
네트워크(Network)는 연결된 여러개의 컴퓨터들의 통신체계이다. 우리가 인터넷으로 무엇을 보는 것, 검색하는 것, 구매하는 것등의 모든 일련의 행동들이 이 네트워크 안에서 이뤄진다. 그럼, 대체 네트워크는 어떤 모양새로 생겼고, 이 안에서는 무슨일이 일어나길래 내가 원하는 정보가 나에까지 무사히 올 수 있는것일까?🧐
🛰 Network Architecture
Network Achitecture는 네트워크의 디자인이다. 수많은 컴퓨터와 장비들이 전송매체로 연결되어 데이터를 송수신하는 복잡한 시스템에서 통신의 최적화를 위해 의도적으로 만들어낸 네트워크의 모양새이다.
복잡한 시스템 -> 모듈화 -> 계층화 -> 추상화 -> 아키텍처
네트워크를 계층화해서 표현한 모형이 바로 OSI7계층이다
통신계층
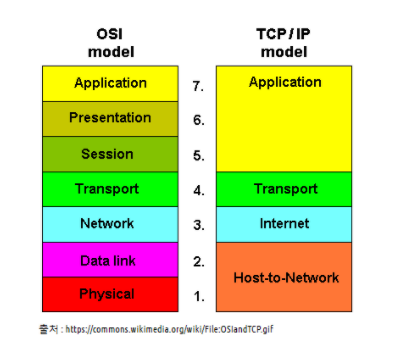
- Appliction:
- Presentation: 데이터의 변환, 압축, 암호화가 이루어지는 층으로 서로다른 통신기기간의 다른인코딩에 대한 대책
- Session: 세션을 열고 닫는 기능
- Transport: 서로 다른 두 네트워크 간의 전송을 담당(세그멘테이션, 흐름제어, 오류제어+오류복구)
- Network: IP, 라우터장비가 속한 계층으로 호스트에 IP번호를 부여하고, 해당도착지IP까지 최적의 경로를 찾아주는 기능(라우팅)을 제공한다.
- Datalink: 동일하 네트워크 간의 전송을 담당(오류제어, 흐름제어)
- Physical:
2Tier Architectrue
클라이언트 서버 아키텍처라고 하며, 리소스(데이터)가 존재하는 쪽과, 리소스를 사용하는 곳을 분리시킨 구조이다. 여기서 리소스를 사용하는 쪽이 '클라이언트', 리소스를 제공하는 쪽은 '서버'라고 한다. 항상 요청에 의한 응답만 존재한다.
3Tier Architectrue
2Tier에서 리소스를 저장하는 공간인 데이터베이스가 추가된 구조이다. 클라이언트 - 서버 - 데이터베이스 이렇게 구성된다. 여기서 서버는 리소스를 전달하는 역할을 하고 그 리소스들이 실제로 존재하는 곳을 데이터베이스가 된다.
🛰 Protocol
프로토콜(Protocol)은 클라이언트와 서버가 통신하기 위한 규칙이다. 무언가를 제공하는 서버를 가게로 보고, 요청하는 클라이언트를 손님이라고 봤을 때, 한국에서는 보통 한국말을 사용해서 요청을 하고 응답을 받는다. 프로토콜은 한국말 같이 통신에 필요한 부분을 정해놓은 약속이며 수단이다. 통신계층마다 정해진 여러 프로토콜이 존재한다.
HTTP: 웹에서 HTML, JSON등의 정보를 주고 받는 프로토콜
HTTPS: HTTP에서 보안이 강화된 프로토콜
FTP: 파일전송 프로토콜
SMTP: 메일 전송하기 위한 프로토콜
SSH: CLI화면의 원격 컴퓨터에 접속하기 위한 프로토콜
RDP: Windows계열의 원격 컴퓨터에 접속하기 위한 프로토콜
WebSocket: 실시간 통신, Push 등을 지원하는 프로토콜
TCP: HTTP, FTP통신의 근간이 되는 양방향 인터넷 프로토콜
UDP: 빠르지만 신뢰성이 낮은 단방향 인터넷 프로토콜
🛰 HTTP
HTTP(HyperText Transfer Protocol)로 문서를 전송하기 위해 만들어진 Application Layer의 프로토콜이다. 웹브라우저와 웹서버의 통신을 위해 디자인 되어 클라이언트가 HTTP messages 양식에 맞춰 요청을 보내면, 서버도 HTTP messages 양식에 맞춰 응답하는 형태를 가진다.
HTTP messages
클라이언트와 서버 사이에서 데이터가 교환되는 방식으로 요청과 응답이 있다.
요청과 응답은 아래와 같이 비슷한 구조를 가진다.
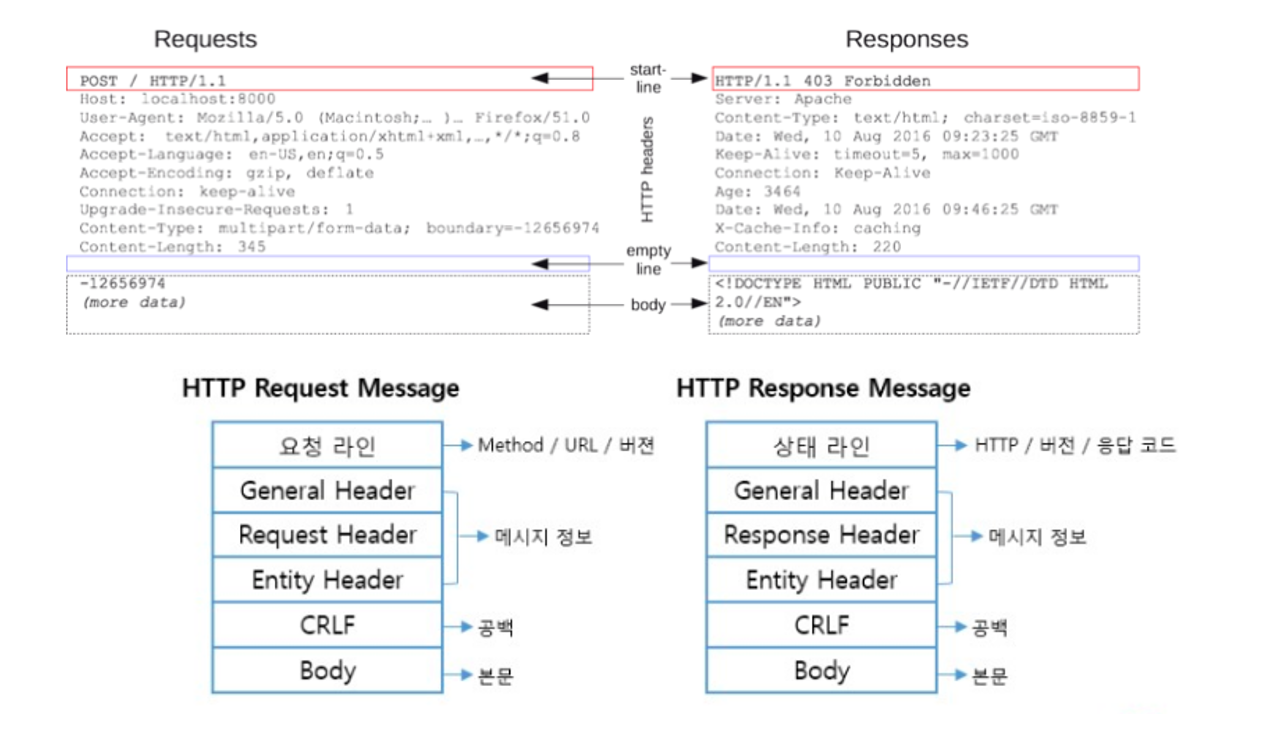
- star-line: 요청라인과 상태라인을 의미하고 요청이나 응답의 상태를 나타냄
- HTTP headers: 메세지정보에 해당하고, 요청을 지정하거나, 메세지에 포함된 본문을 설명
- empty line: 헤더와 본문을 구분하는 공백
- body: 요청이나 응답에 관련된 데이터나 문서를 포함
요청: 클라이언트가 서버에 보내는 메시지
- start-line: 수행할작업(GET, POST, ...), 요청대상, HTTP/버전
---> POST HTTP/1.1
---> GET http://developer.mozilla.org HTTP/1.1 - Headers: 대소문자 구분 없는 문자열과 콜론(:), 값을 입력
---> General headers: 메세지 전체에 적용
---> Request headers: 요청을 구체화
---> Entity headers: Content-Type, Content-Length - body: 구조의 마지막에 위치하고 선택적이다. 서버에 리소스의 조회를 요청하는 경우에는 필요치 않고 POST나 PUT과 같이 데이터의 변경을 요구할때 사용하며, Single-resource bodies(단일-리소스 본문)와 Multiple-resource bodies(다중-리소스 본문)가 있다.
응답: 서버가 클라이언트 요구에 응답하는 메세지
- start-line: 현재프로토콜의 버전 / 상태코드 상태
---> HTTP/1.1 200 OK - Headers
---> General headers : 메시지 전체에 적용
---> Response headers : 상태 줄에 넣기에는 공간이 부족했던 추가 정보를 제공
---> Entity headers : Content-Length와 같은 헤더는 body에 적용 body가 비어있는 경우 전송되지 않음 - body: 필요에 의해 선택적으로 전송됌
HTTP는 중요한 특성을 가지는데 바로 상태를 가지지 않는다(Stateless)는 것이다. HTTP로 통신하는 와중에는 클라이언트나 서버의 상태변화에 대해 일일이 체크하지 않고, 추적하지 않는다. 따라서 저장이 필요한 상태는 따로 쿠키-세션 등을 이용한다.
🛰 작동원리 - Invisible
URL과 URI
URL(Uniform Resource Locator)은 네트워크 상에서 파일이 위치하는 정보를 나타낸다.
scheme + hosts + url-path의 결합으로 표기된다.
- schema: 프로토콜
- hosts: 는 웹서버의 이름이나 도메인, IP주소이고, url-path
- url-path: 웹서버에서 지정한 루트 디렉토리부터의 파일경로와 이름
URI(Uniform Resource Identifier)은 URL에 query와 bookmark까지 포함한 주소이다.
- qeury: 클라이언트가 웹서버에 요구하는 추가적인 질문
프로토콜://주소/search?title='sexydressyJS' 이런식으로 사용
즉, URI가 URL을 포함하는 상위개념이다.
IP와 Port
IP address(Internet Protocol address)은 컴퓨터의 주소를 나태낼 때 사용하는 방식이다.
한국에 있는 무수히 많은 집들 중 내가 사는 집의 주소를 나타낼 때 도로명주소라는 체계를 사용하는 것처럼 네트워크 상에서 여러 컴퓨터들중 나의 컴퓨터가 있는 위치를 나타내기 위해 IP라는 체계을 사용한다. 즉, IP는 인터넷상에서 사용하는 주소체계이다.
그 중 IPv4는 4번째 버전을 의미한다. 보통 000.000.000.000 이렇게 표현되며, 0.0.0.0 ~ 255.255.255.255까지 나타낼 수 있다.
이 체계가 처음엔 문제되지 않았는데 점점 가정마다 컴퓨터 보급이 활발해지면서 사용할 수 있는 주소가 IPv4만으로는 감당 할 수 없게 되었다 그래서 나오게 된 것이 IPv6이다.
Port는 IP가 가르키는 PC에 접속 할 수 있는 통로이다. 한 통로를 이미 사용하고 있는 경우 중복해서 사용 할 수는 없다.
몇몇 포트번호는 주요 통신을 위한 규약으로 이미 정해져있다.
- 22: SSH
- 80: HTTP
- 443: HTTPS
Domain과 DNS
우리가 인터넷상에서 특정 사이트로 이동할 때, 보통 IP주소를 사용하지 않고 해당 사이트의 이름으로 표기된 URL을 사용해서 접속한다. 이 이름이 바로 도메인이다. 즉 IP가 주소를 나타냈다면 Domain은 그 주소에 실제로 존재하는 곳의 명칭을 나타낸다.
즉, IP가 '경기도 00시 00로'라면 도메인은 평화아파트 같은 이름과 같다.
네트워크 상에 모든 PC는 IP주소가 있지만 모두 도메인을 가지고 있는건 아니다. 도메인은 일정 기간 동안 빌려서 사용하는 것으로 도메인과 각각의 IP를 연결하는 작업이 필요하다. 그럼 어떻게 IP와 도메인을 연결 할 수 있을까?🤔
이 때 등장하는 개념이 DNS(Domain Name System)이다. DNS는 도메인 이름을 IP 주소로 변환하거나 IP를 도메인으로 변화해 주는 역할을 하는 데이터베이스 시스템이다. 이를 이용하여 도메인이 있는 사이트를 IP가 아닌 도메인으로 검색하여 이용할 수 있다.
🛰 작동원리 - Visible
AJAX
AJAX(Asynchronous Javascript And XMLHttpRequest)은 동적인 웹페이지를 만들기 위한 하나의 개발 기법이다. 즉, 클라이언트와 서버간에 데이터를 주고 받는 기법을 의미한다. AJAX를 구성하는 핵심기술은 Javascript, DOM, Fetch이다.
🤔 왜 사용해?
.
.
웹페이지 보면 일부에서만 새로운 내용을 불러와야 하는 순간들이 있다. 그 일부분때문에 모든 페이지를 다시 다 불러오는건 시간낭비, 자원낭비, 돈낭비다. AJAX은 이럴때, 그 일부의 데이터만 불러와서 교체해주는 역할을 한다. 그러면 전체 페이지를 다시 불러오지 않고도 필요한 부분에서만 서버로부터 데이터를 가져와서 로딩한다. 매우 절약적이며, 사용자도 매번 전체 페이지가 로드 될 때까지 기다릴 필요 없으므로 편리하다.
다만, AJAX는 상태를 기억하지 않기 때문에 뒤로가기 버튼의 구현은 다른 API를 통해서만 가능하다.
- Fetch
AJAX의 핵심기술 중 현재 가장 많이 사용하고 있는 HTTP 요청 전송 기능을 제공하는 Web API이며, 자바스크립트의 내장 라이브러리 이다.
서버와 비동기적으로 소통하며, 응답후의 수행할 로직을 .then으로 표현할 수 있다.
// 함수선언형
fetch('api주소')
.then(function(response){
return response.json();
})
.then(function(response){
// 응답후의 로직
});
// arrow 함수형
fetch('api주소')
.then(response => response.json())
.then(response => {
//응답후의 로직
});
SSR과 CSR
SSR과 CSR은 페이지가 렌더링 되는 위치로 구분된다.
SSR(Server Side Rendering)은 웹페이지를 서버에서 렌더링을 해서 브라우저로 보낸다. 브라우저가 다른 경로로 이동할 때마다 서버는 이를 반복한다.
CSR(Client Side Rendering)은 브라우저의 요청을 서버로 보내면 웹페이지골격 + Javascript파일을 클라이언트인 브라우저로 보내게 되고 이를 브라우저에서 렌더링 한다. 브라우저가 다른 경로로 이동시에 서버가 웹페이를 다시 보내지 않고 처음 서버로부터 받은 웹페이지 파일을 이용하여 동적으로 라우팅을 관리한다.
여기서, 라우팅이란 네트워크 안에서 데이터를 보낼 때 최적의 경로를 선택하는 과정을 의미한다.
🤔 그럼 어떻게 구분해서 사용할까?
.
.
SSR은
1. SEO(Search Engine Optimization)가 우선순위일때
2. 웹페이지의 첫 화면 렌더링이 빠르게 필요한 경우 ( 단일파일의 용량이 작기때문)
3. 웹페이가 사용자가 상호작용이 적은경우
CSR은
1. 지속적인 상호작용이 있는 경우
2. 웹 애플리케이션 제작시 더 나은 사용자 경험 제공 가능.
🛰 API
API(Application Programming Interface)는 형식이다.
우리가 한식전문점에 가서 파스타를 주문하지 않을 수 있는건 전문점에 이미 구비된 메뉴판 때문일 것이다. 메뉴판은 손님이 그 가게로부터 주문 할 수 있는게 무엇인지 눈으로 확인하여 알 수 있게 해준다. API도 이와 마찬가지이다. 특정 서버를 사용할 때, 그 서버에 무엇이 있는지 알아야 우리는 그 서버로부터 원하는 바를 요청할 수 있다. 이를 눈으로 확인 할 수 있도록 명시해 놓은 문서나 UI가 바로 API이다.
즉, API는 소프트웨어가 다른 소프트웨어로부터 지정된 형식으로 요청, 명령을 받을 수 있는 수단이다.
REST API
웹 애플리케이션에서는 CRUD로 구성된 GET, POST, DELETE, PUT(PATCH)등의 HTTP 메소드를 이용해 서버와 통신한다. API가 빈 스케치북처럼 있는게 아니라 택배송장양식처럼 무엇을 어디에 어떻게 작성해야 하는지에 대한 규약이 존재한다.
REST(Representational State Transfer) API는 그 규약중 장점을 최대한 활용할 수 있는 구조로 웹에서 사용되는 데이터나 자원(Resource)을 HTTP URI로 표현하고, HTTP 프로토콜을 통해 요청과 응답을 정의하는 방식이다.
🤔 RESP API를 어떻게 작성해야 모든 사람들이 한 눈에 알기 쉽게 보고 사용하는 좋은 RESP API를 만들 수 있을까?
.
.
다음 리처드슨(Richardson)의 4단계 모델을 살펴보자.
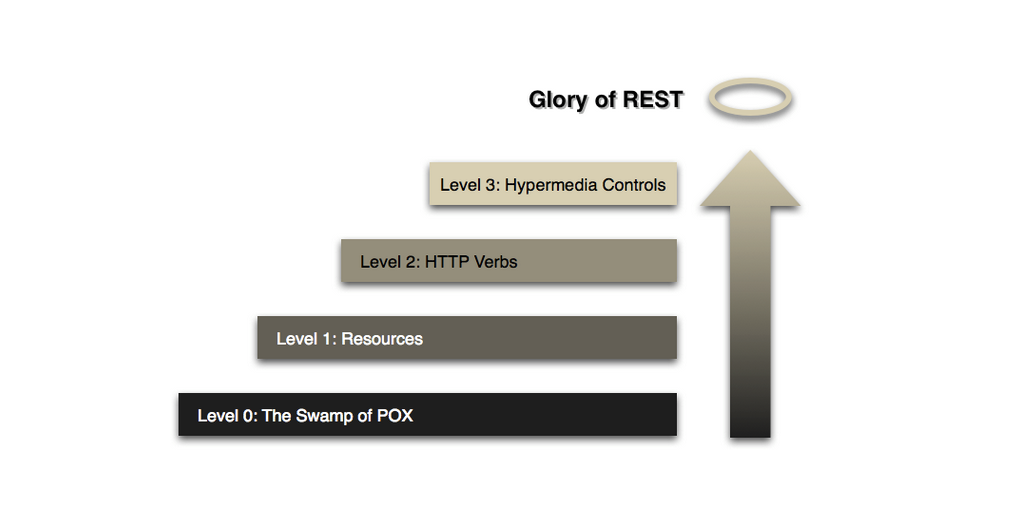
- 0단계: HTTP프로토콜을 사용
- 1단계: 요청의 맨 끝부분인 엔트포인트는 요청하는 리소스에 따라 각각 다르게 사용
---> 엔드포인트 작성시에는 동사, HTTP메소드, 행위에 대한 단어 - X, 요청하는 리소스에 대한 명사형태로 작성 - O - 2단계: CRUD에 맞게 적절한 HTTP 메소드를 사용
---> GET(READ), POST(CREATE), PUT & PACTH(UPDATE), DELETE(DELETE) - 3단계: HATEOAS(Hypertest As The Engine Of Application State) 적용한것으로 2단계에서 URI를 포함한 링크요소까지 삽입하여 작성
3단계까지... 이러다 다죽어😵
.
.
보통 2단계까지 적용하면 대체적으로 잘 작성된 API라 여겨지고 3단계까지 적용된 경우는 극히 드물기때문에 3단계 적용은 선택적이다.
Open API
정부에서 제공하는 공공데이터에 접근할 수 있는 통로이다. 공공데이터에 접속해서 원하는 데이터를 API에 맞게 가져다 사용할 수 있다.
API Key
집 문을 열기 위해서 키나 비밀번호가 필요한것처첨 API를 이용하기 위해서는 보통 API Key가 필요하다. 클라이언트는 이 키를 가지고 필요한 서버의 문을 열어 원하는 리소스에 접근 할 수 있다.
🤔 그럼 왜? KEY가 왜 필요할까?
.
.
돈 때문이야~~🎶🎶 (✖️ 2)
요청에 따라 서버가 응답 한다는 것은 결국 비용문제로 이어진다. 따라서 회원에게만 리소스를 제공 할 수 있도록 KEY를 발급하여 이용하도록 한다.
프로토콜 https://velog.io/@leo-xee/%ED%86%B5%EC%8B%A0%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C
rest성숙도모델 https://brunch.co.kr/@pubjinson/12
httpmessage https://developpaper.com/http-message/
http구조 https://velog.io/@teddybearjung/HTTP-%EA%B5%AC%EC%A1%B0-%EB%B0%8F-%ED%95%B5%EC%8B%AC-%EC%9A%94%EC%86%8C
