종프 주제였던 NLP!!! 그 때 아무것도 모르고 Kochat 모델만 돌리느라 너무 힘들었다... 이번에 제대로 NLP 기초부터 공부해야지
자연어처리 요소기술
자연어처리 활용 분야
자연어처리는 검색, 기계번역, 챗봇, QnA등 모든 대화형 인터페이스에서 사용 가능하고 대용량 텍스트 분석에 사용된다.
챗봇, 리뷰 분석, 기계 번역, 식당 예약, 고객 지원 상담, Voice interface, 소셜미디어 분석, 텍스트마이닝 등의 여러 분야에서 NLP가 사용된다
NLP란?
NLP란 Natural Language Processing의 약어로, sw를 이용해서 인간의 자연 언어를 처리하고 이용하는 연구 분야다.
자연어 처리의 목표는 인간 언어로 sw/hw와 소통하여 원하는 task를 수행하는 것, 자연어로 된 컨텐츠를 분석하여 비즈니스에서 사용가능한 insight를 도출하는 것이다
Natural Language Interface
NLP application(logic)의 input은 음성/텍스트이고, output은 사용자가 요청한 task가 달성된 state나 사용자의 질문에 대한 대답이다
NLP application의 결과물
- 정보검색:검색 키워드를 포함한 컨텐츠(문서, 이미지, 영상)
- 기계번역:원문의 의미를 동일하게 전달하는 번역된 문장
- 챗봇:입력으로부터 사용자의 의도를 분석하고 요청 task를 수행하거나 질문에 대한 답을 제공한다
- 텍스트 마이닝(비정형 텍스트 분석):분류/군집, 키워드 추출, 감성분석을 통해 비즈니스 insight를 도출한다
형태소분석&품사태깅
형태소 분석의 모호성
동일한 surface form 어절이 여러 형태소 결합으로 분석이 가능하다
품사 태깅(Parts-of-Speech Tagging)
- 품사 태그:형태소 분석의 기준이 되는 세분화된 품사 체계
- 형태소 분석의 모호성을 해결할 수 있다
- 문맥에 맞는 품사태그를 선택한다
- 대량의 품사 태깅 말뭉치를 구축하고 확률이 높은 품사 태그를 선택한다
- 기계학습&딥러닝이 사용될 수 있다
- Hidden Markov Model(HMM)기반 품사 태깅: 대량의 품사태깅이 된 말뭉치 기반의 통계적 기법이다
ex. Birds like flowers라는 문장이 있으면
형태소 사전에는
bird: Noun(N), like:Verb(V), Preposition(P), flower: Noun(N)이 저장되어있으므로
가능한 품사 태그열은 (N, V, N), (N, P, N)이다.
Pr(N, V, N) = Pr(V|N) x Pr(N|V) x pr(birds|N) x Pr(like|V) x Pr(flowers|N)
형태소 분석시 문제점
- 전처리: 띄어쓰기 오류, 맞춤법 오류 등이 있으면 제대로된 형태소 분석이 불가능하다
- 미등록어: 신조어, 전문용어, 축약어, 외국어 등이 나오면 품사를 추정해야한다
- 지속적인 사전 업데이트: 사전 구축 프로세스와 관리 툴이 필요하다
전처리(Preprocessing)
- 전처리가 필요한 이유: 학습 데이터 품질 향상 및 sw 성능 향상, 불필요한 데이터를 제거(Cleansing), Normalization(외국어 표기 통일)
- 전처리 종류: 욕설/비속어 필터링, 맞춤법 교정, 축약어 처리 등등
규칙&패턴 기반 자연어처리
개체명 인식(Named Entity Recognition, NER)
누가, 무엇(누구)을, 언제, 어디서, 얼마나 와 같은 정보를 인식한다
NER은 정보 추출과 관련된 task의 기초가 된다
개체명 태깅 기법(BIO 태깅)
BIO(Beginning-Inside-Outside)태깅은 개체명 태깅 방법 중 하나다.
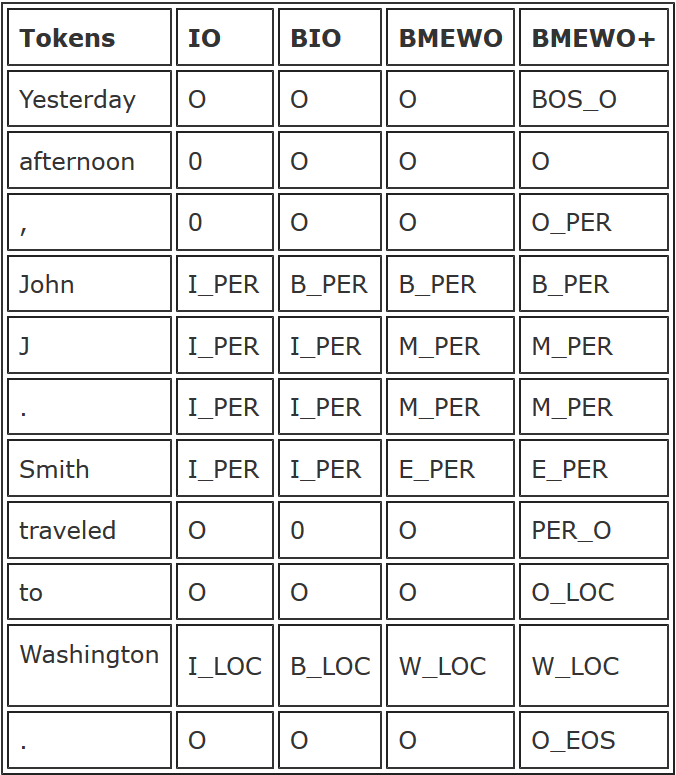
위 표의 BIO처럼 개체명 인식을 통해 문장을 분석한다
John J와 Smith를 사람으로, Washington을 location 개체명으로 분석했다
구문 분석(Syntax Analysis)
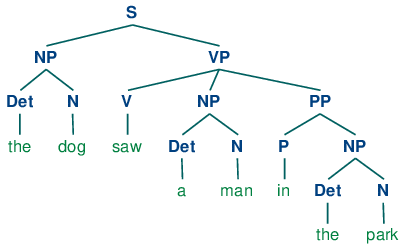
위 그림처럼 언어별 문법과 lexicon(어휘의 품사/속성정보 담긴 사전)기반으로 문장의 구문 구조를 분석한다
자연어 몬장을 sw가 computation 가능한 Tree형태로 표현하는 것이다.
구문 분석의 모호성
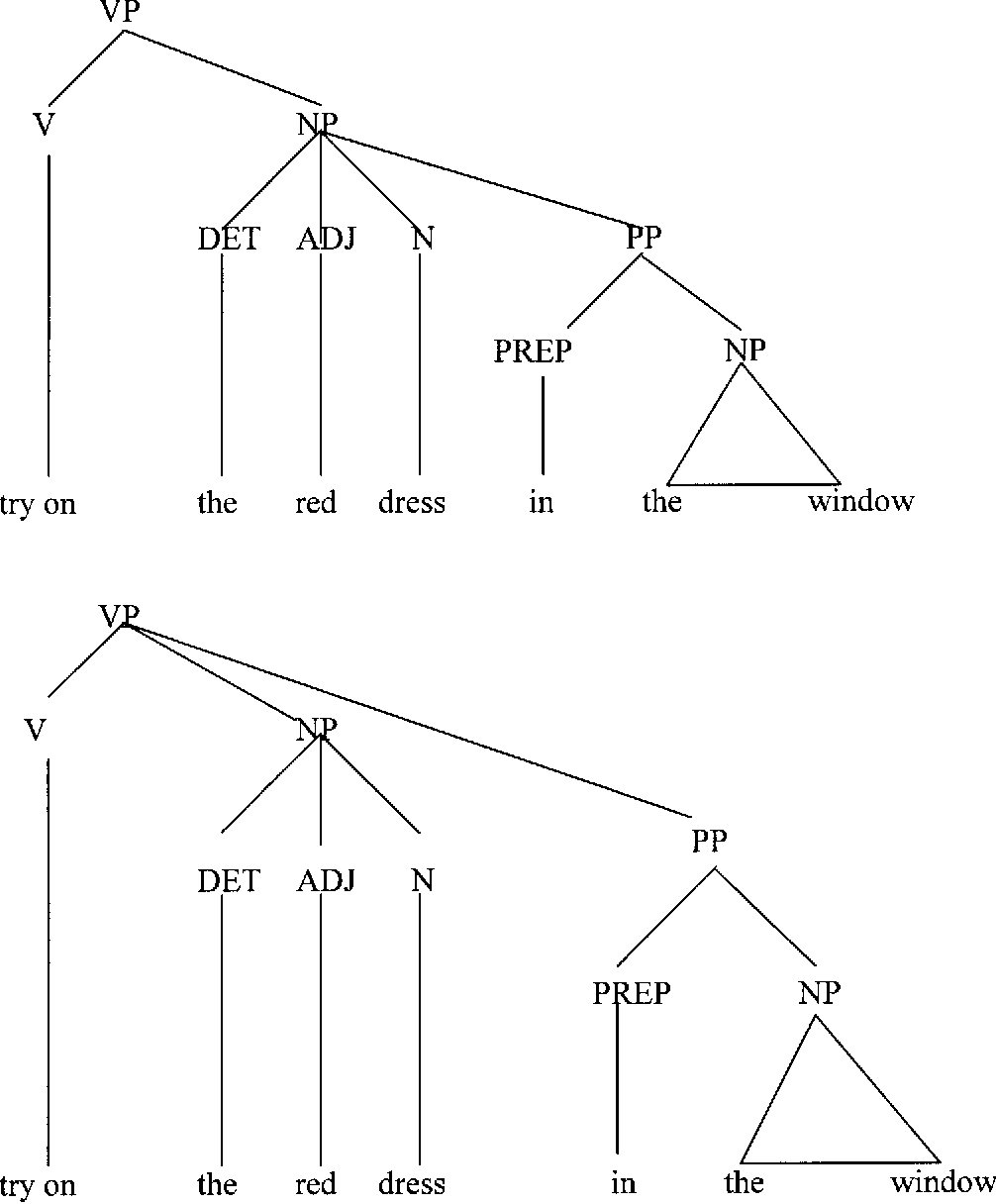
위처럼 하나의 입력 문장이 여러 구조로 분석 가능하다는 문제가 있다.
패턴 매칭
예를 들어 '출생지'에 대한 구문 패턴을 살펴보면
A는B에서 태어나다, A는 B에서 탄생하다 두 문장이 있다
이는 모두 출생지(A,B):A의 출생지는 B이다.
라는 공통적인 패턴을 가진다. 이 때 A는 사람, B는 장소일 때만 매칭된다
패턴매칭 기반 의도 분석
사용자의 입력 문장을 분석해 사용자의 의도를 분석한다.
ex. "이번달 휴대폰 요금 조회"라는 문장이 주어지면
[("이번달", NGG), ("전기요금", NNG), ("조회", NNG)] 로 형태소 분석이 가능하고
Read_Bill(month="이번달")과 같이 의도분석이 가능하다.
따라서 이번달 전기요금에 대해 응답해줄 수 있다
기존 자연어처리
기존의 자연어처리는 언어 자원(형태소 사전, 개체명 사전, 감성어 사전, 기분석 사전 등등..)에 규칙기반&패턴기반을 적용하여 구문을 분석했다
규칙기반 자연어 처리의 장단점
- 장점
- 구축 패턴이 정확하고 언어 자원이 충분하면 좋은 성능을 보여준다
- 특정 카테고리를 추가하고 제거하는 등 즉각적인 반응이 가능하다 - 단점
- 리소스 구축에 돈과 시간이 많이 든다
- 새로운 도메인에 대한 적용이 힘들다
- 패턴을 계속 유지관리 해야한다. 매칭 시 충돌이 발생할 수 있기 때문에
말뭉치(Corpus)
말뭉치란? 언어 연구를 위해 목적을 가지고 언어 표본을 추출한 집합이다.
기계학습, 딥러닝을 위한 학습 데이터로 사용될 수 있다
(원시 말뭉치, 품사 태깅된 말뭉치, 개체명 태깅된 말뭉치, 정답 레이블링 된 말뭉치 등등..)
