목표
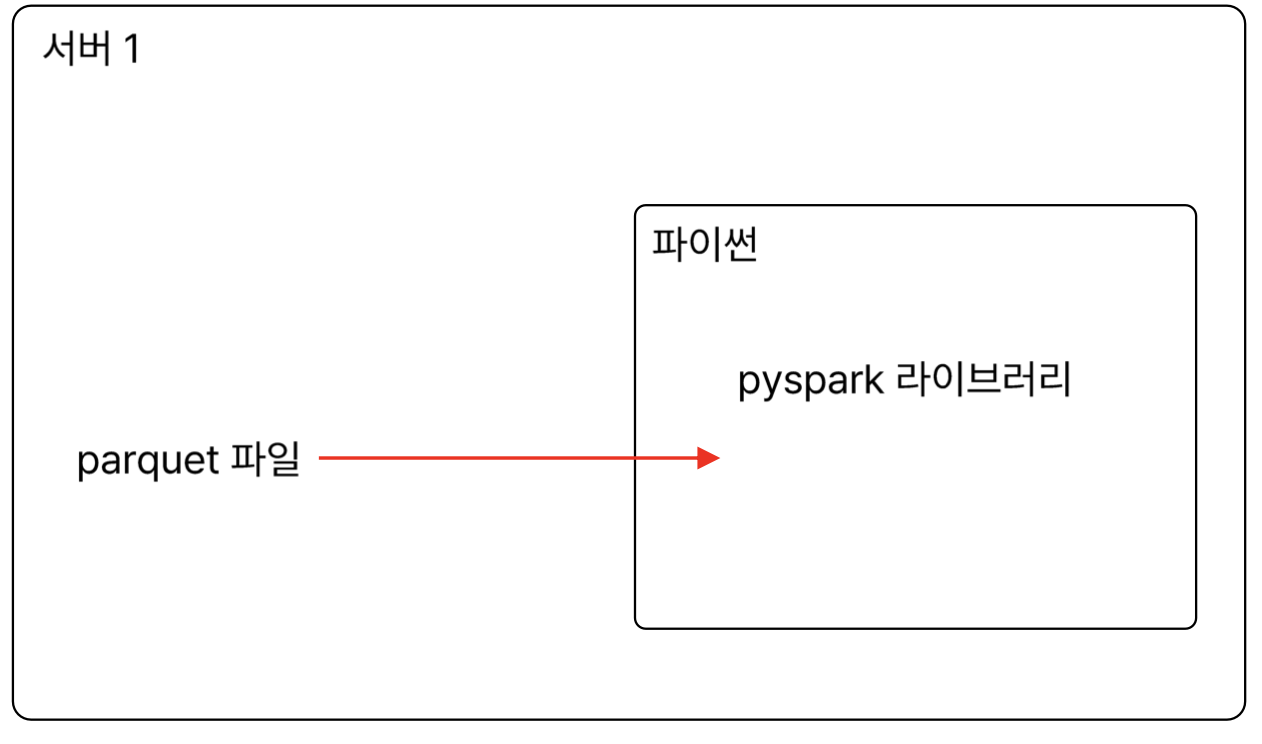
환경설정
1) EC2 서버 생성
- 이름 : 내이름01
- ubuntu
- t2.xlarge
- 100GB
2) 기본세팅
sudo apt-get update
sudo apt-get install net-tools3) 가상환경 세팅
sudo apt install make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \
libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev
curl https://pyenv.run | bash
vi ~/.bashrc
# 아래 붙여넣기
export PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
# shell 재시작
exec $SHELL
# python 다운로드
pyenv install 3.11.9
# 가상환경 생성
pyenv virtualenv 3.11.9 py3_11_94) 필요한 라이브러리 설치
pip install numpy pandas pyarrow scikit-learn flask gunicorn psycopg2-binary
python -m pip install --upgrade pip
5) 자바 설치
- 17 버전 설치
sudo apt install openjdk-17-jre-headless
java -version
vi ~/.bashrc
# 아래 추가
export JAVA_HOME=/usr/lib/jvm/java-1.17.0-openjdk-amd64
source .bashrc
exec $SHELLpyspark
- 폴더 만들기
mkdir work
mkdir spark파일 읽기 및 쓰기
- parquet 파일 만들기 (pandas 이용)
import pandas as pd
url = 'https://raw.githubusercontent.com/losskatsu/data-example/main/data/iris.csv'
df = pd.read_csv(url)
df.to_parquet('/home/ubuntu/work/spark/iris.parquet' , index = False)
df.to_csv('/home/ubuntu/work/spark/iris.csv', index = False)- pyspark 활용
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("CSVReader").getOrCreate()
df = spark.read.option("header", "true").csv("/home/ubuntu/work/spark/iris.csv")
df.show(5)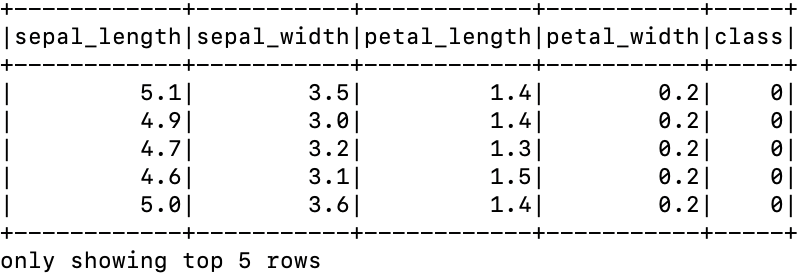
- parquet 파일 읽기
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ParquetReader").getOrCreate()
df = spark.read.parquet("/home/ubuntu/work/spark/iris.parquet")
df.show(7)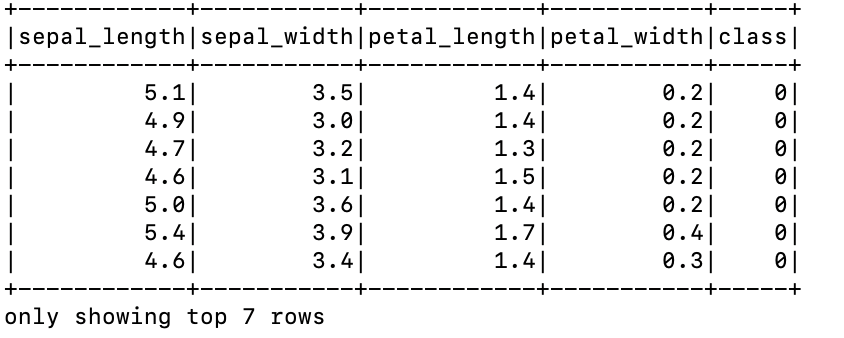
DataFrame으로 활용하기
df 확인하기
# 스키마
df.printSchema()
#type
type(df)| Schema | type |
|---|---|
 |  |
기초 df 확인
# data 수
df.count()
# 열 이름 확인하기
df.columns
# 특정 행 출력하기
## 3번째 row
df.collect()[3]
## 3~6 row 출력
df.collect()[3:6]
# 특정 열 출력
## 방법1
df.select("sepal_length", 'petal_length').show(3)
## 방법2 - 변수 활용
col01 = df.select("sepal_length", 'petal_length')
col01.show(5)
# 기초 통계 보기
df.decribe().show()
# filter 기능
df.filter("sepal_length >7").show(3)
df.filter("sepal_length>7").count()
# 혼합해서 사용하기
df.filter("sepal_length >7 ").select('sepal_length').show(3)
| decribe | filter |
|---|---|
 |  |
평균 : 데이터의 위치 (location parameter)
표준편차 : 데이터의 흩어짐 정도 ( scale parameter)
다양한 함수
- spark의 aggregate
from pyspark.sql.functions import avg
# group by
## group 으로 묶어서 평균보기
df.groupby("class").agg(avg("sepal_length")).show()
# 정렬
## ascending = True : 오름차순 / False : 내림차순
df.orderBy("petal_length", ascending = True).show(5)| group by | order by |
|---|---|
 | 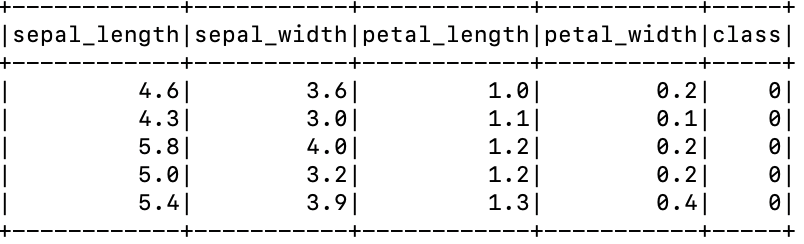 |

신윤재입니다