DB - spark
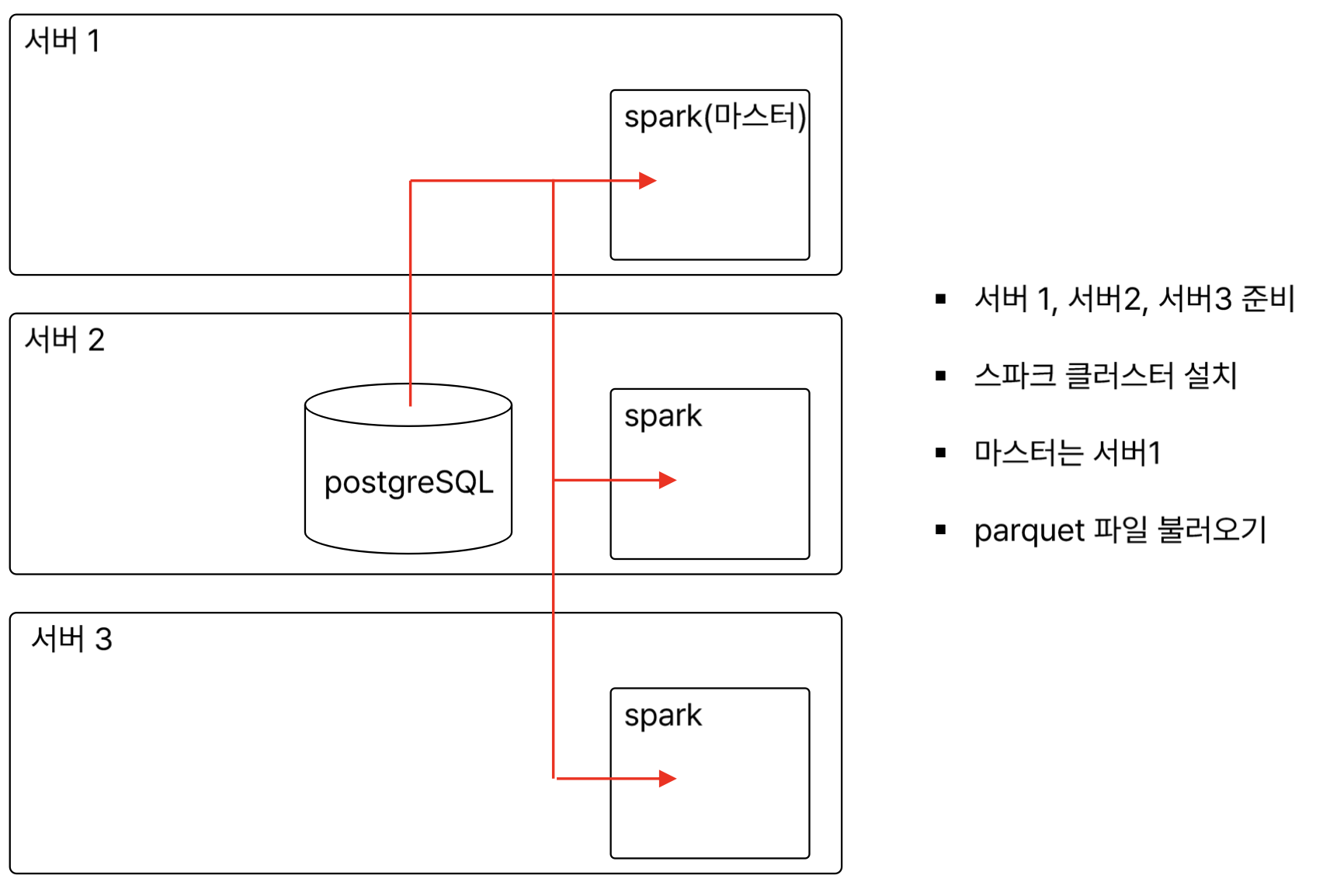
1) spark 가동
- master1 서버에서 start-all.sh 해주기
PostgresSQL
1) server2에 설치
sudo apt install curl ca-certificates
sudo install -d /usr/share/postgresql-common/pgdg
sudo install -d /usr/share/postgresql-common/pgdg
sudo curl -o /usr/share/postgresql-common/pgdg/apt.postgresql.org.asc --fail https://www.postgresql.org/media/keys/ACCC4CF8.asc
sudo sh -c 'echo "deb [signed-by=/usr/share/postgresql-common/pgdg/apt.postgresql.org.asc] https://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
sudo apt -y install postgresql
# 확인
sudo systemctl status postgresql.service2) postgresql 설정
sudo -i -u postgres
psql
\list
# 비밀번호 변경
ALTER USER postgres WITH PASSWORD 'postgres';
3) DB, table 생성
- login log를 담을 DB
CREATE DATABASE login_db;
- table 생성
CREATE TABLE userlogin_20240527(
SEQ SERIAL PRIMARY KEY,
USERID VARCHAR(20) NOT NULL,
USERNAME VARCHAR(20) NOT NULL,
EMAIL VARCHAR(100) NOT NULL,
LOGIN_RESULT SMALLINT NOT NULL,
LOGIN_DT TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);- insert
INSERT INTO userlogin_20240527(USERID, USERNAME, EMAIL, LOGIN_RESULT) VALUES
('A0012', 'qwer', 'qwer@qwer.com', 1),
('A0017', 'asdf', 'asdf@asdf.com', 0);4) 빠져나오기
\q
exit5) 접속 허용
- 설정 파일 확인
cd /etc/postgresql/16/main/
sudo vim postgresql.conf
# 아래사항 변경 - 모든걸 듣겠다.
---
listen_addresses = '0.0.0.0'
---
sudo vim pg_hba.conf
# 아래사항 추가
---
host all all 0.0.0.0/0 scram-sha-256
---- postgresql 재시작
sudo systemctl restart postgresql
sudo systemctl status postgresql
netstat -nap | grep 54326) 보안그룹
- 5432 port 열어주기
JDBC
JDBC : Java Database Connectivity
- 자바 프로그래밍 언어에서 다양한 데이터 베이스 가능하게 해주는 표준 API
- 자바 SE(Standard Edition)의 일부
- 자바 설치시, JDBC도 함께 제공됨
- 특정 데이터 베이스의 JDBC 드라이버는 포함되어 있지 않음.
- 각 데이터베이스들은 자신의 데이터베이스에 접속할수 있는 JDBC 드라이버를 별도 제공
- 따라서 , PostgreSQL과 Spark를 연동하려면 PosrgrSQL에서 제공하는 JDBC드라이버 다운 후,
- Spark 세션을 생성할 때 해당 드라이버 JAR 파일의 경로 설정 필요
- 기능 : 데이터베이스 연결, SQL쿼리 실행/결과 처리, 트랜잭션 관리
1) 다운로드
JDBC 다운로드 사이트
- JAVA 8 다운로드 버튼의 우클릭, 링크주소 복사
- wget 이용
- server 1,2,3모두 받음
cd ~/app
wget https://jdbc.postgresql.org/download/postgresql-42.7.3.jarspark, postgresql 연결
1) 주피터랩 실행
jupeter lab2) 주피터랩 창 열기
3) 코드
from pyspark.sql import SparkSession
spark = SparkSession.builder.config("spark.driver.extraClassPath", "/home/ubuntu/app/postgresql-42.7.3.jar")\
.appName("Read PostgreSQL Table")\
.getOrCreate()
ip = "server2의 내부 ip"
port = "5432"
user = "postgres"
pw = "postgres"
db = "login_db"
table = "userlogin_20240527"
df = spark.read.format('jdbc').option("url", f"jdbc:postgresql://{ip}:{port}/{db}").option("driver","org.postgresql.Driver").option("dbtable" , table).option("user", user).option("password", pw).load()
df.show()

DB - parquet - spark

- 서버간 파일 전송도 함께 실습
사전 설정
1) 라이브러리 설치
- server2
pyenv activate py3_11_9
pip install pyarrow
pip install pandas
pip install psycopg2-binaryparquet 파일 생성
- server 2에서

1) 폴더 생성
cd ~/work
mkdir pyscript
cd pyscript
mkdir data2) 스크립트 생성
vi psql12pqt.pyimport psycopg2
import pandas as pd
host = '127.0.0.1'
port = 5432
user = 'postgres'
pw = 'postgres'
db = 'login_db'
table = 'userlogin_20240527'
sqlquery = 'SELECT * FROM {}'.format(table)
save_path = './data/'
file_name = table + '.parquet'
conn = psycopg2.connect (host = host,
port = port,
dbname = db,
user = user,
password = pw)
cur = conn.cursor()
cur.execute(sqlquery)
# column name
colnames = [element[0] for element in cur.description]
print(cur.description)
# dataframe
data = cur.fetchall()
df = pd.DataFrame(data, columns = colnames)
cur.close()
conn.close()
df.to_parquet(path = save_path + file_name)3) 결과 확인
-
print 결과

-
파일 생성 결과: parquet 파일 생성
4) parquet 파일 확인
- 잘 출력되어야함.
python
import pandas as pd
df = pd.read_parquet('/home/ubuntu/work/pyscript/data/userlogin_20240527.parquet')
df.head(4)파일 전달
- scp 이용
- server2 -> server1
scp 보낼파일경로 ubuntu@프라이빗ip:넣을파일경로
scp ./userlogin_20240527.parquet ubuntu@server1_ip:/home/ubuntu/work/spark01/data파일 생성, 전달을 sh로 만들기
1) 폴더 생성
mkdir ~/work/bashscript
cd ~/work/bashscript2) 스크립트 생성
vi pqt2server01.sh
---
#!/bin/bash
destination_server="ubuntu@172.31.6.231"
source_path="/home/ubuntu/work/pyscript/data/userlogin_20240527.parquet"
destination_path="/home/ubuntu/work/spark01/data"
scp "$source_path" "$destination_server:$destination_path"
# result
if [ $? -eq 0 ]; then
echo "success"
else
echo "fail"
fi
---3) 실행 권한 및 실행
chmod 777 pqt2server01.sh
./pqt2server01.sh크론탭으로 실행해보기
crontab -e
---
# 매일 8시에 실행
* 8 * * * /home/ubuntu/work/bashscript/pqt2server01.sh 2>&1
---
### spark 실행 후 파일 불러오기
python 실행 후 해보기
```python
from pyspark.sql import SparkSession
import pyarrow.parquet as pq
spark = SparkSession.builder.appName("parquet reader").getOrCreate()
table = pq.read_table("/home/ubuntu/work/spark01/data/userlogin_20240527.parquet")
pandas_df = table.to_pandas()
df = spark.createDataFrame(pandas_df)
df.show()
# pyarrow 말고 spark로 parquet 파일 바로 읽기
df2 = spark.read.parquet("/home/ubuntu/work/spark/userlogin_20240527.parquet")
- pyarrow로 parquet 파일을 읽어오기
- 읽어온 파일을 pandas Dataframe으로 변경하기
- spark dataframe으로 변경해서 읽기
- 혹은 바로 spark를 통해 dataframe 으로 만들기

신윤재입니다