NLP와 기계학습
지도학습(이진 분류, Binary classification)
ex. 뉴스가 주어질 때 뉴스의 카테고리를 정치 or 스포츠로 분류한다
feature representation을 통해 카테고리에 대한 결정 경계를 학습하고 분류 결과를 도출한다
비지도학습
text가 주어질 때 주제별로 비슷한 text를 군집화(Clustering)을 통해 분류한다
자연어처리와 기계학습
대부분의 자연어처리 문제들은 분류 문제 로 해결 가능하다
- 자동 띄어쓰기(Automatic word spacing)는 이진분류(True, False)로 해결 가능하다
- 개체명 인식(Named entity recognition)은 다중 분류 문제로 해결할 수 있다
문서 벡터화
문서의 표현
- Bag of Words
: 문서를 단어의 집합으로 간주하여 문서에 나타나는 단어들은 feature로 간주되고 출현 빈도에 따라 가중치를 얻는다. - Feature Selection
:학습 문서에 출현한 term의 부분 집합을 선택한다. Noise feature를 ㅈ거하여 분류의 정확도를 높이고 WordNet등 어휘 리소스를 활용해 단어를 확장해나간다. - 사람이 이해하는 표현을 기계가 이해할 수 있는 표현으로 전환한다
- 의미적인 표현을 수학적인 표현으로 변환한다
①Term extraction:문서를 term단위로 분해하여 term을 추출하는 것
- 추출 단위: 어절(띄어쓰기 단위), 형태소(형태소 분석 결과), N-gram(Bi-gram, Tri-gram)
→Term extraction 수행 후 가나다 순으로 Term Ordering을 진행한다
②Vocabulary Generation: 추출한 Term으로 Term Vocabulary를 생성하여 Term ID로 변환한다
- Document 집합에 있는 Term을 사전화한다
- Filtering:Stop words(조사, 어미, 관사, 접속사 등 고빈도 기능어 제거), 제외어(욕설, 비적합 단어 제거)
- Document Frequency Count(DF):단어가 포함된 문서의 개수
- Ordering
- Term ID 부여
Stop word list:너무 자주 출현해서 문서를 변별하는 특색이 없어 쓸모없는 단어를 제외한다. 단, 의미상 관련된 용어는 포함시켜야된다
③Document Transformation
Term을 ID로 바꿔 Vocabulary에 없는 단어를 제거하고, Term의 문서 내 frequency를 센다
④Document Weighting
- Weight Vector로 문서를 표현한다
Weighting 기법: TF or TF x IDF, Probability
모델에 따라 term에 부여되는 가중치가 다르다
IDF(Inverse Document Frequency)
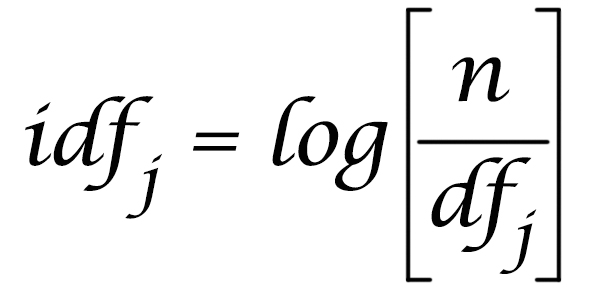
N: 문서집합(collection)의 총 문서수
df:문서 빈도(document frequency)
tf:용어 빈도(term frequency)
TF-IDF 값
TF와 IDF를 결합하여 각 용어의 가중치를 계산한다
문서D에 나타난 용어t에 부여되는 가중치는 다음과 같다
TF-IDF(t,D)=TF x IDF
- 적은 수의 문서에 용어 t가 많이나타나면 가중치가 높아진다
- 용어가 적게 나타나면 낮은 값을 가진다
- 모든 문서 안에 그 용어가 나타날 경우 가장 낮은 값
문서 유사성
벡터 스페이스 모델
- Term Vector Model
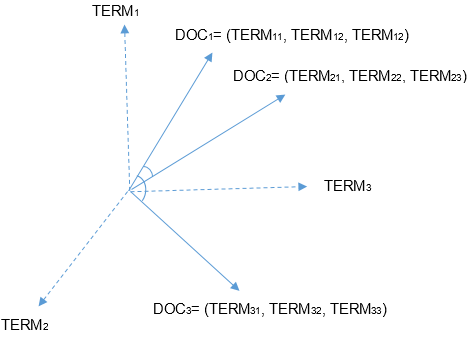
Document를 Term space의 Vector로 가정하여 벡터 간 유사도를 계산하여 유사성을 비교한다
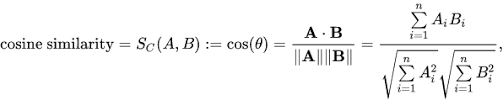
문서 유사성 계산
문서 분류
- 대량의 문서를 자동으로 분류하고 컨테츠를 필터링, 의도 분석, 감성 분류, 이메일 분류 등에 사용 가능하다
문서 분류 알고리즘
KNN(k-Nearest Neighbors), Naive Bayes Classifier, Support Vector Machine, 딥러닝 기반의 CNN, RNN, BERT등
KNN
분류하고자 하는 데이터와 가장 가까운 k개의 데이터를 비교한다
- Distance Weighted KNN:가까운 데이터를 더 고려한다. Weight = 1 / distance
나이브 베이즈(Naive Bayes Classifier)
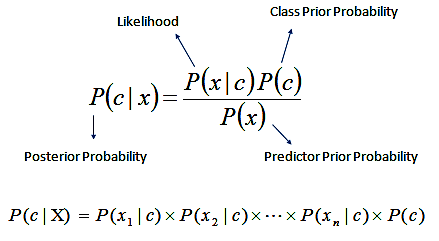
x:분류될 문장, c:클래스(긍정, 부정, 중립), P(c|x):x가 출현했을 때 c일 확률
사후확률 P(c|x)는 계산하기 어려우므로 베이지안 룰로 확률을 계산한다
최종적으로 변형된 조건부 확률을 통해 가장 큰 확률을 얻는 클래스로 분류한다
