Abstract
-
본 논문은 conditional diffusion models를 기반으로 image-to-image 변환을 위한 통합 framework를 개발하고, 이 framework을 image-to-image변환(colorization, inpainting, uncropping, JPEG restoration)에 대해 평가한다.
-
본 논문에서 제안하는 간단한 image-to-image 모델은 hyper-parameter tuning, architecture customization 또는 auxiliary loss, 정교한 새 기술 없이 강력한 GAN및 regression baseline을 능가한다.
-
Denoising diffusion objective에서 L2 vs. L1 loss가 샘플 다양성에 미치는 영향을 발견하고, 연구를 통해 neural architecture에서 self-attention의 중요성을 입증한다.
-
평가 프로토콜은 ImageNet, 사람의 평가 및 샘플 품질 score(FIE, Inception Score, pretrained ResNet50의 분류 정확도, 원본 이미지에 대한 Perceptual distance)를 포함한다.
-
이 표준화된 평가 프로토콜이 image-to-image translation 연구를 지전시킬 것으로 기대된다.
-
Generalist, Multi-task diffusion model이 task-specific specialist counterparts보다 성능이 우수하다는 것을 보여준다.
(많은 task를 cover하는 일반적인 모델이 specific모델보다 성능이 우수하다는 뜻인듯)
1. Introduction
-
시각과 이미지 처리의 많은 문제들은 공식화 될 수 있다.
- Image-to-image 변환(이미지 복원, piel 수준의 이미지 이해)에 대한 자연스러운 접근법은 이미지의 고차원 공간에서 multi-modal distribution을 캡처할 수 있는 deep generative models를 사용하여 입력이 주어진 output 이미지의 조건부 분포를 학습하는 것이다.
-
GAN은 광범위하게 적용 가능하고 효율적이지만, 학습하기 어렵고 가끔 output에서 mode를 drop한다
-
최근 diffusion, score-based 모델이 급증했다.
- 이는 speech synthesis, ImageNet generation 문제에서 GAN기준선을 능가했고, SR에서 뛰어난 성능을 보였지만 일반적인 framework를 제공하는 GAN과 견줄 수 있는지는 명확하지 않다
-
따라서, 본 논문에서는 Palette의 일반적인 적용에 대한 가능성을 조사한다.
- Image-to-image diffusion model을 구현하여, 이미지에 대한 까다로운 작업 별 아키텍처에 대해 사용자 지정, hyper-parameter의 변경, 손실이없는 팔레트가 네 가지 작업(색칠, 인페인팅, uncropping, JEPG 복원)에 대해 high-fidelity outputs을 제공한다는 것을 보여준다.
-
본 논문에서는 denoising loss function과 neural net architecture를 포함한 Palette의 핵심 구성요소를 연구했다.
- L1, L2 loss가 유사한 sample-quality score를 산출했지만, L2는 샘플에서 더 높은 수준의 다양성으로 이어지는 반면 L1은 더 보수적인 출력을 산출했다.
- Fully convolutional model을 위해 Pallet의 U-Net architecture의 self-attention layer를 제거하면 성능이 저하된다.
- ImageNet을 기반으로 한 inpainting, uncropping, JPEG 복원을 위한 표준화된 평가 프로토콜을 제안한다.
3. Palette
- 확산 모델 vs 조건부 확산 모델
- 확산 모델:반복적인 denoising process를 통해 표준 가우시안 분포의 샘플을 경험 기반 분포의 샘플로 변환한다.
- 조건부 확산 모델:denoising 과정을 입력 신호에 따라 조건부로 생성한다.
Image-to-image diffusion model은 조건부 확산 모델이다.
𝑝(𝒚 | 𝒙)에서 x는 grayscale image, y는 color image를 뜻한다. 이 모델은 SR모델에 적용되었다. 본 논문에서는 image-to-image diffusion model을 광범위한 task에 적용하는 연구를 진행했다.
- Loss function
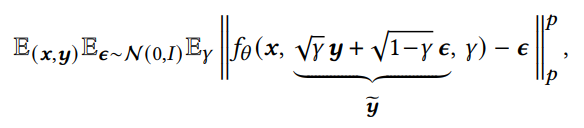
training output image y 를 감안하여, noise version인 y~를 생성하고 y~의 노이즈를 줄이기 위해 x와𝛾(noise level indicator)를 감안하여 𝑓𝜃를 학습한다.
- Architecture
- 파레트는 256*256 class-conditional U-Net구조를 기반모델로 사용한다.
- Palette와 U-Net의 차이점
1. Absence of class-conditioning
2. Additional conditioning of the source image via concatenation- Inference

Palette performs inference via the learned reverse
process.
4. Evaluation protocol
- 이전의 Image-to-image 변환 모델의 평가 방법
- colorization : FID, human evaluation
- inpainting, uncropping : qualitative 평가에 의존
- JPEG restoration : PSNR, SSIM
많은 작업에서 평가를 위한 표준화된 데이터 세트가 부족했다. 예를 들어, 방법별 분할이 있는 다른 테스트 세트가 평가에 사용된다.
-
ImageNet에서 인페인팅, uncropping, JPEG restoration을 위한 통합 평가 protocol을 제안한다. PSNR, SSIM과 같은 pixel수준의 메트릭은 SR과 같은 어려운(hallucination이 필요한) 작업에 대한 샘플 품질의 신뢰할 수 있는 척도가 아니기 때문에 피한다.
-
본 논문에서 제안하는 4가지 image-to-image 변환에 대한 automated quantitative measures
1. Inception Score (IS)- Fréchet Inception Distance (FID)
- Classification Accuracy (CA)
- Perceptual Distance (PD); Euclidean distance in Inception-v1 feature space.
-
human evaluation
fool rate:'어떤 이미지가 카메라로 촬영한 것인지 맞출 수 있는가?'라는 질문을 받았을 때, natural image보다 model output을 출력하는 인간의 비율
5. Experiments
- Colorization : grayscale의 이미지를 color로
- Inpainting : user-specified masked region을 채우자
- Uncropping : enlarge the image
- JPEG restoration : JPEG compression artifacts를 수정하자
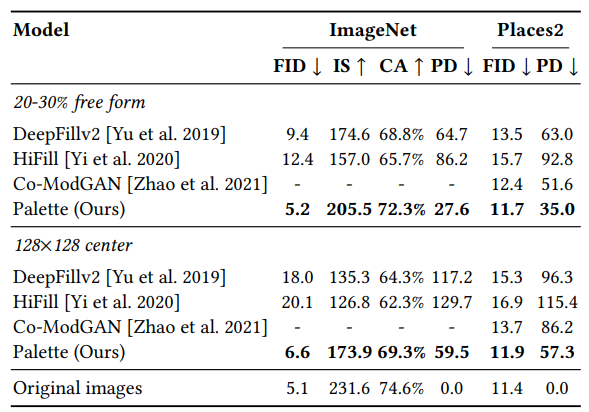
5.2 Inpainting

- 직사각형 mask로 증강된 Free-form generated mask로 inpainting model 학습
- Palette의 일반화를 유지하기 위해, binary mask를 모델에 전달하지 않는다.
- 대신, 가우시안 노이즈로 마스크 영역을 채운다.
-
train loss는 전체 이미지가 아닌 마스킹된 pixel만 고려한다
-
20~30% free-form mask의 경우 palette output에 대한 FID score가 원본 이미지의 FID score에 매우 가까웠다.
5.5 Self-attention in diffusion model architectures
- self-attention layer는 diffusion model을 위한 U-Net 구조에서 중요한 구성요소다.
- self-attention을 통해 layer는 global dependency를 제공하며, 보이지 않는 이미지의 해상도에 대한 일반화를 방지한다.
- 테스트 시 새로운 해상도로 일반화하는 것은 image-to-image 작업에 편리하며, 이전의 연구는 주로 fully convolution 구조에 의존했다.
- 본 논문에서는 self-attention layer가 인페인팅에 미치는 영향을 분석했다.
4 configurations
- Global Self-Attention
:3232, 1616, 8*8 해상도에서 global self-attention layer를 사용한 기본 구성 - Local Self-Attention
:feature map은 4개의 겹치지 않는 query block으로 분할된다. - More ResNet Blocks without Self-Attention
:더 깊은 convolution통해 receptive field 사이즈를 늘릴 수 있다. - Dilated Convolution without Self-Attention
:dilation rates가 증가하여 receptive filed가 기하급수적으로 증가한다.
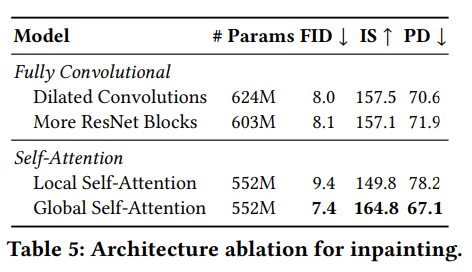
Self-Attention의 중요성(완전한 convolution보다 나은 성능), local이 global보다 성능 떨어진다.
5.7 Multi-tasking learning
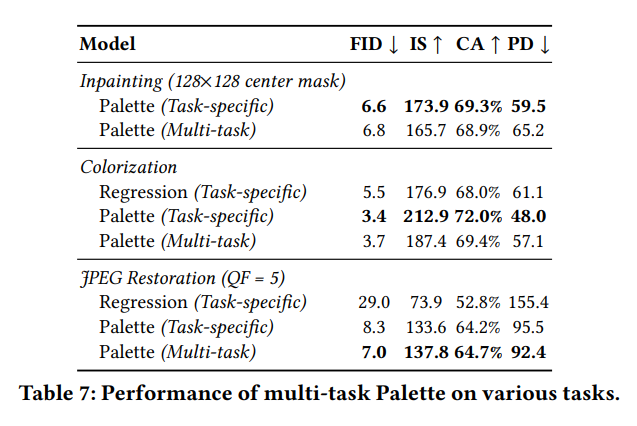
JPEG복원에서는 specific보다 뛰어나지만, colorization/inpainting에서는 뒤떨어진다.
Limitations
- 많은 refinement steps를 필요로한다
- GAN based model에 비해 느리다
- implicit biases
