아래 글을 참고하며 읽었다
https://wdprogrammer.tistory.com/71
Abstract
- 본 논문에서는 free-form mask와 guidance를 이용해 이미지를 완성하는 generative image inpainting 모델을 제안한다. 이 시스템은 추가적인 labelling efforts없이 수백만장의 이미지를 통해 학습된 gated convolution을 기반으로 한다.
- 제안된 gated conv모델은 vanilla conv(모든 input pixel 유효한것으로 취급)의 문제를 해결하고, 모든 레이어에 걸쳐 각 특정 위치의 각 채널에 학습 가능한 dynamic feature selection 방법을 제공하여 partial conv을 일반화한다.
- Free-form mask는 이미지의 모든 모양의 이미지에 어느 위치에서든 나타날 수 있으므로 직사각형 mask용으로 설계된 global/local GAN은 적용되지 않는다.
따라서 본 논문에서는 spectral-normailzed discriminator를 적용하여 SN-PatchGAN이라는 patch-base GAN loss를 제안한다. SN-PatchGAN은 단순한 formulation, 빠르고 안정적인 학습이라는 장점을 가진다.
1. Introduction
Image inpainting이란 missing region의 대체 contents를 합성하여 수정사항이 realistic하고 semantically correct 하게 이미지를 완성하는 기술이다. 이는 사진에서 object를 제거하거나 리터치하는 데 사용될 수 있다. 또한, image/video un-cropping, rotation, stitching, re-targeting, re-composition, compression, SR, harmonization 과 같은 영역으로 확장될 수 있다.
CV에서, 이미지 인페인팅에 대한 접근법은 다음과 같다.
1. patch matching using low-level image features [3,8,9]
- stationary textures를 합성할 수 있지만 복잡한 장면/얼굴/물체와 같은 non-stationary 상황에서는 실패할 수 있다.
2. feed-forward generative models with deep convolution networks
[15,49,45,46,38,37,48,26,52,33,35,19]
- 대규모 dataset에서 학습한 semantics를 활용해 end-to-end방식으로 이미지의 contents를 합성할 수 있다.
- vanilla conv 기반의 deep generative models는 이미지의 구멍을 채우는데 부적절하다. 왜냐하면 부분적으로 공유되는 conv filters가 모든 input pixels나 features를 같은 유효한 하나의 것으로 다룰 수 있기 때문이다.
- Vconv는 모든 valid/invalid/mixed(구멍 경계에 있는 필터) pixels,fueatures에 같은 필터를 적용하므로 artifacts를 생성한다.
3. Partial Convolution
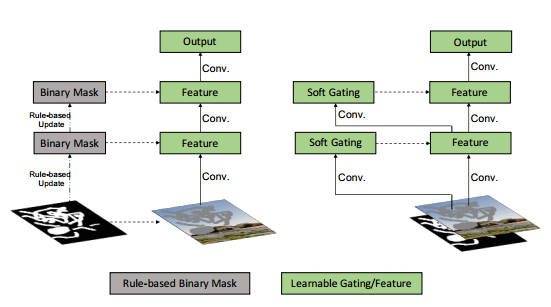
2의 한계를 해결하기 위해 Partial conv에서는 convolution이 마스킹되고 유효한 픽셀에서만 조건화되도록 정규화된다. 그다음 rule-based mask-update단계를 거치며 다음 layer의 유효한 위치를 업데이트한다.
즉, Pconv는 모든 입력 위치를 valid/invalid로 분류하고 0또는1마스크를 모든 layer의 input에 곱한다. mask는 학습할 수 없는 단일 feature gating 채널로 볼 수 있지만 이는 몇몇의 limitations가 있다.
따라서 본 논문에서는 free-form image inapinting을 위한 gated convolution을 제안한다. 이는 각각의 channel과 spatial location을 위한 dynamic feature gating mechanism을 학습한다.
네트워크의 구성은 Gconv를 쌓아서 encoder-decoder 네트워크를 형성한다. 또, inpainting network는 상황 별 attention module을 동일한 refine network(stage2)에 통합하여 long-dependency를 더 잘 포착한다.
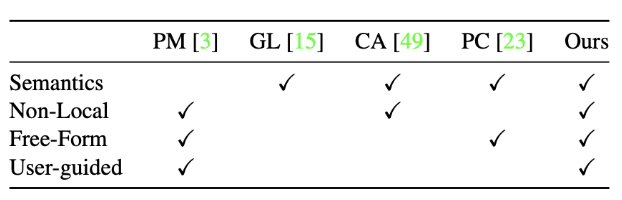
PatchMatch, Global&Local, Context Attention, Partial Conv, 본 논문의 기법을 비교
Main contributions
- Gated convolution을 제안한다. 이는 모든 layer에 걸쳐 각 채널을 위한 공간적인 위치에서 dynamic feature selection 방법을 학습한다. 따라서 색깔의 일관성과 free-form mask, input의 퀄리티를 개선한다.
- free-form image inapinting을 위해서 practical patch-based Gan discriminator에서 나아가, SN-PathchGAN 을 제안한다. 빠르고, 결과의 퀄리티가 좋다.
- 사용자가 요구하는 인페인팅 결과를 위해서, user sketch를 guidance로 사용가능하게 했다. (interactive inpainting model)
- 이전 벤치마크 데이터셋의 SOTA 보다 inpainting 퀄리티가 좋다. 사용자는 빠르게 제거하려는 물체를 삭제하고, 이미지 레이아웃을 수정하고, 워터마크를 지우고, 얼굴을 수정하는 것이 가능하다.
2. Related Work
2.1 Automatic Image Inpainting
2.2 Guided Image Inpainting and Synthesis
2.3 Feature-wise Gating
3. Approach
Partial Conv의 한계
- 모든 spatial location을 경험 기반으로(heuristically) valid인지 invalid인지 분류한다.
- 다음 layer의 mask는 몇개의 pixels가 필터에 의해 커버되는지에 상관없이 설정된다.
- ex.현재 마스크를 업데이트하기 위해서, valid pixel 1개와 valid pixels 9개가 동일하게 처리된다
- 즉, mask가 1로 업데이트 된 두 개의 feature중 하나는 filter가 1개의 valid pixel을 생성하고, 또 다른 하나는 filter가 9개의 valid pixels를 생성했다고 할 때, 두 features에 해당하는 mask가 동일하게 업데이트된다는 점은 불균형하다.
- User guided image inpainting이 불가능하다.
- 즉, user input과 호환되지 않는다.
- 본 논문에서는 사용자가 condition channel로 mask 내부에 sketch를 선택적으로 제공할 수 있는 이미지 인페인팅 시스템을 목표로 한다.
- Layer를 지날 때 마다 invalid pixels(features)가 줄어들고, 모든 mask값은 결국 1로 변환된다.
- 이 문제를 해결하기 위해 본 논문에서 제시하는 gated convolution이 최적의 mask를 자동으로 학습하도록 하면, 네트워크가 깊은 층에서도 모든 spatial 위치에 soft mask값을 할당한다는 것을 보여준다.
- 각 layer의 모든 channels가 같은 mask를 공유한다.
- 유연성이 제한된다.
- 학습할 수 없는 단일 채널 하드 게이트
3.1 Gated Convolution
- soft mask : 데이터로부터 자동으로 마스크를 학습한다.
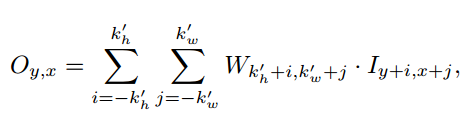
Partial Conv와 Gated Conv
Gated Convolution Formulation

Wg와 Wf는 각각 다른 convolution filter이다.
(y,x)의 gating과 feature를 구하고, 각각 activation function과 시그모이드를 거쳐 element-wise하면 (y,x)의 output값이 나온다.
3.2 Spectral-Normalized Markovian Discriminator(SN-PatchGAN)
-
본 논문에서는 free-form mask를 위해 SN_PatchGAN 네트워크를 제안한다.
-
CNN으로 이루어진 discriminator는 3개의 입력을 받는다.
- RGB Channels(Image)
- Mask Channels(Binary mask)
- Sketch Channels (guidance channel)
세개의 input을 받아 3D-feature of shape을 출력한다.

- 위의 그림과 같이 6개의 strided convolutions(kernel size 5, stride 2)를 쌓아서 Markovian patches의 feature statistics 를 캡쳐한다.
Markovian GANs는 GAN의 계산적 효율성 이슈를 해결하기 위한 기술이다. 본 논문에서는 local patches의 통계만을 capture하는 deep Markovian models에만 집중했다.
- GAN 학습을 안정화하기 위해 spectral normalization을 채택했다.
Inpainting network의 최종 loss는 pixel-wise L1 loss, SN-PatchGAN loss를 사용했다.
3.3 Inpainting Network Architecture
전체적인 네트워크의 구조는 아래와 같다.(Coars and refienment network)
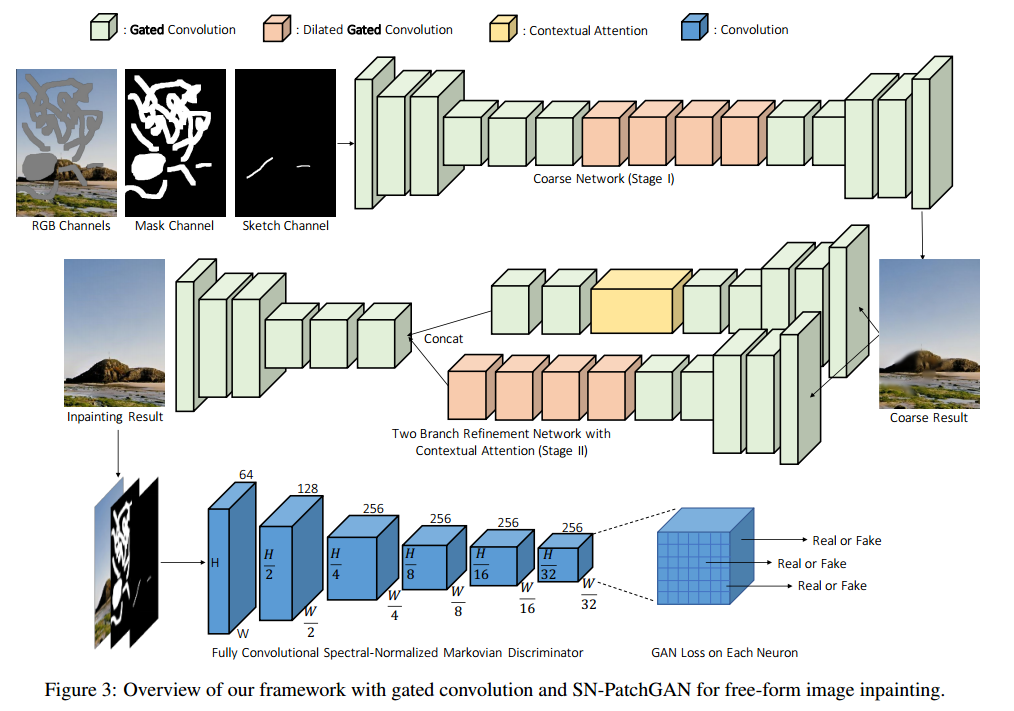
- coarse network(stage 1)과 refinement network(stage 2)는 partial conv에서 사용한 Unet대신 간단한 Encoder-Decoder 네트워크를 사용했다.
- Unet의 skip-connection은 디테일한 색상이나 텍스쳐 정보를 propagate할 수 없다.
- Encoder-decoder 네트워크+gated convolutions는 hole 경계면에서 seamless 결과를 생성한다.
- 모든 vanila convolution을 gated convolution으로 대체했다.
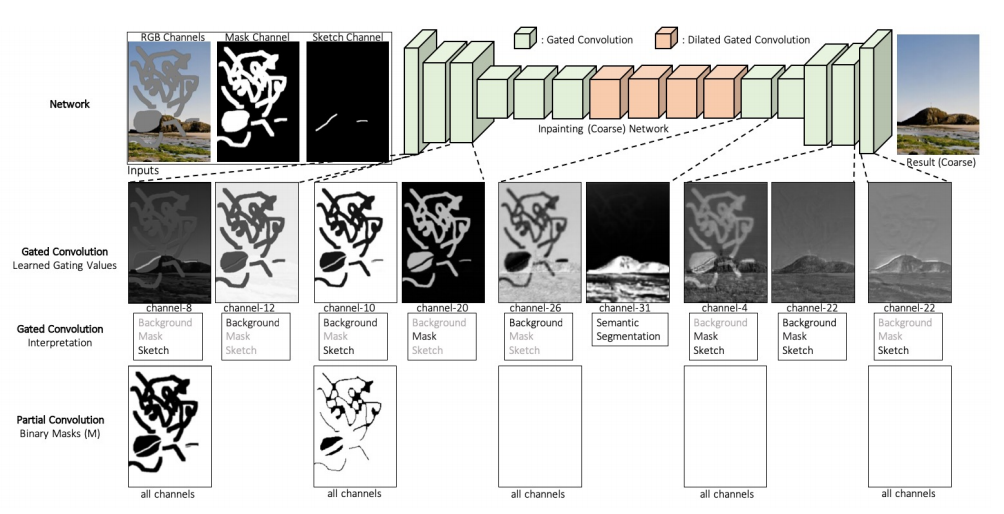
각 Layer를 거칠 때 Gated conv와 Partial Conv의 차이점이다.
PConv는 각 layer를 거칠 때 마다 mask가 업데이트된다.
3.4 Free-Form Mask Generation

훈련 중에 무작위 자유 형식 마스크를 자동으로 즉시 생성하는 알고리즘을 소개하고있다.
3.5 Extension to User-Guided Image Inpainting
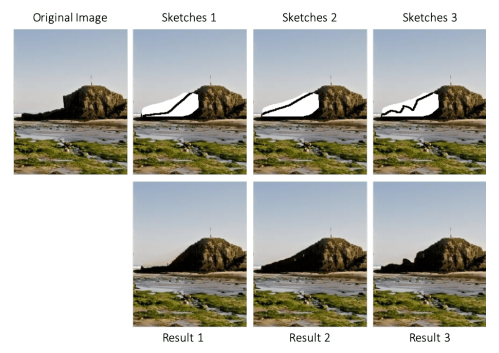
user-guidance를 추가적인 channel로 입력하여 user-guided inpainting을 할 수 있다.
