Text Mining이란 대규모 텍스트 자료에서 가치있는 정보를 찾아내는 것
상용 텍스트 마이닝
키워드 언급량 분석(실시간 언급 추이, 변화량), 이슈어 분석(연관어 분석), 문서 분류(감성 분석, 감정 분석), 문서 클러스터링, 개체명 인식(도메인 별 사전 필요), 인플루언서 분석, 캠페인 성과 분석 등등
문서 클러스터링
문서 분류(Document Classification)
스팸메일 분류, 문서 카테고리 분류, 감성 분석, 사용자 의도 분석 등
문서 크러스터링(Document Clustering)
클러스터링은 비지도 학습으로 문서가 속할 그룹의 정답이 정해져있지 않음
ex. K-means clustering, DBSCAN 등
K-means clustering
주어진 데이터를 k개의 그룹(클러스터)로 분할한다.
중심 기반 분할 기법으로 유사한 데이터는 centroid와 가까이 분포할 것이라는 가정을 기반으로 동작한다.
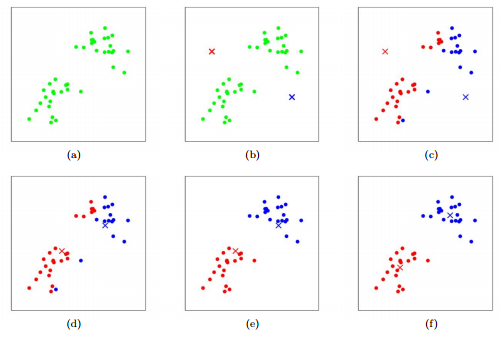
1. 데이터 집합에서 k개의 데이터 포인트를 임의로 추출하여 이 포인트를 클러스터의 중심으로 설정
2. 데이터 집합의 각 데이터와 k개의 클러스터 centroid와의 거리를 구해 가장 가까운 centroid의 클러스터에 할당한다
3. 새로 할당된 클러스터의 중심으로 centroid를 업데이트 한다
4. 각 데이터 포인트가 속하는 클러스터가 바뀌지 않을 때 까지 반복한다
DBSCAN(Density-Based Spatial Clustering of Application with Noise)
- 밀도 기반의 클러스터링 알고리즘으로, 노이즈가 있는 대규모 데이터에 적용할 수 있다.
- 데이터 포인트 p를 중심으로 eps반경 내에 min_samples이상의 데이터 포인트가 존재하면 클러스터로 인식하고 p는 중심점이 된다
- 클러스터의 개수를 미리 지정할 필요가 없고 이상치를 효과적으로 제외할 수 있다
- 클러스터와 비슷하지 않지만 가장 가깝다는 이유만으로 클러스터에 강제 배정되는 것을 막을 수 있다
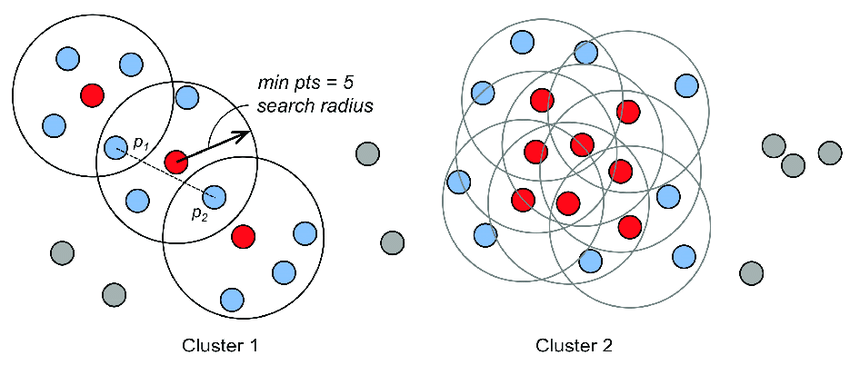
DBSCAN은
1. 데이터 포인트 p를 중심으로 epsilon 반경 내에 n개 이상의 데이터 포인트가 있으면 p를 중심으로한 클러스터를 생성한다
2. 한 core point가 다른 core point클러스터의 일부가 되면 두 군집은 서로 연결되어있다고 간주하여 하나의 군집으로 묶는다
3. 군집에는 속하지만 core point가 아닌 데이터 포인트를 border point라고 한다

DBSCAN의 단점은 밀도가 다른 양상을 보일 때 군집 분석을 하지 못한다. 밀도가 낮은 영역의 데이터는 군집으로 인식하지 못하고 노이즈로 남겨두게 된다
키워드 추출
문서 요약(Text Summarization)
문서의 내용을 요약하는 기술이다
- Extractive Summarization(추출 요약)
:주어진 문서 내에서 문서를 대표할 수 있는 키워드나 핵심 문장을 선택하여 문서를 요약한다. 통계 기반으로 작동 - Abstractive Summarization(추상 요약)
:같은 의미의 다른 표현(paraphrasing)을 사용하거나 새로운 단어를 사용하여 요약문을 생성. 학습데이터를 기반으로 한 지도학습을 사용한다
TextRank 기반 키워드 추출
TextRank란 그래프 기반의 text summarization 기법이다.
그래프 기반 랭킹 알고리즘인 PageRank를 사용하여 문서 내 키워드 또는 핵심 문장을 추출한다
PageRank
pagerank 알고리즘은 이 글을 참고했다.
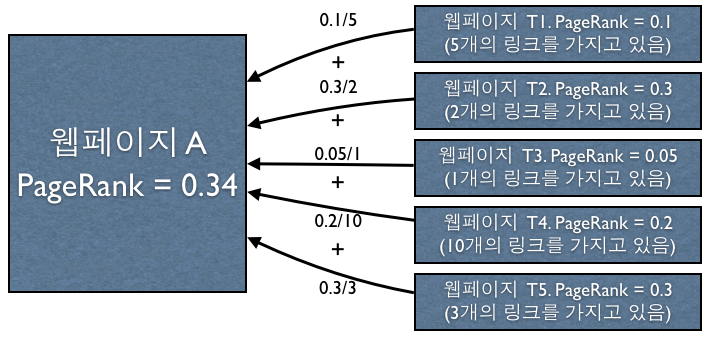
Pagerank를 계산하는 수식은 아래와 같다
PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn))
PR(A)는 웹페이지 A의 Pagerank이고, T1, T2..는 페이지A로 향하는 링크를 가진 다른 페이지다. d는 damping factor로 인접한 웹페이지로 이동할 확률을 뜻한다.(Pagerank에서는 0.85로 설정)
C(T1)은 T1페이지가 가진 총 링크의 수를 나타낸다.
어떤 페이지 A의 페이지 랭크는 그 페이지를 인용하고 있는 다른 페이지 T1, T2, T3, .. 가 가진 페이지 랭크를 정규화시킨 값의 합이라고 할 수 있다.
PR(A)를 구하기 위해서는 PR(T1), PR(T2).. 가 필요하기 때문에 PR을 구하는 식은 재귀적인 함수라고 할 수 있다.
TextRank
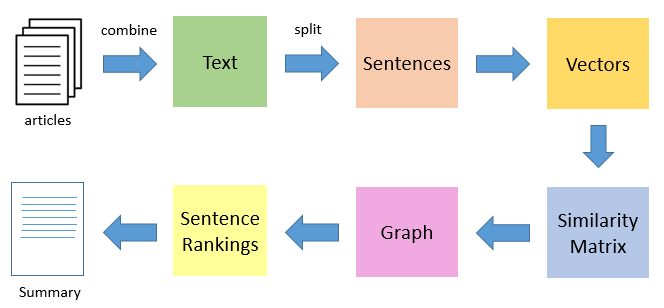
문서에서 co-occurrence를 바탕으로 두 단어간 유사도를 정의하여 단어 그래프를 생성한다. 그다음 단어 그래프를 대표하는 핵심 단어를 선택하여 집합의 키워드를 추출한다
TextRank 단어 그래프 생성
- Vertex 생성
: 주어진 문서를 품사태깅 후 최소 빈도수 이상 등장한 단어 대상으로 명사, 고유명사, 동사, 형용사 등을 vertex로 생성한다. (조사, 어미는 필터링) - Edge 생성
: 두 단어가 co-occurrence관계가 있을 경우 단어간 edge 생성co-occurrence란 정해진 window size내에 단어가 동시 출현했을 때를 의미한다
- vertex의 초기 중요도를 1로 설정하고 수렴할 때 까지 알고리즘을 반복한다
TextRank vertex 중요도
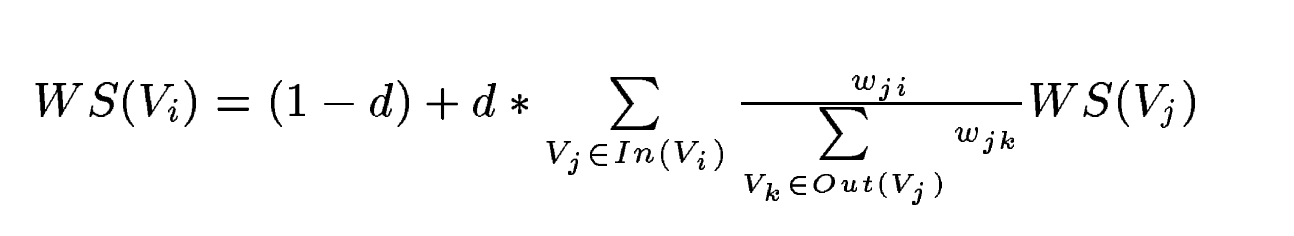
vertex의 중요도를 정렬하여 top n 개의 단어를 선택하여 문서집합을 대표하는 핵심 단어로 선정한다
감성 분석(Semtiment Analysis)
감성 분석이란, 텍스트로 부터 감성 표현(너무 좋다, 별로다, 불편하다 등..)을 추출한다.
-
Aspect-based sentiment analysis
문장에서 감성 표현과 그 표현이 향하는 대상을 알아내는 기법 -
VADER(Valence Aware Dictionary and sEntiment Reasoner): 사전과 규칙 기반의 감성 분석 오픈소스
감성분석 vs 감정분석
감성: 감정 기반의 feeling이나 의견 ex. 국민 정서, 민심, 의견..
감정: strong feeling ex. 사랑, 불안, 화..
