시각지능
시각지능의 목표는 컴퓨터가 이미지를 이해하게 하는 것이다.
Visual Recognition Problems
Object Detection, Semantic Segmentation, Image Classification, Action Classification, Captioning 과 같은 과제들이 있다
Pixel(픽셀)이란?
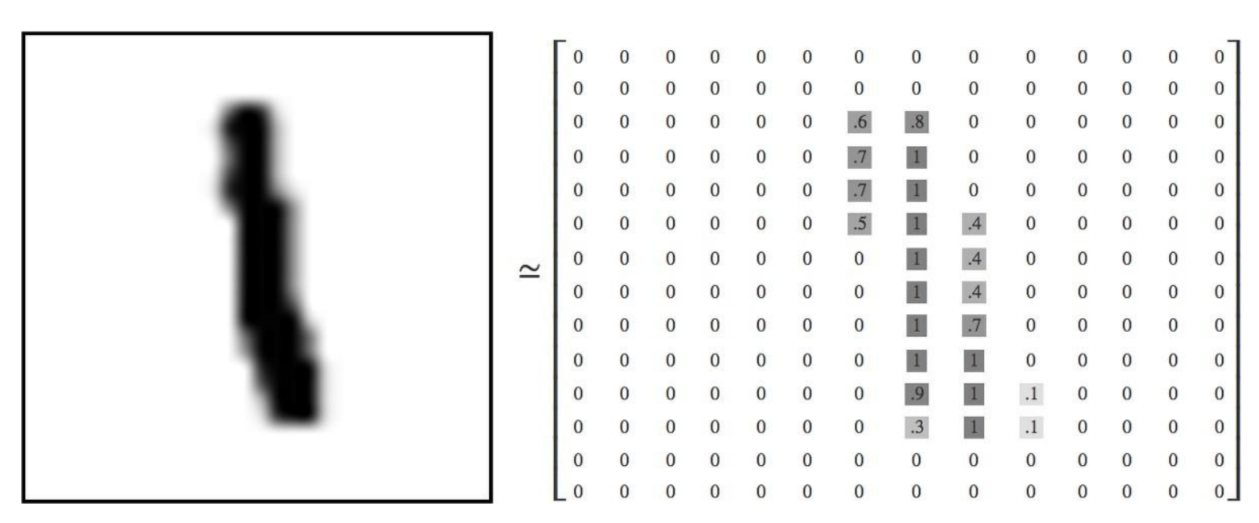
picture element - 화면을 구성하는 가장 기본이 되는 단위를 말한다
컴퓨터에게 경계를 가르치려면?
컴퓨터에게 객체의 외곽선을 가르치려면 어떻게 하는게 좋을까?

다음과같은 픽셀을 가지는 그림의 경계를 가르치려면
미분을 이용해서 값이 급격히 변화하는 곳을 모두 찾아서 연결하면 된다
하지만, 실제로 경계를 찾아보면 여러 예외 상황에 의해 경계의 일부가 제대로 찾아지지 않거나, 찾은 경계에 노이즈가 존재하는 경우가 있다.
컴퓨터에게 이미지, 혹은 Edge를 찾으라고 학습시킬 때,
한 object는 빛, 각도, 카메라의 각도, 물체의 상태 등등 각종 상황에 따라 다양한 데이터가 존재하기 때문에 찾기 어렵다.
Feature의 등장
컴퓨터에게 Edge, layer, motion, scale등을 가르쳐 객체를 분류할 수 있게 하려는 시도가 있었지만, 유의미한 수준까지 성능을 끌어올리지 못했다.
그래서 등장한게 바로 "특정 이미지 조각"인 Feature를 가지고 이미지를 분류할 수 있게 만드는 것이다.
Deep learning & CNN
CNN은 다음과 같은 과정으로 이미지를 인식한다.
1. feature를 본다
2. 각 feature가 조합된 패턴을 본다
3. 점점 더 복잡한 조합의 패턴을 본다
4. 반응하는 여러 패턴의 조합을 통해 이미지를 인식한다
이 때, 이미지의 필터(feature)를 CNN이 스스로 학습한다.
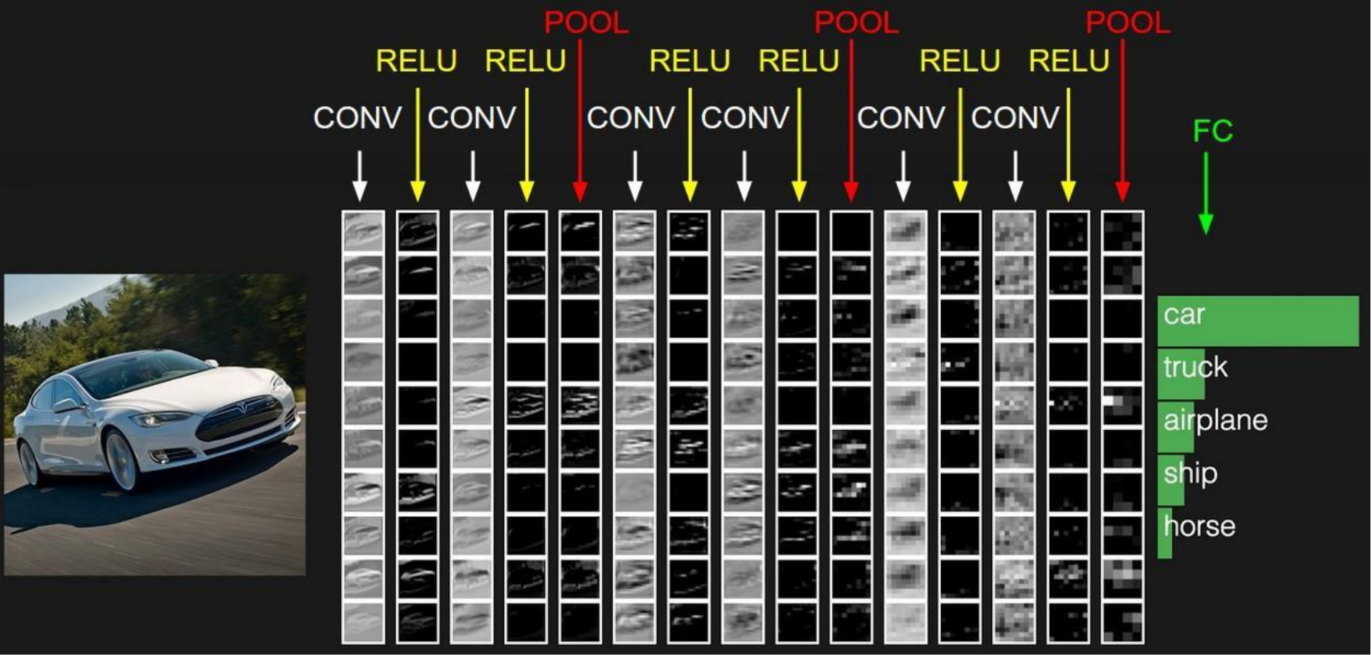
위 그림과 같이 이미지가 컨볼루션, activation function, pooling layer를 거쳐 추출된 feature들이 FC층을 거쳐 각 object에 대한 확률값으로 나타난다. 이 때 가장 높은 확률값을 가지는 class로 추측하는 것이다.
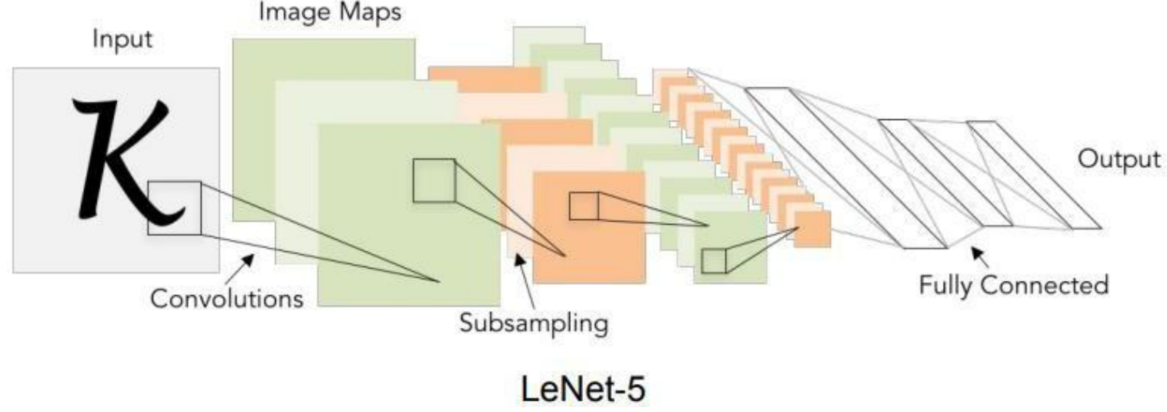
이미지를 훑으며 convolution layer롤 통과한 이미지의 feature map들이 Fully connected 층을 거쳐 결과를 도출하는 모습이다.
LeNet
CNN모델 중 하나인 LeNet을 보며 이해해보자. LeNet은 CNN개념을 최초로 제안한 Tann LeCun이 개발한 모델이다.
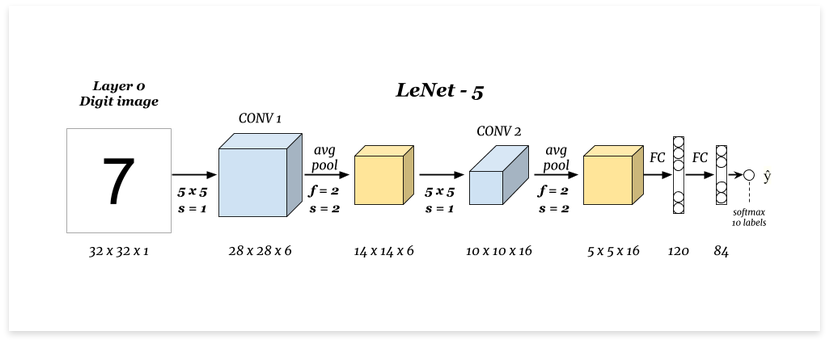
-
7이라는 숫자값이 적힌 이미지가 input으로 주어진다. 크기는 32x32이고, 마지막의 1은 이미지가 흑백(gray scale)이라는 의미이다.
만약 RGB라면 32x32x3이다. -
input image가 5x5크기의 convolution 연산을 통해 6개의 28x28 크기의 featuremap을 생성했다.
-
Average pooling을 통해 각각의 fliter에 대해 평균값을 계산하여 feature map의 크기를 14x14로 줄인다.
-
위 과정을 사이즈를 바꿔 반복하고, Fully-connected neural network로 84개의 결과를 unit에 연결시킨다.
