1. 스트라이드(stride)
- 리스트[시작:끝:증가값]으로 일정한 간격을 두고 슬라이싱 할 수 있음.
- 시퀀스를 슬라이싱하면서 매 n번째 원소만 가져올 수 있다.

2. 스트라이드(stride) 단점
2-1. 버그 발생
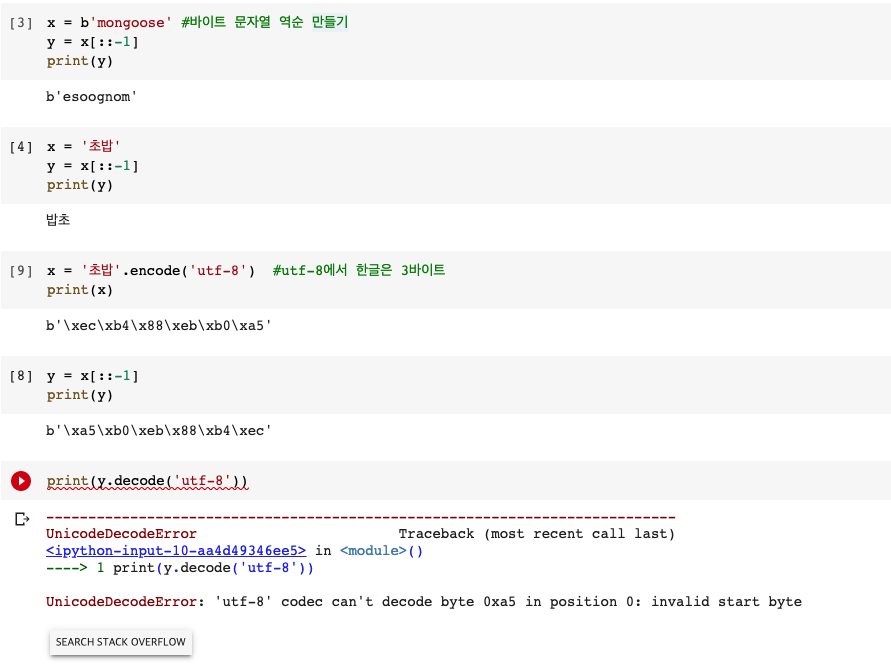
- 바이트 문자열/ 유니코드 문자열에선 스트라이드 기법이 잘 작동한다.
- 하지만 유니코드 데이터를 'utf-8'로 인코딩한 문자열에서는 작동하지 않는다.
- 'utf-8' 인코딩 바이트 문자열 코드에서 2바이트 이상으로 이뤄졌던 문자들은 코드가 깨지기 때문에, 다시 디코딩할 수는 없다.
- 단, 모든 문자가 아스키 코드 범위에 들어가는 문자라면 아무 문제가 없을 수도 있다.

2-2. 코드 밀도 상승

- x[::2] : 시작부터 매 두 번째 원소를 선택
- x[::-2] : 끝에서 시작해 앞으로 가면서 매 두 번째 원소 선택
- 슬라이싱 구문에 스트라이딩까지 들어가면 코드 밀도 올라가서 읽기 어려움.
3.제안
3-1. 스트라이딩 한 결과를 변수에 대입한 다음 슬라이싱 하라!
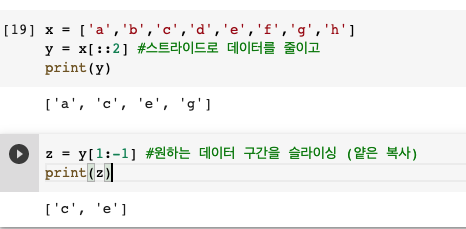
- 스트라이드로 데이터를 줄인 후에 원하는 데이터 구간을 슬라이싱(얕은 복사)
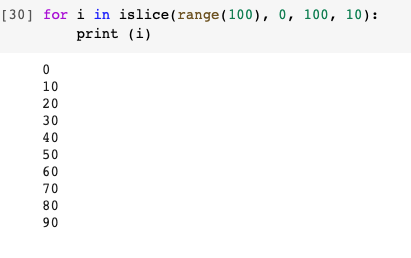
3-2. 성능이 필요할 때엔 itertools.islice() 사용하라!
- islice(iterable객체,start, stop,step)의 함수
- 첫 번째 매개 변수 : 반복 가능한 객체
- 두 번째 매개 변수 : start, 시작 위치
- 세 번째 매개 변수 : stop, 끝 위치
- 네 번째 매개 변수 : step, 각 반복 후에 건너 뛸 단계

참고
1. 아스키코드(ASCII)
- 최초의 문자열 인코딩
- 아스키 코드는 모든 문자 하나가 1byte를 차지한다.
- 영어, 숫자, 부호 등 128개의 문자를 1바이트로 표현하도록 구성된 코드.
- 아스키 코드만으로는 한글이나 일어 등의 다른 문자를 표시할 수 없다.
- 따라서 각 언어권에서 영어 외의 문자를 정의하는 코드 생김.
2. 멀티바이트 코드(ISO-2200)
- 아스키 문자 코드에다가 다른 문자(2byte)들을 포함한 문자 집합.
- 특정 문자 집합마다의 코드 페이지가 존재 (한글 코드 페이지로 해석하면 한글이 나오지만, 일어 코드 페이지로 해석하면 일어가 나온다.)
- 그래서 종종 깨지는 문자 발생
3. 유니코드 (국제 표준)
- 인코딩이 아님!
- 유니코드를 인코딩 하기 위해 UTF-8, UTF-16 탄생!!
- 이를 해결하기 위해 탄생!
- 아스키 문자 코드 뿐만 아니라, 한글, 일어 등등 어떠한 문자들을 총 망라하여 각 한 문자에 2byte씩으로 할당하여 만든 문자 집합
- 각각의 특정 문자는 고유의 유니코드값을 가짐.
4. ANSI(American National Standard Institute)
- 8bit로 구성되어 있으며, 256개의 문자를 표현할 수 있다.
- ASCII 코드에서 1bit를 더 사용한 것이기 때문.
- ANSI의 앞 7bit는 ASCII와 동일하고, 뒤에 1bit를 이용하여 다른 언어의 문자를 표현함.
- CodePage: 각 언어별로 code 값을 주고, Code마다 다른 문자열 표를 의미하도록 약속함.
- 즉, ANSI = ASCII(7bit) + CodePage(1bit)
- CodePage가 다를 경우 의도와 다른 결과가 나올 수 있다.
5. EUC-KR(Extended Unix Code-Korea)
- 한글 지원을 위해 유닉스 계열에서 나온 완성형 코드 조합.
- 즉, 문자 하나하나마다 코드 번호를 부여함.
- 반대되는 걔념으로 조합형 코드 : 한글의 자음/모음에 코드 번호 부여 후 초,중,종성을 조합하여 하나의 문자를 나타내는 방식
- EUC-KR은 ANSI를 한국에서 확장한 것으로 외국에서 지원 가능성 낮음.
- 2byte 완성형 코드로, 2byte 내에서 표현할 수 있는 완성된 문자의 수는 한계가 있음.
6. CP949(Code Page 949)!!!
- 한글 지원을 위해 윈도우즈 계열에서 나온 확장 완성형 코드 조합.
- 949는 한국, 932는 일본, 936은 중국어 간체.
- EUC-KR과 호환되며, 표현이 되지 않는 문자는 조합을 하여 표현함.
7. UTF-8(Universal Coded Character Set + Transformation Format -8bit)
- 유니코드를 위한 가변 길이 문자 인코딩(멀티바이트) 방식 중 하나로, ANSI의 단점을 보호하기 위해 만들어짐.
- 멀티바이트(1~4byte)로 최대 1,112,064자까지 표현 가능
- 첫 128자는 ASCII 코드 값으로 ANSI, UTF-8이 동일
- 영어 : 1byte
- 중동지역, 유럽 언어 : 2byte
- 한국,중국,일본 등 : 3byte 이상 사용 (비효율적)
8. UTF-16
- 한글을 2bytes, 용량의 이점이 있을 수 있다.
- ANSI와 호환이 안됨.
9. UTF-32
- 모든 문자를 4bytes로 인코딩.
- 매우 비효율적.

To be a changer who can overturn world