'슬라이싱'을 이용하면 데이터 전처리, 데이터 셋 나눌 때 유용하게 쓰인다.
'슬라이싱'의 특징은 다음과 같다.
1. '슬라이싱' 구문의 기본 형태는 리스트[시작:끝]이다.
여기서 시작 인덱스에 있는 원소는 슬라이스에 포함되지만, 끝 인덱스에 있는 원소는 포함되지 않는다.
2. 리스트의 맨 앞부터 슬라이싱 할 때는 0을 입력하지 않아도 된다.
a[:5] == a[0:5] 3. 리스트의 맨 끝까지 슬라이싱 할 때도 인덱스를 적을 필요 없다.
a[5:] == a[5:len(a)]4. 리스트의 끝에서부터 원소를 찾고 싶을 땐 음수 인덱스를 사용한다.
a[:] # ['1','2,'3','4','5','6','7','8','9','10']
a[:-1] # ['1','2,'3','4','5','6','7','8','9']
a[-3:] # ['8','9','10']
a[2:-1] # [3','4','5','6','7','8','9']
**a[-0:] == a[:] #['1','2,'3','4','5','6','7','8','9','10']*** a[-n:]은 n이 0보다 큰 경우 잘 작동하지만, n이 0이면 a[:] 같기 때문에 원래의 리스트를 복사한 리스트를 얻는다.
5. 리스트를 슬라이싱한 결과는 새로운 리스트, 기존 리스트는 변경되지 않는다.

[적용]
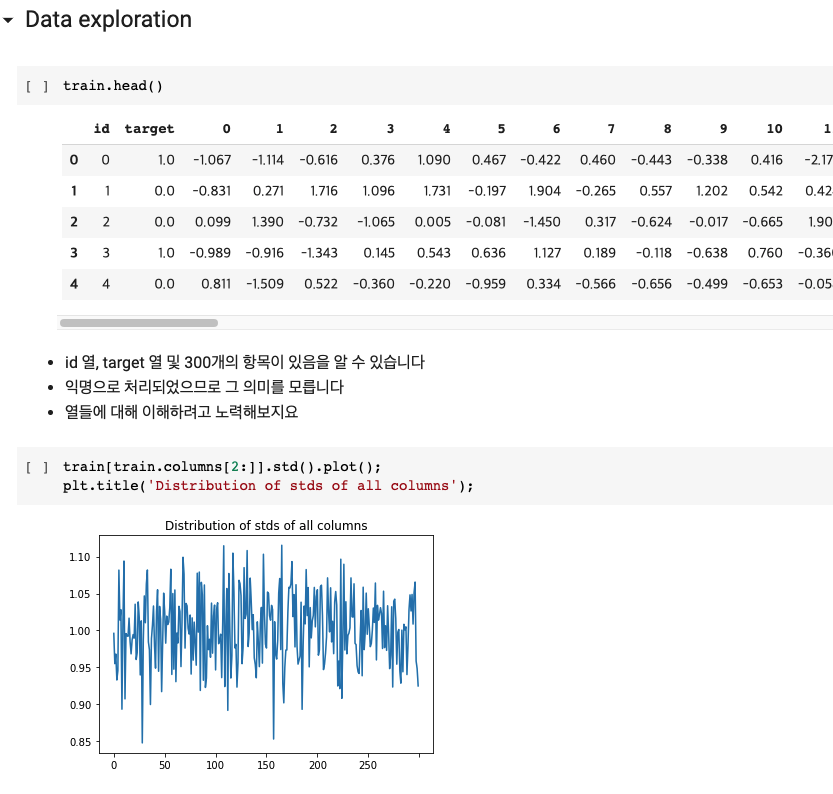
1. 필요한 데이터 부분만 슬라이싱하여 그래프 그리기
데이터의 id, target 부분은 그래프로 그릴 필요가 없기에 columns[2:]로 하여 그래프를 그렸다.
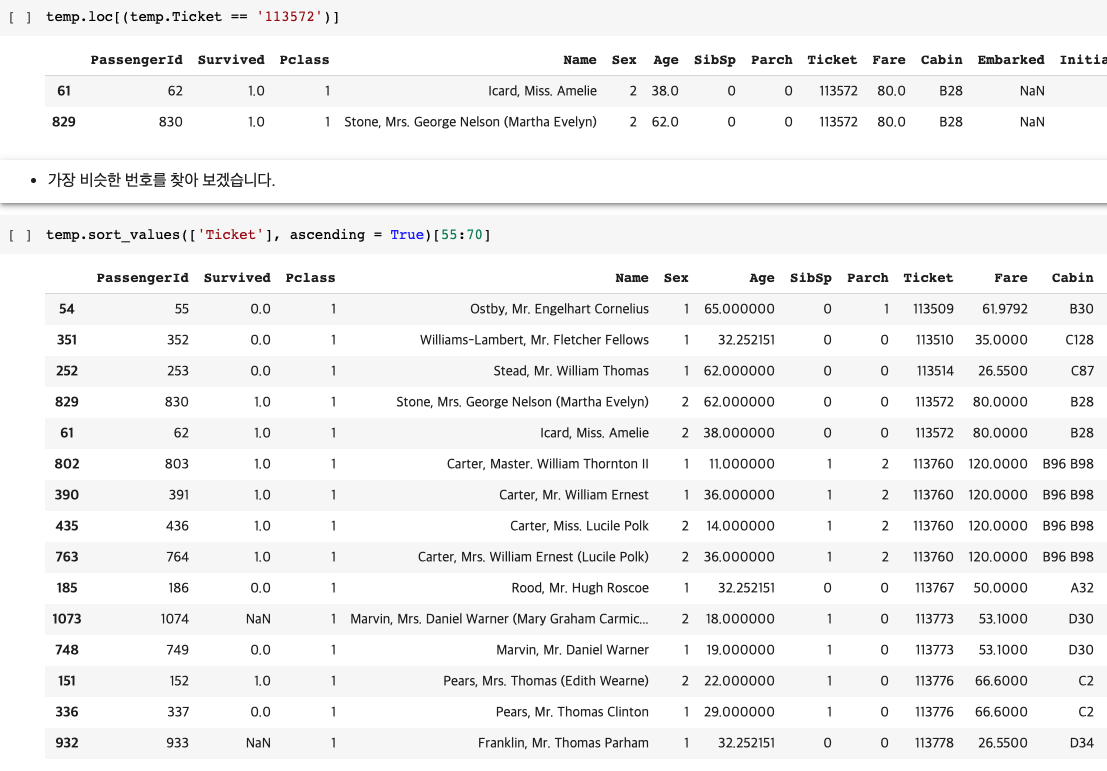
2. 비슷한 주변 값들 데이터만 보고 싶을 때
범주형/순위형 데이터의 결측치를 처리할 때, 주변 값들만 확인하기 위해 슬라이싱 하였다.
[요약]
1. 슬라이싱은 간결하게 하라!
2. 슬라이싱은 범위를 넘어가는 시작 인덱스나 끝 인덱스도 허용한다.
3. 대입에 슬라이스를 사용하면 원본 리스트에서 지정한 범위에 들어 있는 원소를 변경한다!
한 줄 생각
슬라이싱 간편하고 좋구나

To be a changer who can overturn world