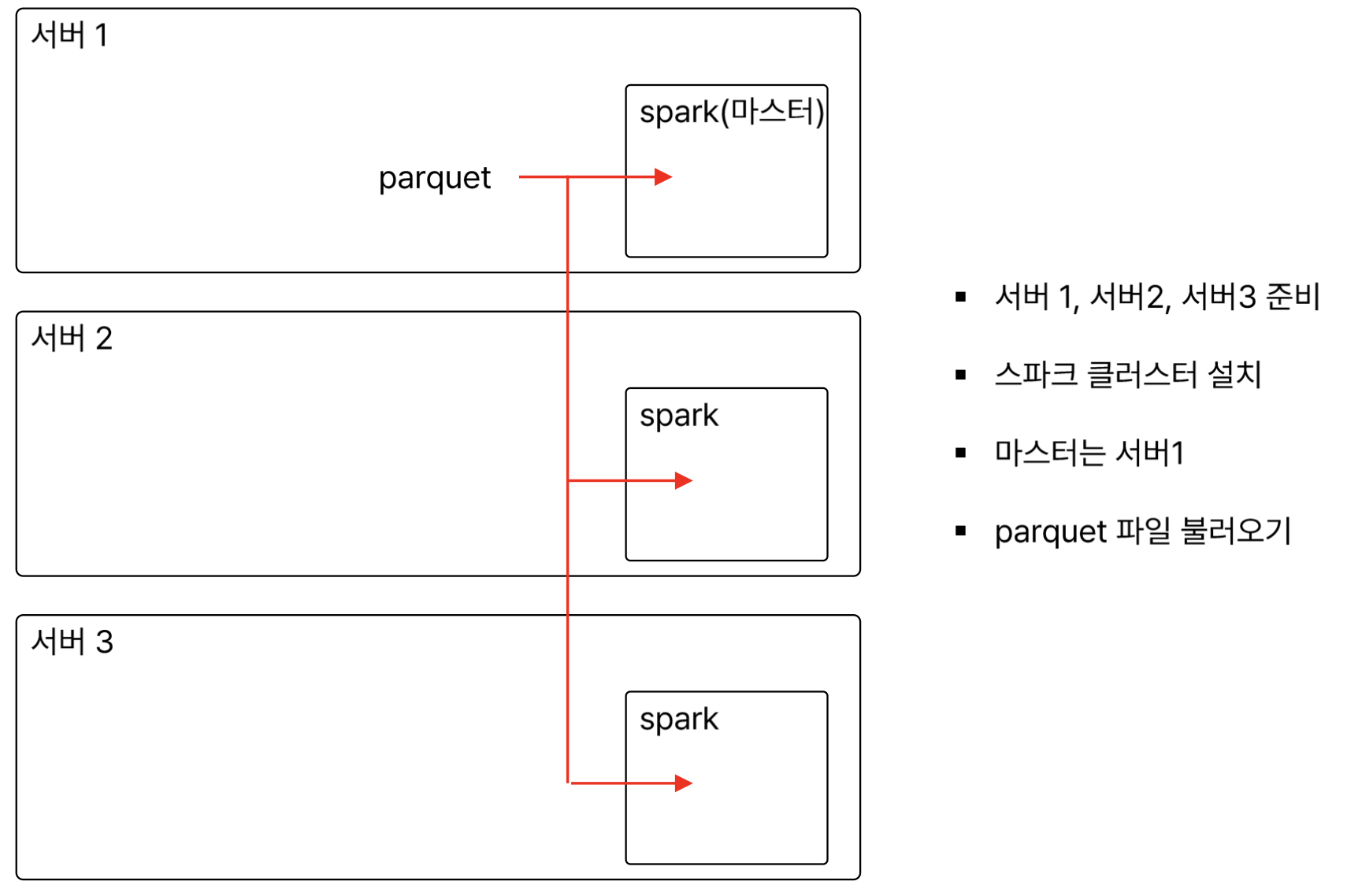
서버 생성
1) ec2 서버 2개 더 생성
- 3개 모두 동일한 보안그룹으로 해야함.
2) ec2 서버간, 연동이 가능하도록 설정
- 인바운드 규칙에서 보안그룹으로 트래픽 열어주기
- 모든 트래픽 -> 보안그룹 (sg로 시작하는 보안그룹 넣어주기)
서버 확인
1) net-tools 다운
sudo apt update
sudo apt install net-tools2) IP 주소 확인
- inet 확인하기 ( 내부 ip)
ifconfig3) 파일 수정
- etc/hosts 파일 수정
- 서로의 서버를 들어갈 수 있도록 함.
sudo vi /etc/hosts
---
server1_private_ip server1
server2_private_ip server2
server3_private_ip server3
---4) 인증키 생성
- RSA 알고리즘을 사용해 SSH 키 쌍을 생성하는 명령어
- 명령어 입력 후에는 해당 경로에 다음과 같은 두개의 파일이 생성됨
- id_rsa : 개인키(private key) 파일
- id_rsa.pub : 공개키 (public key) 파일
# 3개 서버에서 모두 실행
## 그냥 enter 3번쳐주면 됨.
ssh-keygen -t rsa
5) 인증키 넣어주기
- 각 서버에 ~/.ssh/authorized_keys에 각각의 .pub키를 복사 붙여넣기 해주기
- 1,2,3 서버의 모든 .pub키를 복사 해서 다 넣어주기
sudo vi ~/.ssh/authorized_keys 6) 확인
- 각 서버에서 ssh server1 이런식으로 각 server에 접속이 가능한지 확인해보기
7) 새로운 서버 세팅
# 자바
sudo apt install openjdk-17-jre-headless
vim .bashrc
# 맨 아래 추가
export JAVA_HOME=/usr/lib/jvm/java-1.17.0-openjdk-amd64
# 가상환경
sudo apt-get update; sudo apt-get install make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \
libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev
curl https://pyenv.run | bash
vim .bashrc
# 가장 아래에 추가
export PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
source .bashrc
exec $SHELL
# 가상환경생성
pyenv install 3.11.9
pyenv virtualenv 3.11.9 py3_11_9
pyenv versions
# 각종 폴더 생성
mkdir app work
cd app
mkdir spark
# 스파크 다운로드
cd ~/app/spark
wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
tar -zxvf spark-3.5.1-bin-hadoop3.tgz
# 스파크 설정
vim ~/.bashrc
export SPARK_HOME=/home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/home/ubuntu/.pyenv/versions/py3_11_9/bin/python
# 확인
pysparkcluster 구성
1) 마스터 설정
cd /home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
---
SPARK_MASTER_HOST='server1의 내부 아이피'
---
cp workers.template workers
vi workers
---
#localhost
server1내부아이피
server2내부아이피
---
2) 워커 설정
cd app/spark/spark-3.5.1-bin-hadoop3/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
---
SPARK_MASTER_HOST='server1의 내부 아이피'
---3) 실행
- 마스터 1 서버에서 실행
cd /home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3/sbin
./start-all.sh 4) 확인하기
- 보안그룹 8080 열어주기
- 구글에 서버1퍼블릭ip:8080 하면 화면이 뜸(아래 사진과 같은 웹화면)

주피터 설정
- 설정
pyenv activate py3_11_9
jupyter kernelspec list
pyenv deactivate
# 주피터 디렉토리 생성
cd /home/ubuntu/.pyenv/versions/3.11.9/envs/py3_11_9/share/jupyter/kernels/
ls
mkdir py3spark
cd py3spark
vi kernel.json
---
{
"argv": [
"python",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "py3spark",
"language": "python",
"env": {
"SPARK_HOME":
"/home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3",
"PYSPARK_PYTHON":
"/home/ubuntu/.pyenv/versions/py3_11_9/bin/python",
"PYTHONPATH":
"/home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3/python:/home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3/python/lib/py4j-0.10.9.7-src.zip"
}
}
---
# 주피터 실행
pyenv activate py3_11_9
jupyter lab- 실행 후 화면

- 잘 되는지 확인해보기 : 새 파일 만들어서
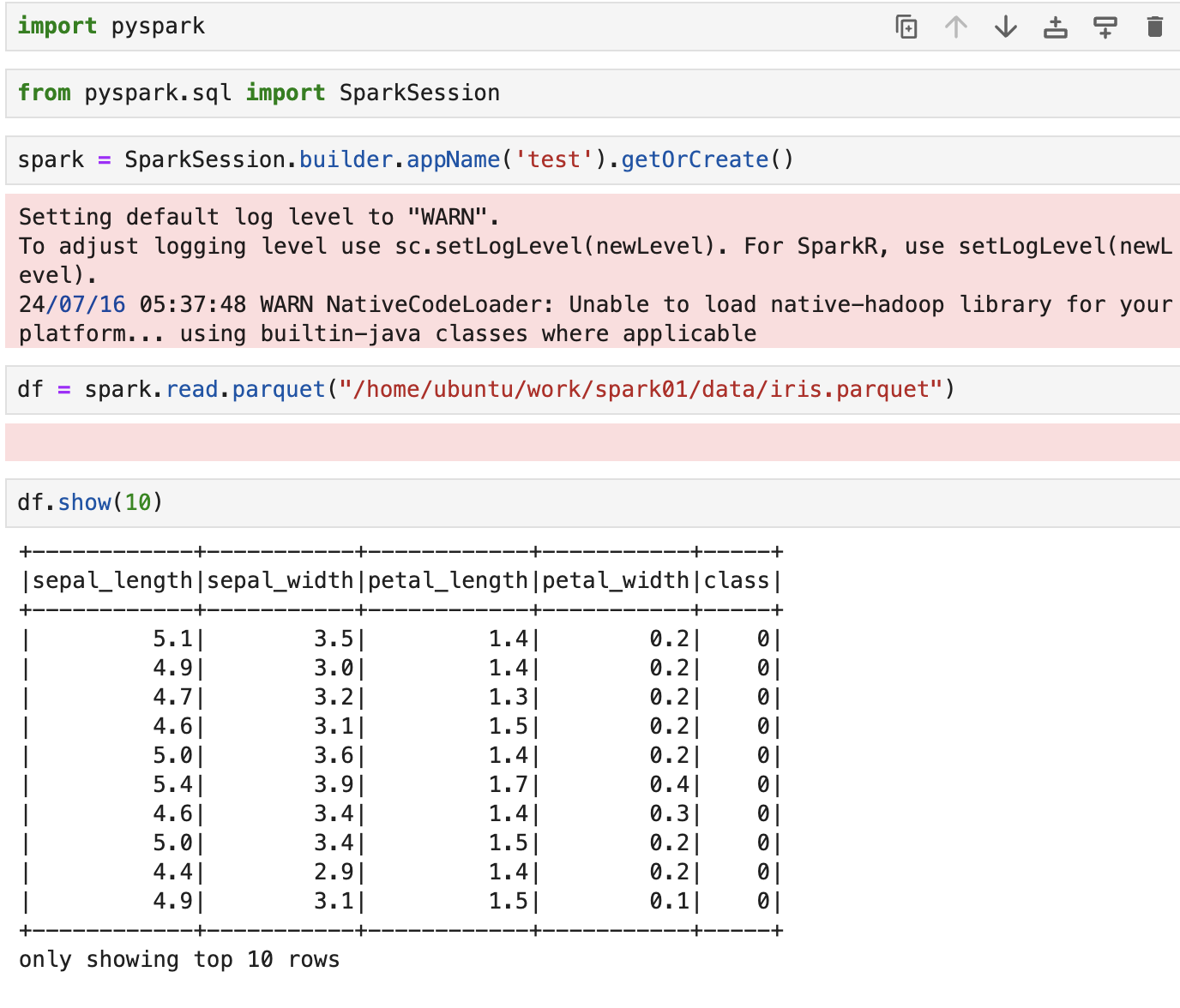
pyspark 연습
- 데이터 필터링
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('test').getOrCreate()
# 데이터 불러오기
df = spark.read.parquet("/home/ubuntu/work/spark01/data/iris.parquet")
#원하는 열만 선택하기
df.select("sepal_length").show(5)
# 조건으로 필터링하기 (2가지 방법)
df.filter(df['sepal_length']>6).show()
df.where(df["class"] ==2).show()
- 데이터 추가 및 변환
from pyspark.sql.functions import col
df = df.withColumn("sepal_length_cm", col("sepal_length") * 10)
df.show(5)
- when 활용
from pyspark.sql.functions import when
df_col = df.withColumn(
"class_string",
when(df['class']==0, "Setosa")
.when(df['class']==1, "Versicolour")
.when(df['class']==2, "Virginica")
)
df_col.show(10)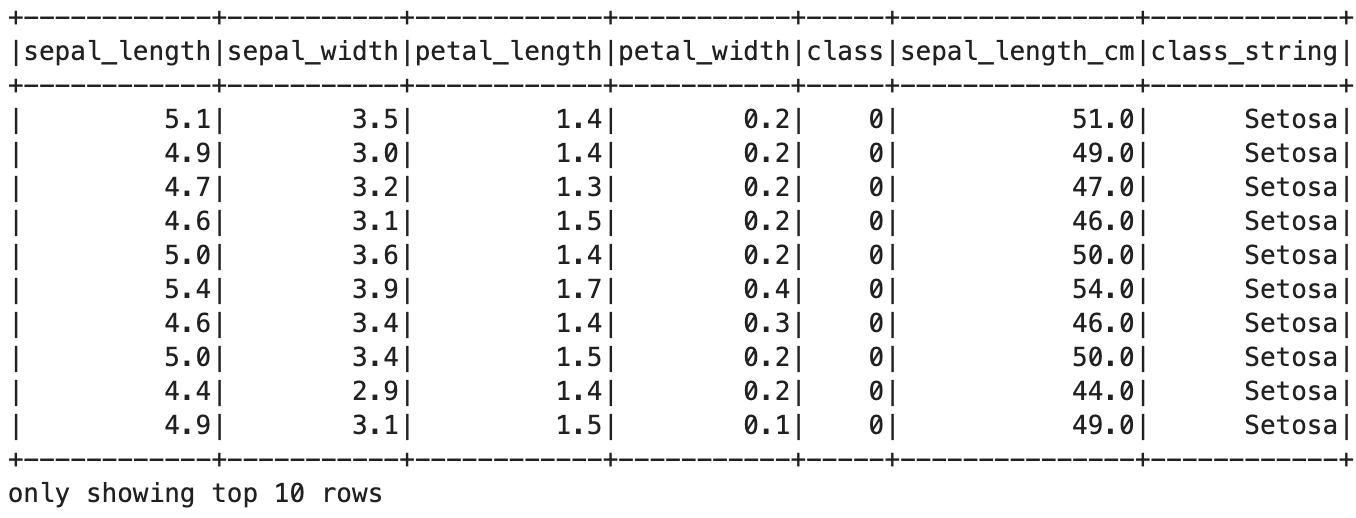
- 문자열 파싱
from pyspark.sql.functions import substring
df_sub = df_col.withColumn("class_string3", substring(df_col['class_string'], 1,3))
df_sub.show(5)
- 그룹별 집계
df.groupby('class').agg({'sepal_length': 'avg', 'sepal_width':'avg'}).show()
- 시각화
import matplotlib.pyplot as plt
pandas_df = df_sub.toPandas()
pandas_df.hist(bins=50, figsize=(20,15))
plt.show()RDD Spark
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
test_sql = spark.range(10).rdd
test_sql.collect()-
df 로 변경하기
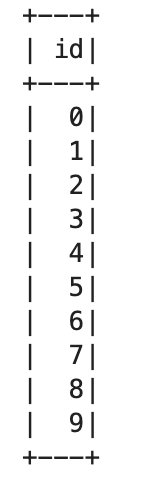
test_df = spark.range(10).rdd.toDF() test_df.show()rdd df 
-
parauet to rdd
df = spark.read.parquet("/home/ubuntu/work/spark01/data/iris.parquet")
df.show(10)
df_rdd = df.rdd
df_rdd.take(10)
- rdd filter
class_rdd = df_rdd.map(lambda row : row['class'])
class_rdd.distinct()
class_rdd.distinct().collect()
class_rdd.distinct().count()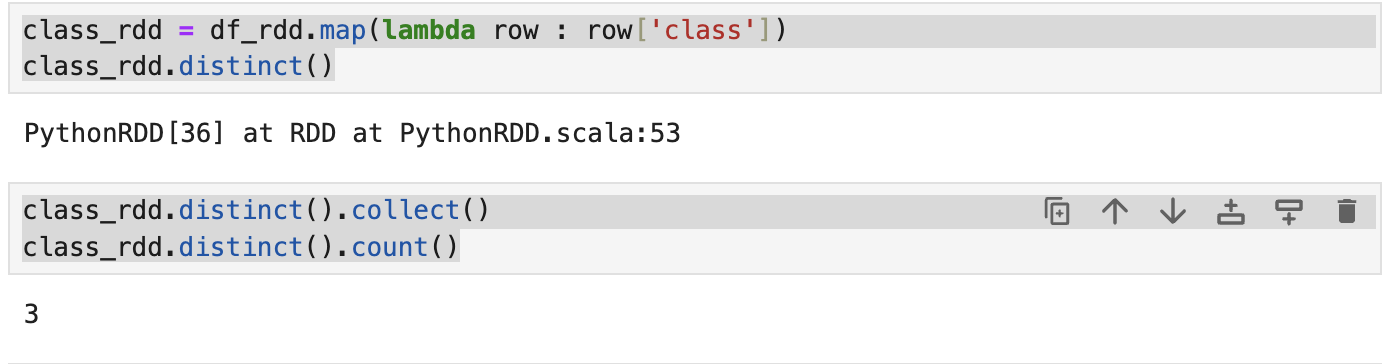

신윤재입니다