워드 임베딩 개요(Word Embedding)
데이터를 어떻게 표현해야 쉽게 문제를 해결할 수 있을까?
전통적인 단어 표현방법(Word Representation)

-
Bag-of-word: 0과 1로 이루어진 벡터로 단어를 나타냈다. ex."one-hot" representation, 1-of-V coding, discrete representation
-
벡터의 차원 = |전체 사전의 크기|
-
벡터의 유사도를 계산해 단어의 유사도를 판별했다
Context
문맥 정보를 사용해 단어를 표현해보자. 문맥정보를 어디서부터 어디까지 반영해야할까?(co-occurrence matrix)
- Term-document matrix
- Term-term matrix
Term-document matrix

벡터가 비슷하면 두 단어가 유사하고, 벡터가 비슷하면 두 문서가 유사하다
Term-term matrix
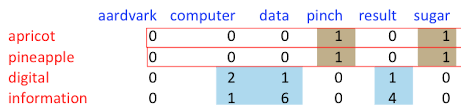
문맥 정보를 문서 대신 주변 단어로 한정(Sliding window_
Word embedding
-
word-word co-occurrence matrix의 문제점은 단어가 늘어날 수록 차원이 커져 저장 공간이 많이 필요하다. 단어의 matrix가 sparse representation이다
-
워드 임베딩: 중요한 정보만 남기고 적은 차원에서 단어를 표현한다
-
단어를 d차원의 실수 벡터로 표현한다(real-value dense vector)
ex. "커피" = (0.565465, -0.68484, 0.563...)
d<|vocabulary| -
predictive-base: 단어에서 문맥을 예측, 문맥에서 단어를 예측, word2vec(Skip-gram, CBOW)
Word2vec
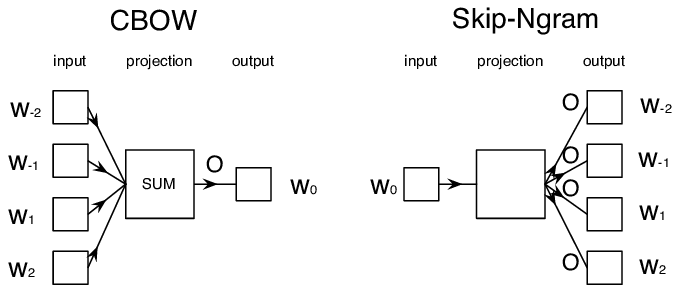
CBOW는 context words를 입력으로 받아 center word를 예측하고,
Skip-gram은 center word로부터 context words를 예측한다
Continuous bag-of-word(CBOW)
학습용 데이터셋
주변 단어로부터 center word를 예측하기 때문에 슬라이딩 윈도우 방식으로 데이터셋을 구축한다
CBOW 구조
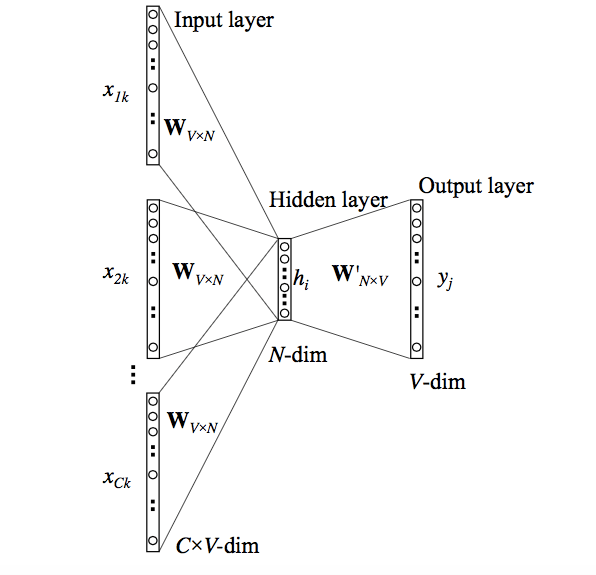
- Projection layer의 크기는 임베딩벡터의 차원(N)과 같다. 따라서 각 단어의 임베딩 벡터 차원은 N이다.
- V는 단어 집합의 크기(Bocaburary)
- Input layer-projection layer사이의 가중치 벡터는 VxM행렬
- projection layer-output layer사이의 가중치 벡터는 MxV행렬
- 서로 다른 두 개의 가중치 벡터가 학습 전에 랜덤값으로 초기화된다
- 중심 단어 예측을 위해 이 두 개의 가중치 벡터를 학습해나가는 것이 CBOW 모델이다
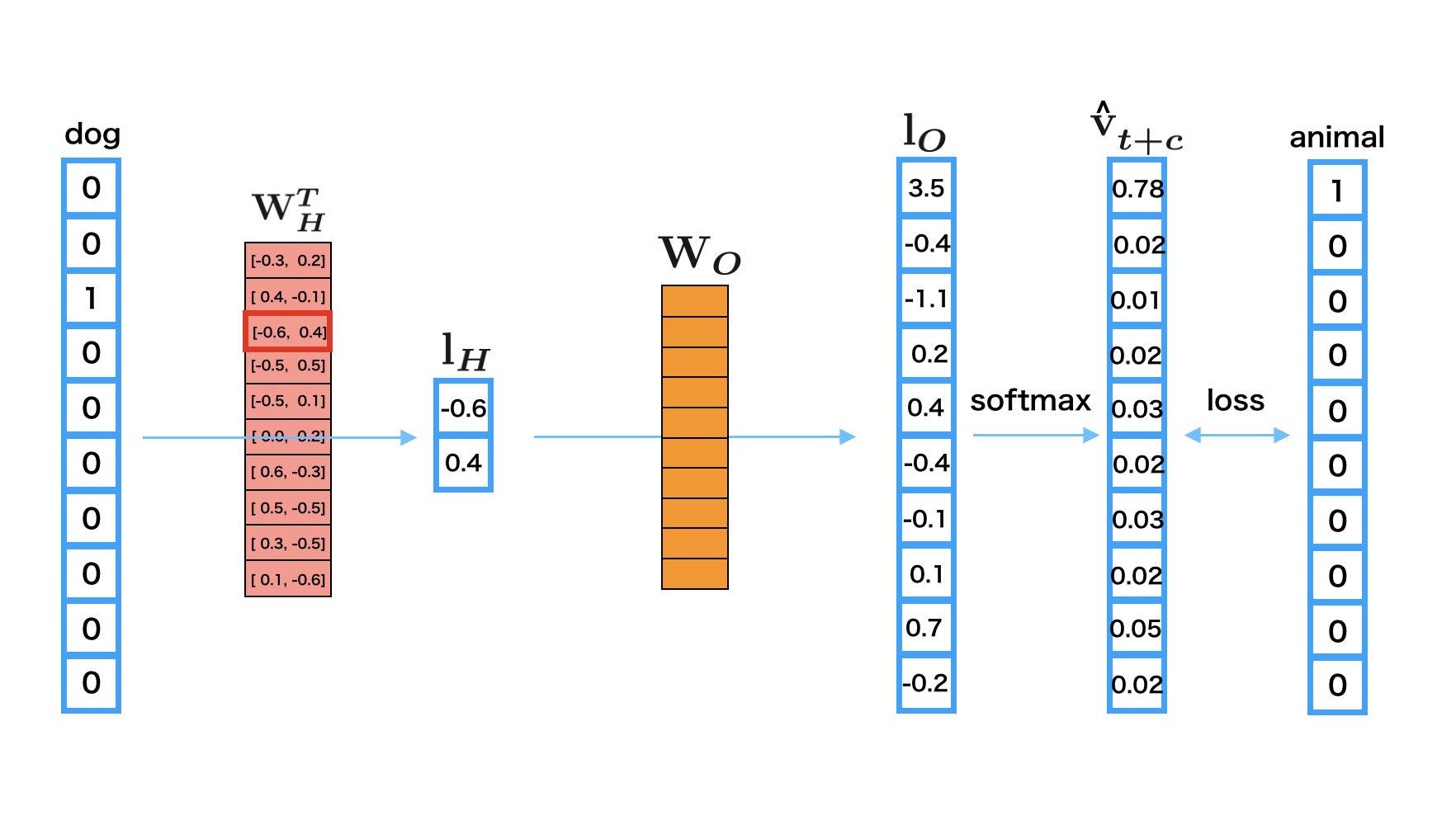
Skip-gram
학습용 데이터셋

중심 단어에서 주변 단어를 예측하므로 문장의 각 단어에 대해 window size만큼의 단어가 데이터셋으로 주어진다
Context words
예문 1) 나는 어제 밤에 사과와 식빵을 먹었다
input word가 사과, window size=2일 때
(사과, 나)
(사과, 어제)
(사과, 밤)
(사과, 식빵)
으로 context word가 추출되고
예문 2) 나는 어제 밤에 자두와 식빵을 먹었다
에서 '사과'와 '자두'는 유사한 context에서 나타나므로 유사한 단어 벡터를 가진다
Word Analogy
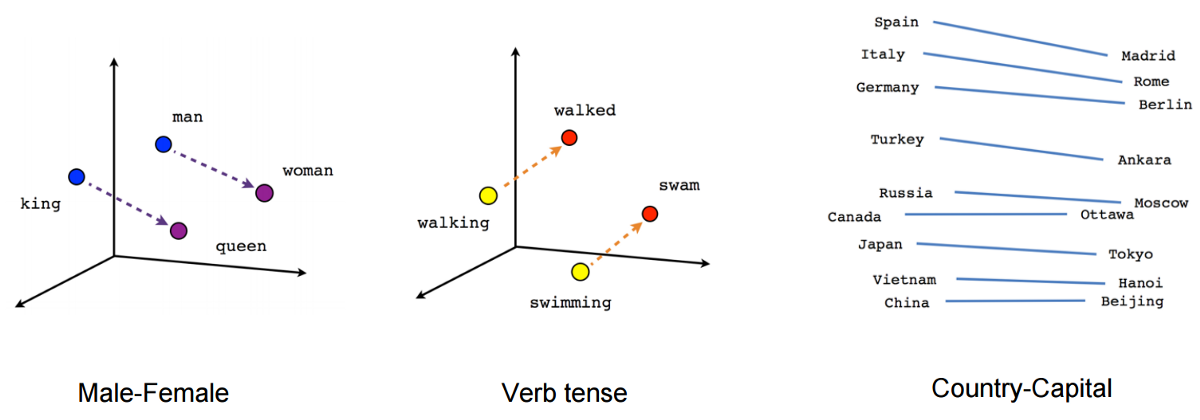
벡터공간에서 유사한 단어는 가깝게 분포한다
Italy:Rome = Vietnam:? 에서 ?를 예측가능하다
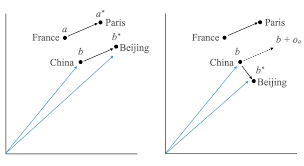
위와같이 단어간의 관계를 파악해 예측 가능


워딩이 좋지 않아요