
Hands-On Machine Learning with Scikit-Learn and TensorFlow 책을 공부하고 내용을 정리한 글이다.
Artificial Neural Network
뉴런들이 어떻게 결합해서 작동하면 복잡한 생각을 하게 되는걸까?
이것이 Artifical Neural Network가 처음 등장하게 된 배경이다.
간단해 보이는 행동이라도 그 배경엔 거대 네트워크가 존재하고 각 구성요소들이 복잡하게 얽힌 관계로 동작한다.
개념이 등장한 후에 바로 발전이 이루어진 것이 아니라 발전이 거의 이루어지지 않거나 거의 잊혀지기를 반복했다.
그러던 중 학습할 수 있는 데이터의 수가 많아지고, 컴퓨팅 자원이 발전하고 학습 알고리즘이 무수히 많이 생겨나면서 ANN도 다시 발전을 이룰 수 있게 되었다.
Perceptron
퍼셉트론은 ANN의 구조 중 가장 단순한 것이다.
만약 뉴런이 이전 단계의 뉴런과 모두 다 연결되어 있으면, 이를 fully connected layer라고 부른다.
X: input features
W: connection weights (basis 뉴런을 제외한)
b: bias vector
activation function
퍼셉트론 학습 방법의 원리는 두 개의 뉴런을 연결하는 가중치가 클수록 두 개의 뉴런의 결과값이 비슷할 것이라는 점이다.
이 원리를 활용해서 에러를 줄이는 방식으로 학습이 진행된다.
여러 개의 퍼셉트론을 쌓아 만든 것이 Multi-Layer Perceptron(MLP)이다.
이는 하나의 퍼셉트론으로 해결하기 어려운 문제의 한계를 뛰어넘기 위해 만들어졌다.
MLP는 각각 하나의 input, output layer와 hidden layer들로 구성되어 있다. 그리고 각 layer들은 fully connected layer이다.
만약 ANN이 deep stack of hidden layer를 갖고 있다면, 이를 deep neural network(DNN)이라고 한다.
MLP를 학습하기 위해 제시된 한 가지 방법으로는 Backpropagation이 있다. 간단하게 말하면, 기울기를 자동적으로 계산해주는 Gradient Descent 방법이라고 생각하면 된다.
모델 학습을 다 시킨 후에 학습 방향의 반대로 error를 계산해 나가며 모델 학습을 진행한다.
Backpropagation에 활용되는 활성화 함수로는, logistic function, hyperbolic tangent function, ReLU function 이 있다.
활성화함수를 사용하는 이유는 입력값에 대한 출력값이 비선형으로 나오고, 비선형 함수를 사용하면 신경망을 깊이 있게 이해할 수 있기 때문이다.
Regression MLP
MLP는 회귀 문제에 사용될 수 있다.
구하고자 하는 예측값의 개수에 따라 ouput 뉴런의 개수가 정해진다.
Classification MLP
만약 이진분류 문제라면, 로지스틱 함수를 활성화함수로 사용해서 0 또는 1의 값이 나오는 단일 뉴런을 ouput neuron으로 지정할 것이다.
Keras
Keras는 인공신경망 모델을 구현, 학습, 평가하는데 있어 성능 높은 딥러닝 API 이다.
Training Deep Neural Network
DNN을 학습하는데 있어 겪을 수 있는 몇가지 어려움들이 있다.
Vanishing Gradient Problem
학습이 진행될수록 Grdient의 변동은 거의 없어지고, 운이 나쁘다면 수렴하지 못하는 좋지 않은 결과를 낼 수 있다. 이를 vanishing gradient 문제라고 한다.
이 반대의 경우, Gradient가 계속해서 커질 때는 Exploding gradient 문제라고 불린다.
이와 관련하여 “Understanding the Difficulty of Training Deep Feedforward Neural Networks” 논문에 몇 가지 관점이 등장한다. (참고)
+) Leaky ReLU function
Batch Normalization
Vanishing/Exploding Gradient Problem을 다루기 위해 등장한 방법 중 하나이다.
각 input을 0을 중심으로 센터링하고 정규화하는 과정을 거치는 것이다. 즉, 모델을 알맞은 크기와 각 레이어의 평균값에 기반하여 학습을 진행하는 것이다. 만약 nerual network 첫 번째 레이어를 BN으로 지정하면, 데이터를 표준화시킬 필요가 없다.
Gradient Clipping
Exploding Gradient 문제를 방지하기 위한 또 다른 방법은 역전파 도중의 gradient를 지정해두고 그 임계값 이상은 못 넘도록 하는 것이다.
Reusing Pretrained Layer
매번 DNN을 학습시키는 것은 적절하지 않을 수 있다. 그렇기 때문에 비슷한 문제에 대해 사전에 미리 학습되어 있는 레이어를 재사용하는 방법도 있다. 그 레이어들의 밑부분을 활용하는 것을 전이학습(transfer learning)이라고 한다. 이는 학습데이터의 양을 줄일 수 있을 뿐만 아니라 속도도 빨라진다.
Unsupervised Pretraining
만약 복잡한 문제인데 데이터도 라벨링 되어 있지 않고 사전에 학습되어 있는 레이어들도 존재하지 않는다면?
Restric‐ ted Boltzmann Machines과 같은 알고리즘을 활용해서 각 레이어마다 unsupervised pretraining을 진행할 수 있다.
Momentum Optimization
θ ← θ – η∇θJ(θ)
Gradient Descent는 위와 같은 공식을 활용하고 초기의 기울기가 얼마가 됐든, 해당 로컬의 기울기가 작으면 작은 step으로 학습이 진행된다.
Momentum Optimzation은 이전 기울기를 함께 신경 쓴다는 차이점이 존재한다.
1. m ← βm − η∇θJ(θ)
2. θ ← θ + m
이처럼 모멘텀 벡터를 함께 고려한다는 것이다.
Nesterov Accelerated Gradient
- m ← βm − η∇θJ(θ + βm)
- θ ← θ + m
그 다음 기울기 선택도 대부분 올바른 방향으로 진행될 것으로 기대하기 때문에 조금 앞서 기울기도 함께 고려한다는 차이점이 있다.
AdaGrad
AdaGrad 알고리즘은 가파른 차원에 따라 기울기 벡터를 스케일링한다. 즉, 피처별로 학습률을 Adaptive하게 조절하여 학습을 진행하는 것이다.
AdaGrad는 이차 방정식 문제에서 좋은 성능을 보이지만, 학습 진행이 일찍 끝난다는 한계가 있다.
RMSProp
AdaGrad가 학습을 진행하다 수렴하여 학습이 더 이상 진행되지 않을 수 있다는 한계를 보완하기 위해 등장한 방법이다.
Deep Computer Vision
Convolution Layer
CNN을 구성할 때, Convolution Layer는 중요 요소이다.
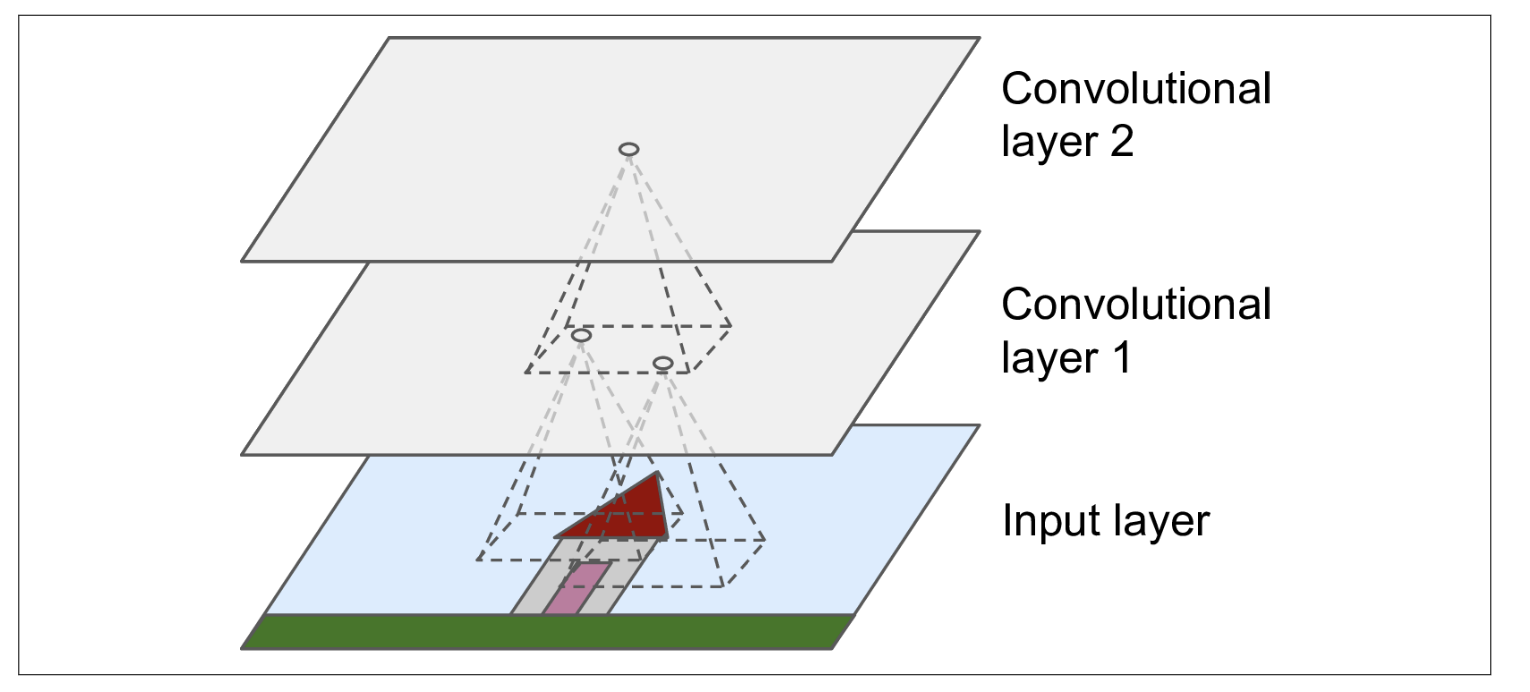
Pooling Layer
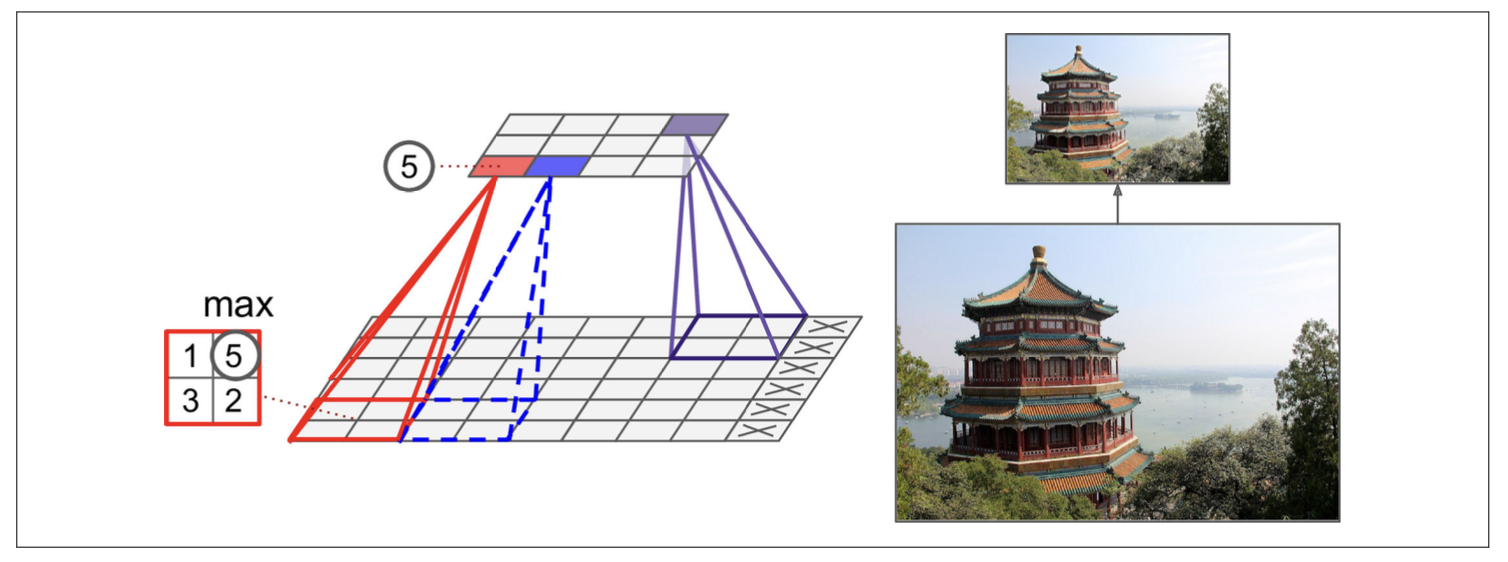
주로 CNN은 Convolution layer와 Pooling layer가 서로 번갈아 가며 구성되어 있다.
LeNet-5, AlexNet, GoogLeNet, VGGNet, SENet, ... 등의 모델이 존재한다.
마치며
Machine Learning에 대한 기본 개념을 다시 다지면서 전체적으로 다시 되돌아볼 수 있는 시간이었다. 앞으로 까먹지 않도록 꾸준히 공부해야겠다.
