다음의 글을 참고하며 읽었다
https://labcontext.github.io/restoration/partialconv/
Abstract
이제껏 연구된 deep learning based image inpainting 기술들은 standard convolution network를 이용한다. 이는 색감 차이나 blurriness(흐릿함)같은 artifacts를 유발한다. 이를 줄이기 위해 후처리 작업이 주로 사용되지만 expensive & 실패할 가능성이 높다.
따라서 본 논문에서는 전통적 convolution이 아닌 partial convolution을 제안한다. 이는 convolution이 유효한 픽셀에만 적용되도록 제한하는 마스킹을 거치게 하고 재정규화된다. 재정규화된 것이 partial convolution forward pass의 한 부분으로서, 현 레이어에서 다음 레이어로 갈 때 updated mask를 자동으로 생성하게 하는 방법도 함께 제안한다.
1. Introduction
Image inpainting이란 이미지의 holes를 채우는 기술이다. 이전의 deep learning 접근 방식은 이미지의 중심부의 직사각형 영역에 집중했고, expensive post-processing에 의존했다. 이 논문의 목표는 불규칙적인 holes patterns에 작동하고, 추가적인 후처리 없이 이미지의 나머지 부분과 통합되는 예측 모델을 제안하는 것이다.
Deep learning을 사용하지 않는 최근의 image inpainting 접근법은 빈 영역을 채우기 위해 빈 영역을 제외한 이미지의 나머지 부분의 image statistics를 사용했다.
Deep neaural network기반의 Image Inpainting은 semantic priors와 meaningful hidden representations를 end-to-end방식으로 학습한다. 이러한 네트워크는 이미지에 convolution filter를 사용하여 누락된 conent를 fixed value로 채운다. 이러한 접근방식은 초기 hole values에 의존하며, 이는 hole의 texture부족, 색상 대비, aritificial edge와 같은 문제점으로 나타난다.
최근 접근방식의 또다른 한계는 이미지 중심의 직사각형 모양의 구멍에 집중한다는 것이다. 이는 직사각형 구멍에 overfitting된다는 한계가 있다.
본 논문에서는 irregular masks를 다루기 위해서, masked, re-normalized convolution 작업을 수행 한 후 mask-updated 단계를 수행하는 partial convolution layer를 제안한다. Partial convolution의 사용은 binary mask가 주어졌을 때, convolution 결과가 모든 레이어에서 hole이 아닌 region에만 의존하도록 하는 것이다.
요약하자면, 본 논문에서 제안하는 기법은
- Automatic mask update step을 통해 partial convolution 기법을 제안한다.
- convolution layer를 partial convolution 및 mask update로 대체하면 최첨단 인페인팅 결과를 얻을 수 있음을 보여준다.
- 불규칙한 모양의 구멍에서 이미지 인페인팅 모델을 훈련하는 것의 효과를 입증했다.
2. Related Work
- Non-learning Based model
- 이웃한 픽셀을 이용해 채워넣는 기법
- 구멍이 작은 경우만 가능
- texture의 variance가 작아야 가능
- Computing cost가 매우 커서 실시간 처리가 어렵다
- Deep learning Based model
- 일정한 placeholder값을 가지고 hole의 값을 초기화하는 것이 일반적이다
- 논문에서는 context encoder와 Semantic Image Inpainting with Deep Generative model을 소개
3. Approach
본 논문에서 제안하는 모델은 이미지 인페인팅을 위해 stacked partial convolution operation과 mask updating step을 사용한다.
3.1 Partial Convolution Layer
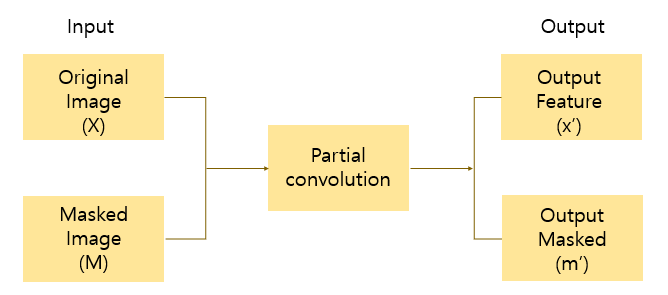
W : convolution filter의 가중치
b : bias
X : feature value(pixels values)
M : binary mask(input으로 들어오는 mask, 즉 우리가 만드는 hole)
라고 했을 때, 모든 위치에서 partial convolution은 아래와 같이 표현된다.
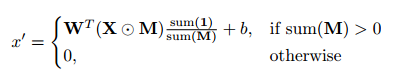
⊙는 element-wise multiplication이고, 1은 M과 같은 모양이지만 모든 elements가 1이다.
위의 식에서 output values는 unmasked inputs에만 의존한다.
sum(1)/sum(M)부분은 적절한 스케일링을 적용하여 다양한 양의 유효한(unmasked) 입력에 맞게 조정한다. 마스크가 쓰이지 않은 부분의 픽셀에 곱해서 픽셀 값의 normalize를 담당한다.
각각의 partial convolution operation 후에, 아래와같이 mask를 업데이트한다.
컨볼루션이 적어도 하나의 유효한 입력 값에 대한 출력에 영향을 미칠 수 있다면, 그 위치를 유효하다고 표시한다.

이 그림에서 흰 부분이 non-hole(1)이고, 검은 부분이 hole(0)이다.
slide하면서 convolution을 진행할 때, non-hole인 부분이 조금이라도 있다면 위의 연산을 진행한다. 즉, 이미지와 마스크가 동시에 들어올 때 convolution에 모두 마스크만 있다면 아무것도 하지 않고 pass

위 연산을 반복함에 따라 hole인 부분이 연산의 output으로 채워지기 때문에 hole이 점점 채워진다.
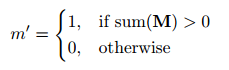
부분 컨볼루션 레이어의 연속적인 적용으로, hole이 아닌 부분이 하나라도 포함되어있다면 채워진다.
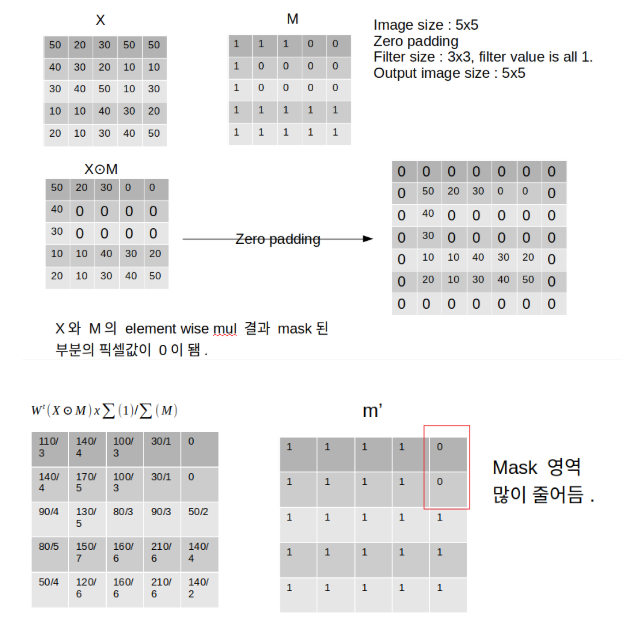
왼쪽은 각 3*3 filter별로 x' output을 내는 식을 적용한결과다.
오른쪽은 sum(M)이 있으면 1, 0이면 0이다. 기존 M에 비해 Mask 영역이 많이 줄어든 것을 확인할 수 있다.
3.2 Network Architecture and Implementation
Binary mask의 사이즈는 image의 피쳐 사이즈(CHW)와 동일하고, 고정된 conv layer를 통해 동일한 kernel 사이즈의 Pconv를 구현한다. Network의 경우 U-net 과 비슷한 구조다. 모든 conv layer를 Pconv layer로 바꾸고 decoding stage에서 nearest neighbor up-sampling을 사용했다.
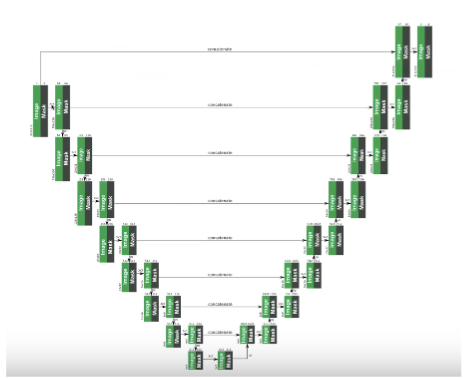
- 3Channel의 마스크와 이미지로 구성되어있다
- 좌우:partial conv 상하:batch norm
- 마지막 Decoder 단계에 input image를 concat하는데, 이 과정은 input이미지의 정보를 output이미지에 전달하는 과정이다.
- 마지막 Pconv layer의 입력은 원본 입력 이미지와 holes 및 원본 마스크의 연결을 포함하므로 모델이 구멍이 아닌 픽셀을 복사할 수 있다.
- 이미지 경계에서 일반적인 패딩 대신 적절한 마스킹이 있는 Pconv를 사용한다. 이미지 밖의 픽셀이 또 다른 hole로 인식되지 않게 주의해야함
3.3 Loss Functions
Loss 함수는 pixel단위의 복원 정확도와 주변영역과 hole이 자연스럽게 이어지는지에 대한 평가다. Total Loss는 아래 Loss들의 조합이다.
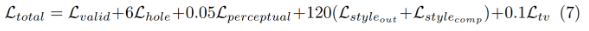
- lin:input image with hole
- lout = output feature(image), network prediction(output) 즉 모델의 결과
- M:initial binary mask
- lgt:Ground truth image
- lcomp:lout but with the non-hole pixels directly set to ground truth
- 𝛹:activation map of the nth selected layer
아래의 총 6개의 Loss를 조합했다
-
L valid:non hole loss(non-hole인 부분에 대한 loss 계산)
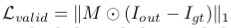
손상되지 않은 부분에 대한 loss값 -
L hole:hole loss(hole인 부분에 대한 loss 계산)
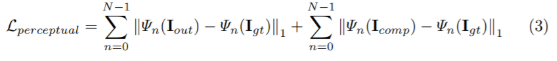
손상된 부분을 얼마나 잘 복원했는지에 대한 loss -
L perceptual
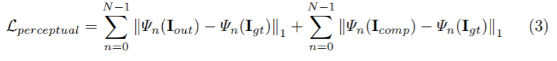
- I out:모델을 통한 결과 이미지
- I comp:I out에서 non-hole부분을 원래 input pixel값으로 바꾼 것
두 픽셀간의 절대값의 차이를 줄이는 방향으로 학습
- L style out
- L style comp
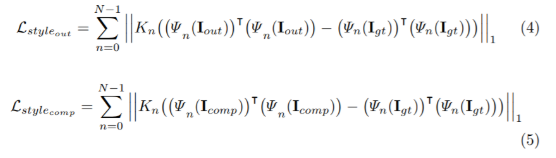
- Kn:normalization factor for the nth selected layer
모델이 만들어낸 이미지를 학습된 vgg모델에 적용시켜 만들어낸 이미지의 style을 ground truth이미지를 vgg모델에 적용시켜 만들어낸 이미지와의 차이를 줄이는 것을 학습한다.
- L tv:경계면의 차이를 줄이도록 학습하는 loss
hole인 부분에서 가장 인접해있는 경계만 본다.
P:hole인 부분에서 non-hole과 붙어있는 경계
4. Experiments
4.1 Irregular Mask Dataset
- mask도 종류가 있다. 구멍이 경계선과 멀리 떨어져있는 것, 가까이 같이 뚫려있는 것
4.2 Training Process
- batch size 6, V100 Single, imagenet classification initializer 사용
- Batch normalization Issue : 배치마다 전체 픽셀에 대해 평균/분산을 맞춰주는데, holes가 이 부분에 혼란을 가져오기 때문에 무시. hole들이 점점 채워지기 때문에 괜찮다.
5. Discussion & Extension
5.1 Discussion
본 논문에서 제안한 Pconv layer는 자동으로 mask를 업데이트하고, state-of-the-art image inpainting 결과를 생성한다. 이 모델은 마스크의 모양, 위치, 경계로부터의 거리와 상관 없이 holes를 다룰 수 있다.
한계는 큰 사이즈의 구멍이나, 문에있는 손잡이와 같이 드문드문 구조화된 이미지에서 나타난다.
5.2 Extension to Image Super Resolution
Offsetting pixels, inserting holes를 통해 SR에도 이 기법을 확장할 수 있다.
