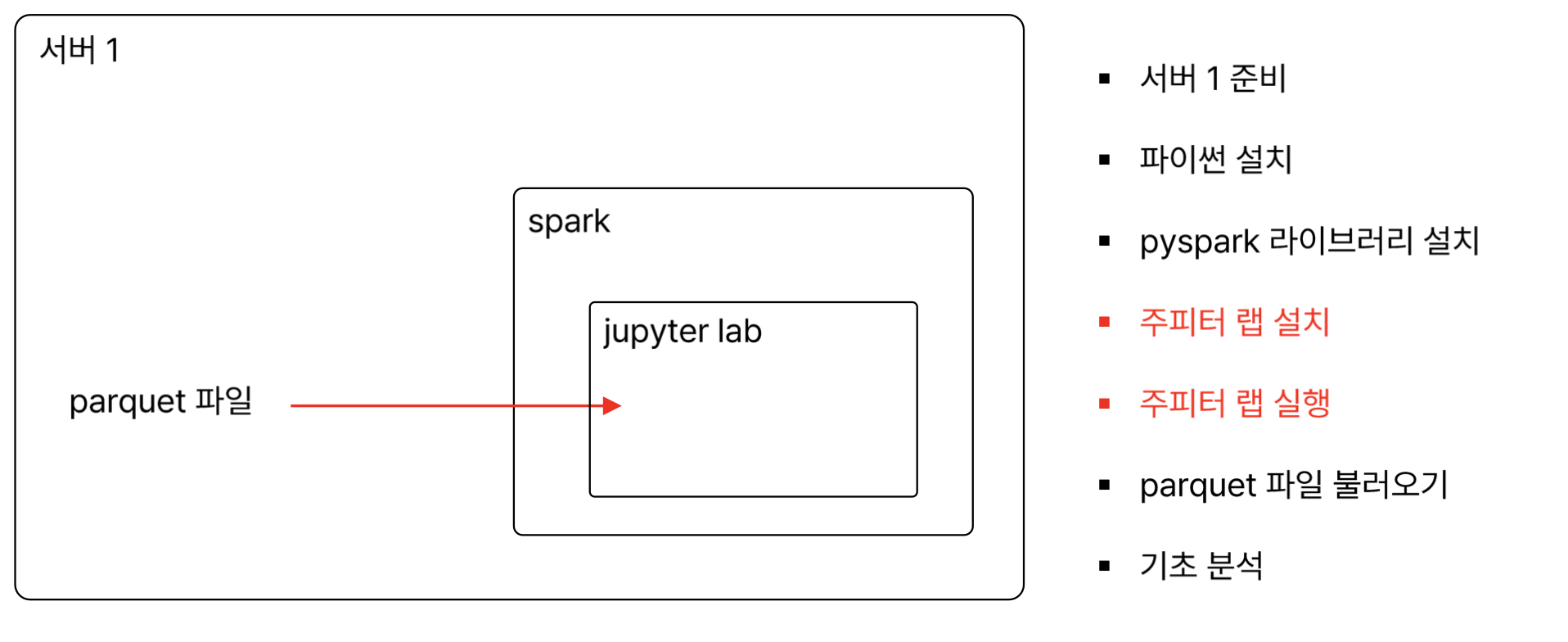
앞선 실습에서 iris.csv, iris.parquet 두개의 데이터를 data 폴더에 넣어주기 (경로 설정을 위해서 동일하게 맞춰줌)
spark 설치하기
-
설치를 위한 app 폴더 생성

-
app/spark에서 spark 다운로드
wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz- 압축 풀기
tar -zxvf spark-3.5.1-bin-hadoop3.tgz - 설정 추가
vi ~/.bashrc
---
# 맨 아래에 추가
export SPARK_HOME=/home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/home/ubuntu/.pyenv/versions/py3_11_9/bin/python
---디렉토리 살펴보기

- bin : 스파크와 상호작용할 수 있는 스크립트로 구성
- pyspark : 우리가 사용할 것
- spark-shell : 스칼라로 실행
- sparkR : R로 실행
- kubernetes : 쿠버네티스 클러스터에서 쓰는 스파크를 위한 도커 이미지 제작을 위한 Dockerfile 포함
- python : pyspark와 관련된 파이썬 파일 및 라이브러리 포함 ( 스파크를 실행할 때는 로컬에 설치된 파이썬 사용)
- sbin : 스파크 컴포넌트 시작 및 중지, 관리
spark 실행
/home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3/bin/pyspark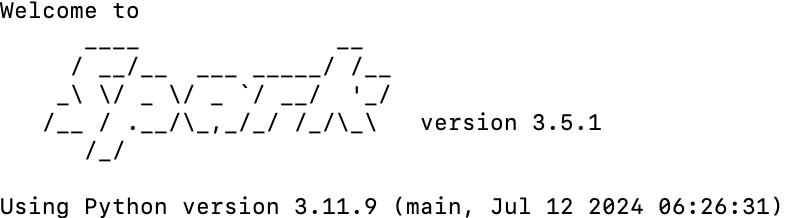
- 여기서 명령어 실행시켜보기
- 따로 import 해줄 필요가 없음.
>>> df = spark.read.parquet("/home/ubuntu/work/spark01/data/iris.parquet")
>>> df.show(3)-
ui 로 확인해보기
- 기본적으로 4040 포트를 사용하므로 보안그룹에서 열어줘야함.
- 이후 public_IP:4040 으로 들어가면 UI 확인 가능
주피터 랩 이용
- 설정
mkdir ~/work/jupyter
cd ~/work/jupyter
# 가상환경활성화
pyenv activate py3_11_9
# jupyter lab 다운로드
pip install jupyterlab
- 주피터 랩 설정
# 설정파일 생성
jupyter lab --generate-config
# 설정파일 확인
ls ~/.jupyter
# 설정파일 변경 (아래 사항들 추가해주기)
vi ~/.jupyter/jupyter_lab_config.py
---
# 모든 ip를 받겠다
c.NotebookApp.ip = '0.0.0.0'
# 기본적으로 뜨는 웹 브라우저를 띄우지 않겠다.
c.NotebookApp.open_browser = False
# 8888 port를 사용하겠다
c.NotebookApp.port = 8888
# token설정 (안하고 싶으면 ''으로 )
c.NotebookApp.token = '나의 토큰'
# 비밀번호 설정해주기
c.NotebookApp.password = '나의 비밀번호'
# home dir 설정해주기
c.ServerApp.root_dir = '/home/ubuntu/work/jupyter'
---- 환경설정
vi ~/.bashrc
---
# jupyter lab 설정 추가
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="lab"
---
source ~/.bashrc
exec $SHELL
- 주피터 랩이랑 스파크 연동
- findspark : PySpark를 사용할 때 , python 환경에서 spark 연동하기 쉽게 제공해주는 라이브러리
pyenv activate py3_11_9
pip install findspark-
주피터 노트북을 위한 포트 열기 : 보안그룹 8888 열어주기
-
실행시키기
jupyter lab
- Public_ip:8888로 들어가보기

신윤재입니다