. 실제로 내가 돌렸을 때에도 테스트셋 오차는 비슷한 양상을 보이고 있다. 아무래도 이 부분은 교재와 비슷하게 다시 도전해보아야 할 것 같다
💻 학습의 자동 중단
from keras.callbacks import EarlyStopping
#학습의 자동 중단 설정, 테스트 오차가 좋지 않아도 100번 까지는 기다름
early_stopping_callback = EarlyStopping(monitor = 'val_loss', patience = 100)
#모델 실행
model.fit(X, Y, validation_split = 0.2, epochs = 2000,
batch_size = 500, callbacks = [early_stopping_callback]) epoch를 2000으로 설정했지만, 멈추는 것을 볼 수 있다. 이건 여러 번 돌려보았는데 그 때마다 횟수는 많이 차이 났다. 교재와는 숫자가 너무 많이 차이 나서 나중에 다른 데이터로도 시도해보아야겠다.
epoch를 2000으로 설정했지만, 멈추는 것을 볼 수 있다. 이건 여러 번 돌려보았는데 그 때마다 횟수는 많이 차이 났다. 교재와는 숫자가 너무 많이 차이 나서 나중에 다른 데이터로도 시도해보아야겠다.

호로록