지난주 금요일에 이어 호텔 데이터를 마저 다뤘다. 전처리는 금요일에 끝내서 오늘은 데이터를 시각화하며 상관관계와 인사이트를 도출하는 것에 집중했다. 호텔에서 일하며 얻은 지식이 꽤나 도움이 됐다. 전처리 할 땐 과연 내가 유의미한 결과를 얻을 수 있을까 걱정했는데, 시각화해서 보니 어느 정도 답이 나왔다. 역시 데이터는 가독성이 중요한 것 같다. 오늘도 굉장히 값진 깨달음을 몇 개 얻었다. 필요에 의해 찾아낸 코드니 평생 기억에 남았으면 좋겠다. 부디...!! 그래프는 기본 셋팅이면 충분하다고 생각했는데, 의외로 섬세한 셋팅이 필요한 때가 있다는 사실을 알게 됐다. 그리고 matplotlib 너무 어렵다 ㅠㅠ 주말에 연습해야지...
학습시간 09:00~00:00(당일15H/누적137H)
1. 오늘 깨달은 것
- index와 isin()함수로 df조건을 걸 수 있음!
# 1. country별 개수 계산
country_counts = df['country'].value_counts()
# 2. 3000개 이상 등장하는 country만 필터링
top_countries = country_counts[country_counts > 3000].index
# 3. 원본 데이터에서 해당 country만 선택
filtered_df = df[df['country'].isin(top_countries)]
# 4. countplot 그리기
sns.countplot(data=filtered_df, x='country')- dt.strftime('%a')를 까먹었다가 다시 알았음!
df['arrival_day'] = df['arrival_date'].dt.strftime('%a')- df를 2개 나눠서 시각화에 사용할 수 있음!
group_df = df[df['market_segment'] == 'Groups']
corporate_df = df[df['market_segment'] == 'Corporate']- 그래프 2개를 한 결과물에 출력할 수 있음!
# 1행 2열에 서브플롯 생성, 전체 크기 (15, 6)
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 전체 제목 설정
fig.suptitle('title', fontsize=20, fontweight='bold')
# axes[0]는 플롯1
sns.countplot(data=df, x='A', ax=axes[0], color='c')
# axes[1]는 플롯2
sns.barplot(data=df, x='A', y='B', errorbar=None, ax=axes[1], color='r') 2. 호텔 데이터 시각화
지난 주 금요일 했던 호텔 데이터 전처리 두 번째 시간이다! 오늘은 이녀석 끝장을 봐야지!
(1) 지난 주 내용
히트맵을 1차적으로 살펴보고, 두 호텔의 취소율을 비교했다.
sns.heatmap(df.corr(numeric_only=True), annot=True, fmt=".2f")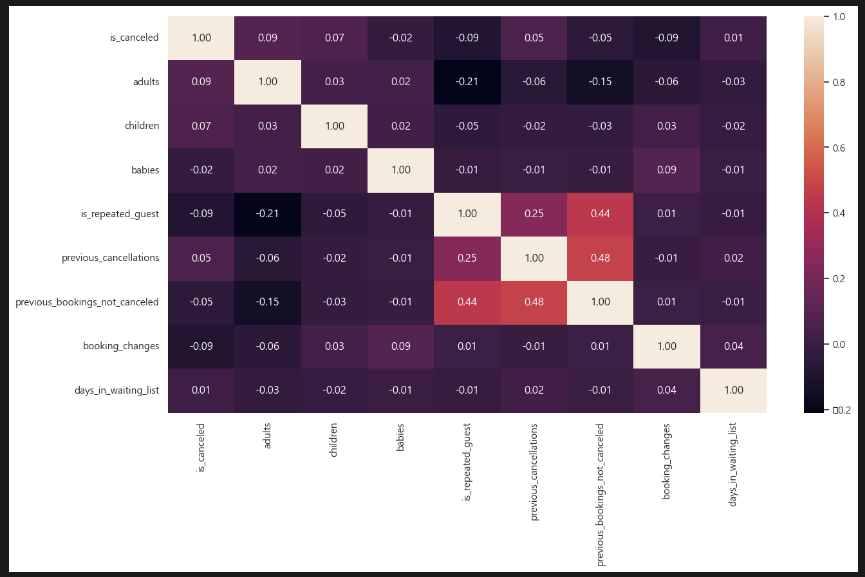 히트맵 상에선 크게 눈에 띄는 상관관계가 보이지 않는다.
히트맵 상에선 크게 눈에 띄는 상관관계가 보이지 않는다.
sns.barplot(data=df, x='hotel', y='is_canceled')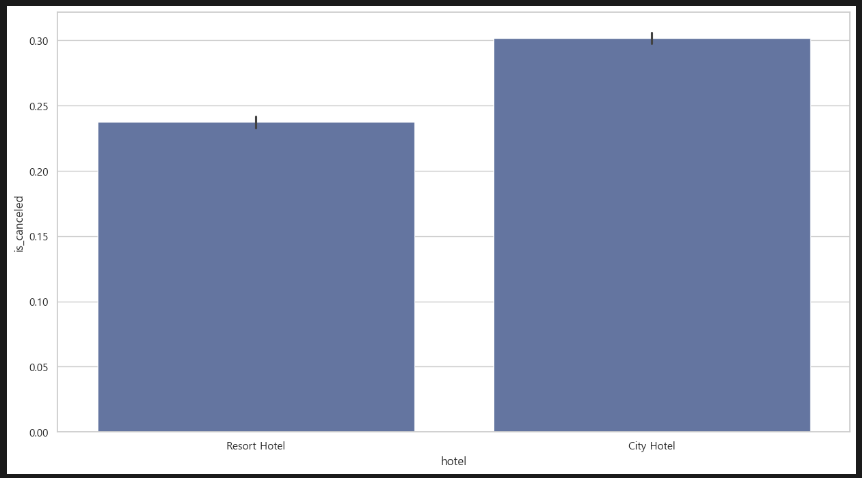 이유는 잘 모르겠으나, 일단 City Hotel의 취소율이 더 높다.
이유는 잘 모르겠으나, 일단 City Hotel의 취소율이 더 높다.
(2) 컬럼별 상관관계
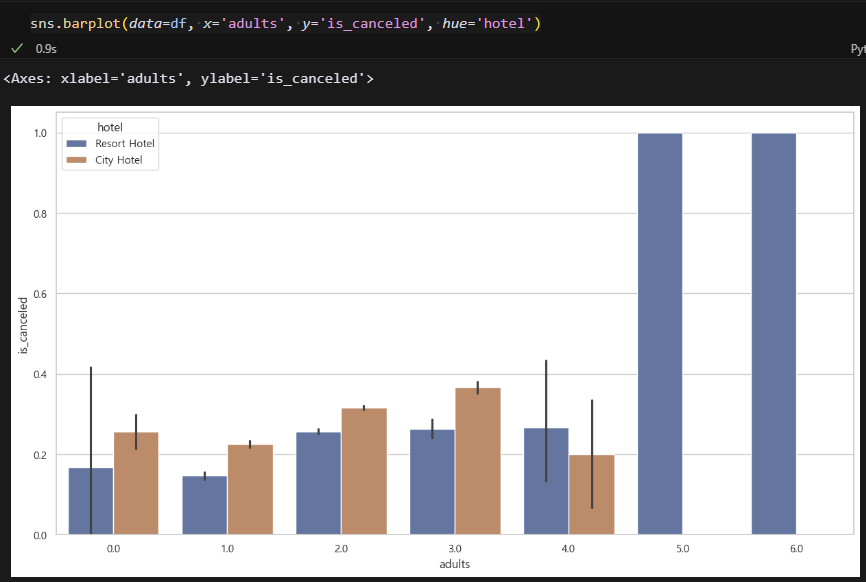 투숙객 5명 이상은 전부 취소인 것을 알 수 있다. 예약을 잘못해서 취소했나? 그 다음은 3명일 때가 취소율이 높다. 그다지 큰 연관은 없어보이나, 굳이 따지자면 투숙객 3명을 붙잡을 수 있는 프로모션을 하면 취소율이 낮아질 것 같다.
투숙객 5명 이상은 전부 취소인 것을 알 수 있다. 예약을 잘못해서 취소했나? 그 다음은 3명일 때가 취소율이 높다. 그다지 큰 연관은 없어보이나, 굳이 따지자면 투숙객 3명을 붙잡을 수 있는 프로모션을 하면 취소율이 낮아질 것 같다.
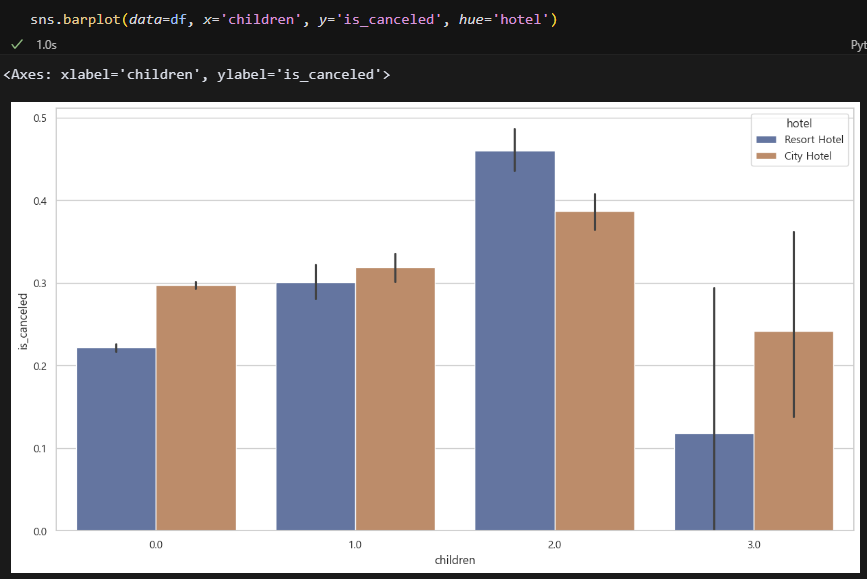 자녀와 동반했다 해서 무조건 취소율이 높은 건 아닌 것 같다. 자녀 수가 3명일 때는 오히려 취소율이 가장 낮았다.
자녀와 동반했다 해서 무조건 취소율이 높은 건 아닌 것 같다. 자녀 수가 3명일 때는 오히려 취소율이 가장 낮았다.
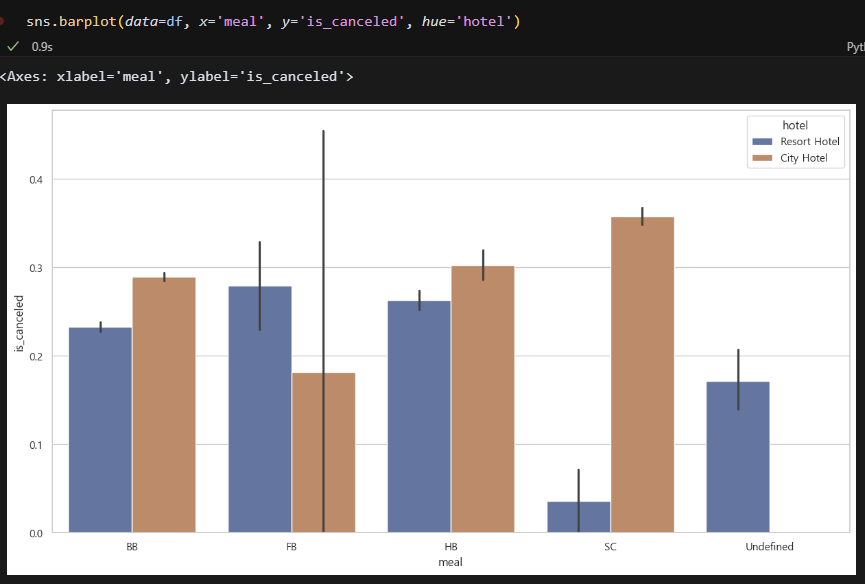 식사 종류도 큰 특이점은 없다. Resort Hotel의 SC식사를 예약한 고객의 취소율이 꽤 낮은 모습이 보인다. 이 부분은 벤치마킹할 필요가 있음.
식사 종류도 큰 특이점은 없다. Resort Hotel의 SC식사를 예약한 고객의 취소율이 꽤 낮은 모습이 보인다. 이 부분은 벤치마킹할 필요가 있음.
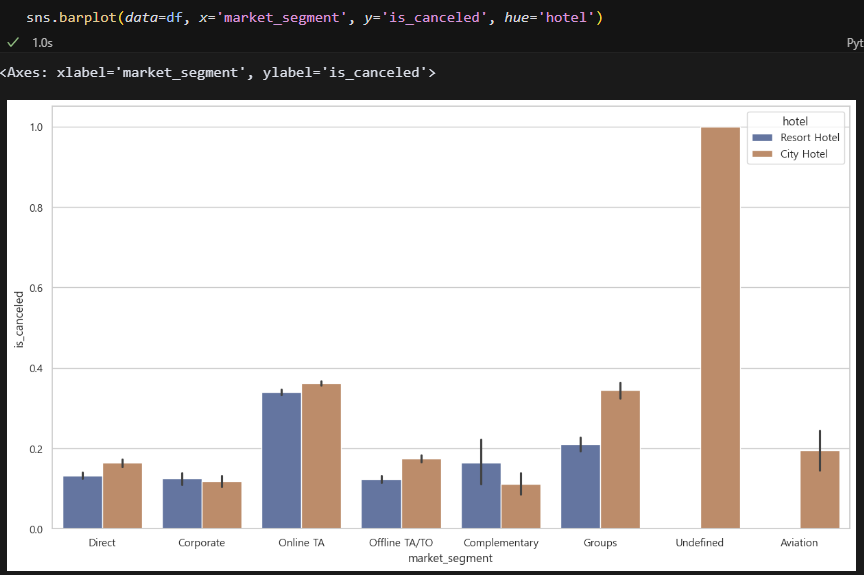 Undefined 제외, 세그먼트 별로보면 OTA취소율과 단체 취소율이 타 세그에 비해 꽤 높다. 통상적으로 단체는 일반 예약에 비해 규정을 느슨하게 풀어주는 경향이 있다. 일반사 취소율이 낮은 것을 보면 단체객실 규정 또한 약간 타이트하게 줄여도 괜찮을 것 같다. 문제는 OTA네.
Undefined 제외, 세그먼트 별로보면 OTA취소율과 단체 취소율이 타 세그에 비해 꽤 높다. 통상적으로 단체는 일반 예약에 비해 규정을 느슨하게 풀어주는 경향이 있다. 일반사 취소율이 낮은 것을 보면 단체객실 규정 또한 약간 타이트하게 줄여도 괜찮을 것 같다. 문제는 OTA네.
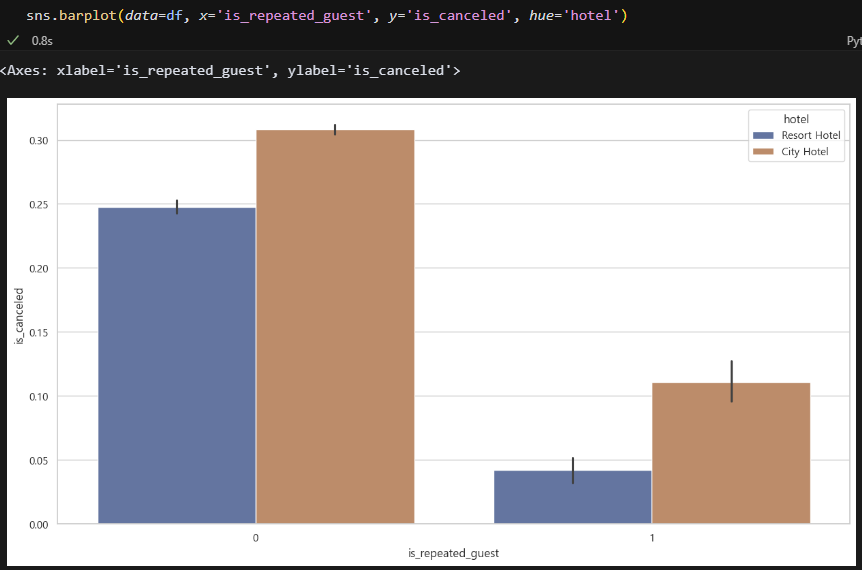 당연한 말인 것 같긴 한데 재방문 고객은 취소하지 않을 가능성이 높다. 첫 방문인 고객에게 혜택을 주든, 아니면 재방문 고객을 계속 유치할 방법을 찾든, 둘 중 하나는 해야할 것 같다.
당연한 말인 것 같긴 한데 재방문 고객은 취소하지 않을 가능성이 높다. 첫 방문인 고객에게 혜택을 주든, 아니면 재방문 고객을 계속 유치할 방법을 찾든, 둘 중 하나는 해야할 것 같다.
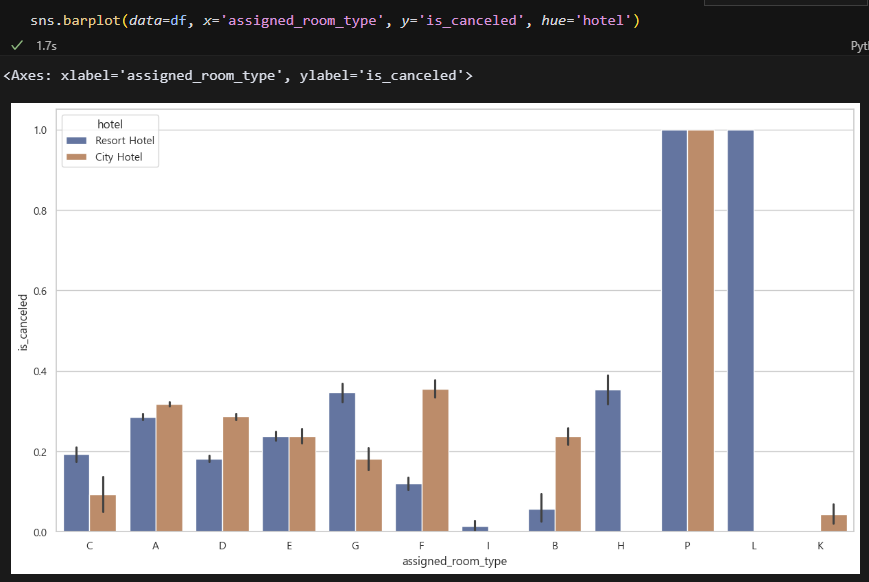 실제 어싸인된 객실 그래프다. 부킹객실과 어싸인객실은 다를 수 있다. 가끔 오버부킹 때문에 객실을 바꿔주는 경우가 있어서 그렇다. 근데 P타입 L타입 객실 취소율이 작살난 상태다. 도대체 무슨 객실인 걸까? 어쨋든 이 객실은 개선이 필요함.
실제 어싸인된 객실 그래프다. 부킹객실과 어싸인객실은 다를 수 있다. 가끔 오버부킹 때문에 객실을 바꿔주는 경우가 있어서 그렇다. 근데 P타입 L타입 객실 취소율이 작살난 상태다. 도대체 무슨 객실인 걸까? 어쨋든 이 객실은 개선이 필요함.
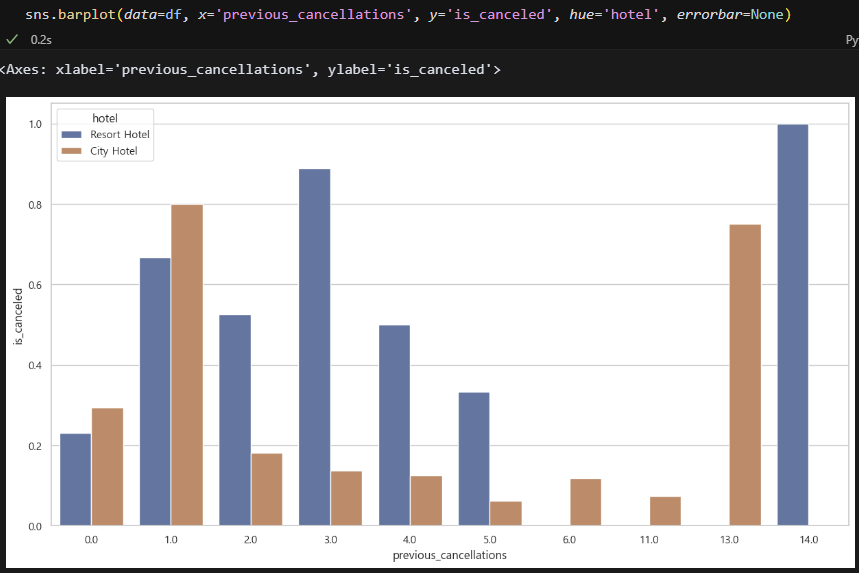 errorbar가 거슬려서 삭제했음. 취소 이력이 있는 고객의 취소율이 더 높다. 근데 이력이 많아질 수록 취소율이 낮아진다. 흠,, 딱히 관계는 없는 듯.
errorbar가 거슬려서 삭제했음. 취소 이력이 있는 고객의 취소율이 더 높다. 근데 이력이 많아질 수록 취소율이 낮아진다. 흠,, 딱히 관계는 없는 듯.
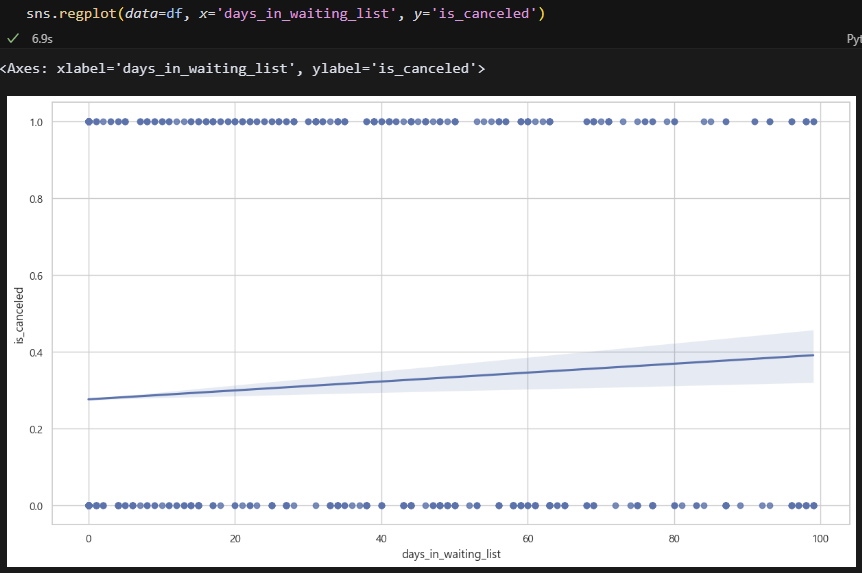 이번엔 웨이팅 기간별 취소율이다. 회귀선을 그어봤는데, 웨이팅이 길어질수록 27%에서 39%로 약 12% 정도까지 취소율이 높아지는 것 같다. 뭐, 당연한 소린가? 그래도 12%면 나쁘지 않은 편인듯 ㅋㅋ 근데 회귀선을 이렇게 해석하는 게 맞나?
이번엔 웨이팅 기간별 취소율이다. 회귀선을 그어봤는데, 웨이팅이 길어질수록 27%에서 39%로 약 12% 정도까지 취소율이 높아지는 것 같다. 뭐, 당연한 소린가? 그래도 12%면 나쁘지 않은 편인듯 ㅋㅋ 근데 회귀선을 이렇게 해석하는 게 맞나?
(3) 국가별 상관관계
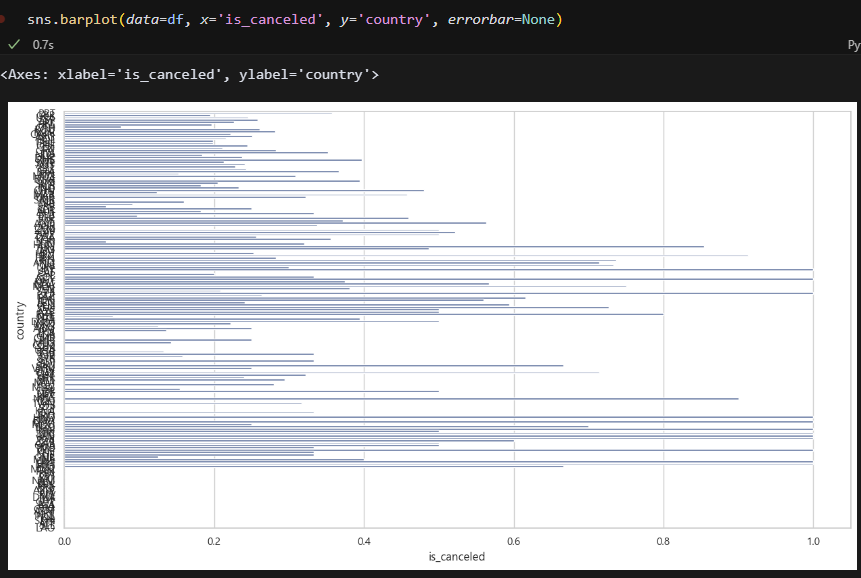 국가별로 비교도 해봤는데, 유독 취소율이 높은 국가가 몇 있다. 너무 많으니까 예약 건수가 많은 상위 몇 개만 추려서 봐야겠다.
국가별로 비교도 해봤는데, 유독 취소율이 높은 국가가 몇 있다. 너무 많으니까 예약 건수가 많은 상위 몇 개만 추려서 봐야겠다.
# 1. country별 개수 계산
country_counts = df['country'].value_counts()
# 2. 3000개 이상 등장하는 country만 필터링
top_countries = country_counts[country_counts > 3000].index
# 3. 원본 데이터에서 해당 country만 선택
filtered_df = df[df['country'].isin(top_countries)]
# 4. countplot 그리기
sns.countplot(data=filtered_df, x='country')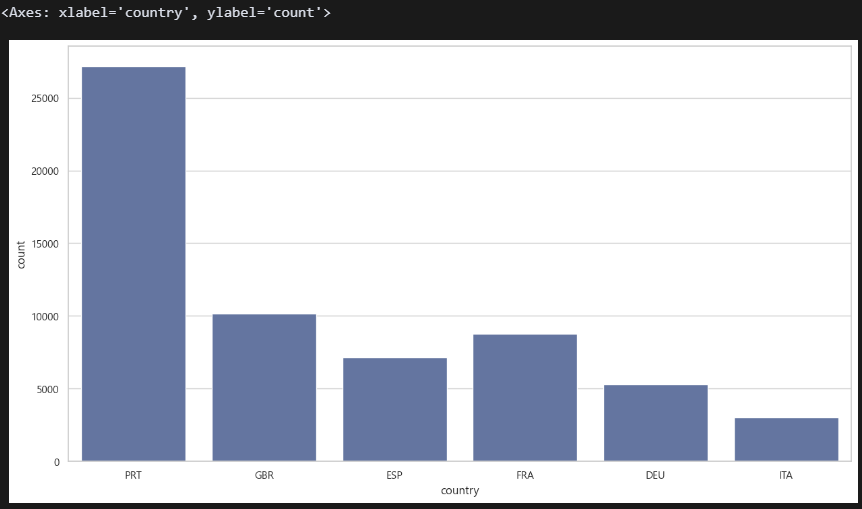 PRT = Portugal(포르투갈)
PRT = Portugal(포르투갈)
GBR = United Kingdom(영국)
ESP = Spain(스페인)
FRA = France(프랑스)
DEU = Germany(독일)
ITA = Italy(이탈리아)
예약 건수가 많은 상위 6개 국가만 추렸다. 어떻게 해야할지 몰라서 도움을 좀 받았음. 특정 수량을 조건으로 건 변수를 만들고 isin()로 필터를 걸면 되는 것 같다. 포르투갈 예약 건수가 제일 많다. 아마도 이 호텔이 포르투갈에 있는 것 같음.
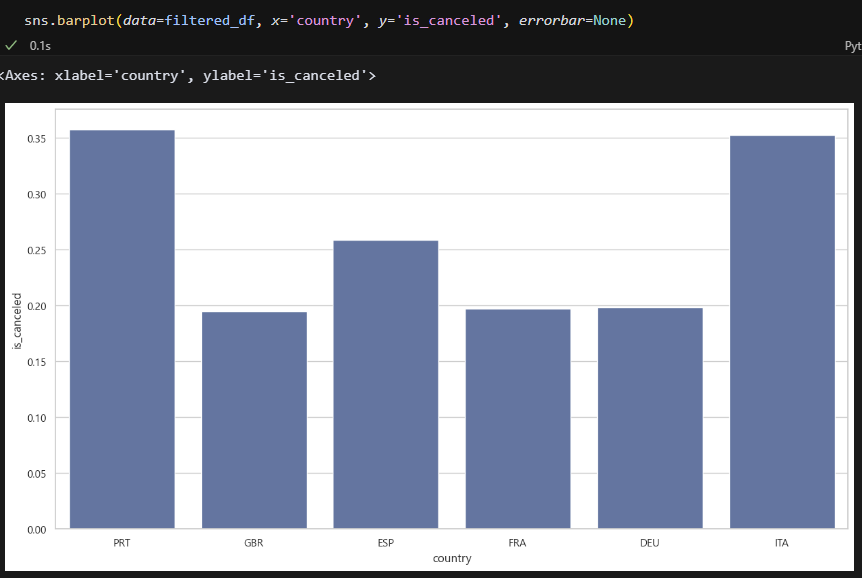 국가별로 드라마틱한 취소율 차이는 없어 보인다. 근데 비율로 따지면 이탈리아가 예약 건수에 비해 취소율이 높다. 이탈리아 고객만 패널티를 줘야하나? 그럼 모양새가 이상한데.. 어쨋든 이탈리아 관련 예약 받을 때 취소를 염두에 두면 좋을듯.
국가별로 드라마틱한 취소율 차이는 없어 보인다. 근데 비율로 따지면 이탈리아가 예약 건수에 비해 취소율이 높다. 이탈리아 고객만 패널티를 줘야하나? 그럼 모양새가 이상한데.. 어쨋든 이탈리아 관련 예약 받을 때 취소를 염두에 두면 좋을듯.
(4) 일자별 상관관계
이제 일자별로 그래프를 뽑아야 하는데, 내가 미처 고려하지 못한 게 있다. 월별 데이터를 봐야하는데 포맷을 yyyy-mm-dd로 해버린 것.
그래서 일단 reservation_status_date열과 arrival_date열을 기반으로 새로운 열 4개를 만들어 줬다.
df['arrival_date_from_reservation'] = (df['arrival_date'] - df['reservation_status_date']).dt.days
df['arrival_year'] = df['arrival_date'].dt.year
df['arrival_month'] = df['arrival_date'].dt.month
df['arrival_day'] = df['arrival_date'].dt.strftime('%a')
dfarrival_date_from_reservation = (체크인 일자 - 객실 예약일)의 값
arrival_year = 체크인 year
arrival_month = 체크인 month
arrival_day = 체크인 day(요일로 설정)
 잘 나온 것을 볼 수 있음.
잘 나온 것을 볼 수 있음.
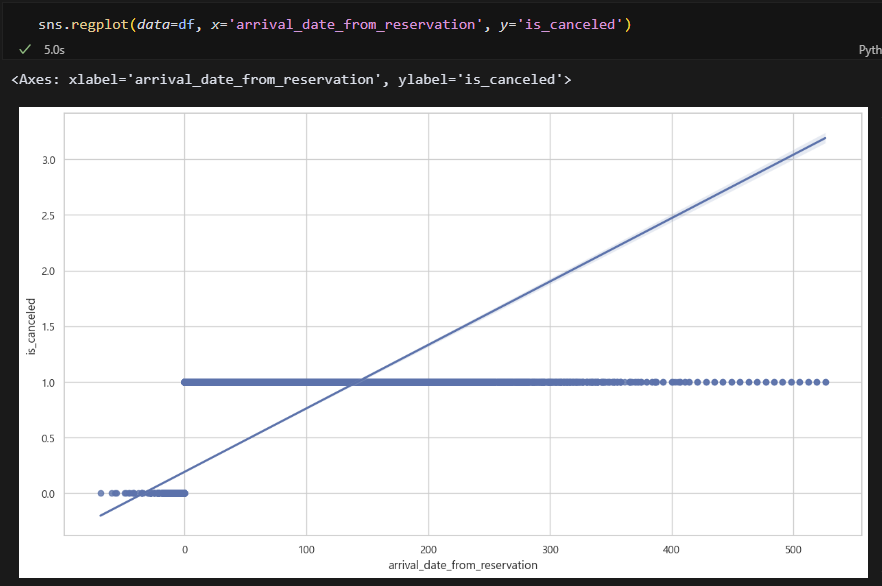 회귀선을 그어보니 확실히 예약 후 시간이 오래 지날수록 취소율이 높아지는 것 같다. 예약 후 140일 정도 지나면 대부분 취소하는 것 같음.
회귀선을 그어보니 확실히 예약 후 시간이 오래 지날수록 취소율이 높아지는 것 같다. 예약 후 140일 정도 지나면 대부분 취소하는 것 같음.
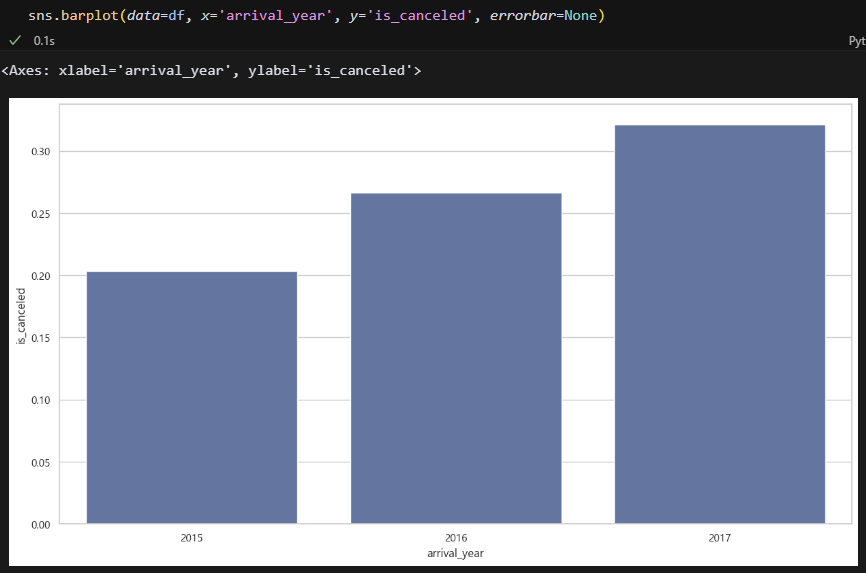 취소율이 매년 5%씩 증가하고 있다. 이건 경기침체 혹은 호텔 평판이 안 좋아지고 있다는 뜻으로 밖에 안 보인다.
취소율이 매년 5%씩 증가하고 있다. 이건 경기침체 혹은 호텔 평판이 안 좋아지고 있다는 뜻으로 밖에 안 보인다.
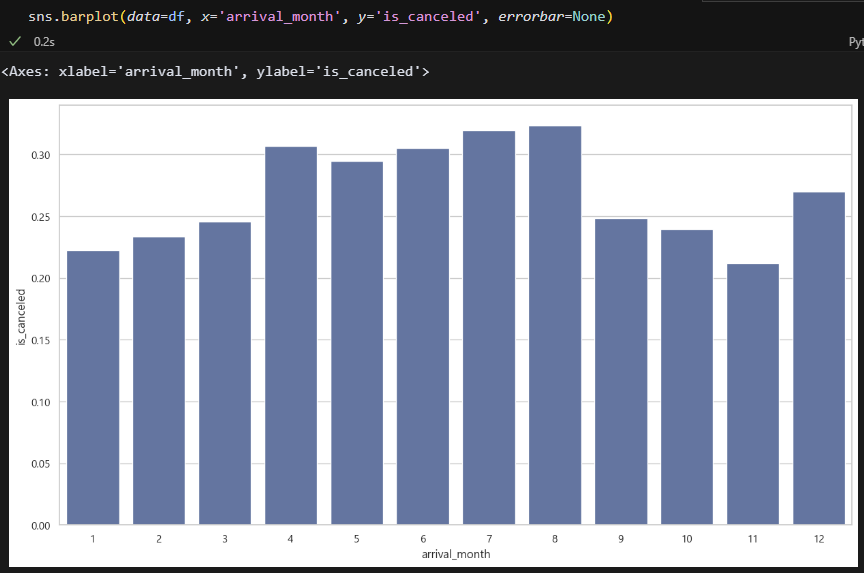 월 비교. 7월 8월 취소율이 가장 높다. 예약율이 높아서 그런 걸까? 아니면 다른 이유가 있나?
월 비교. 7월 8월 취소율이 가장 높다. 예약율이 높아서 그런 걸까? 아니면 다른 이유가 있나?
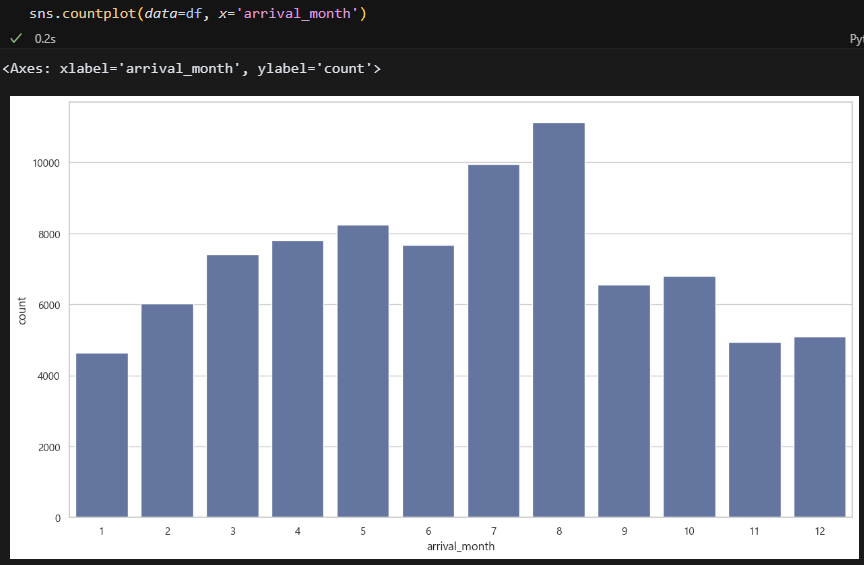 countplot으로 보니 확실히 7월 8월 예약이 많다. 뭐 때문이지? 성수기인가? 포르투갈 계절 순서가 한국이랑 비슷한가?
countplot으로 보니 확실히 7월 8월 예약이 많다. 뭐 때문이지? 성수기인가? 포르투갈 계절 순서가 한국이랑 비슷한가?
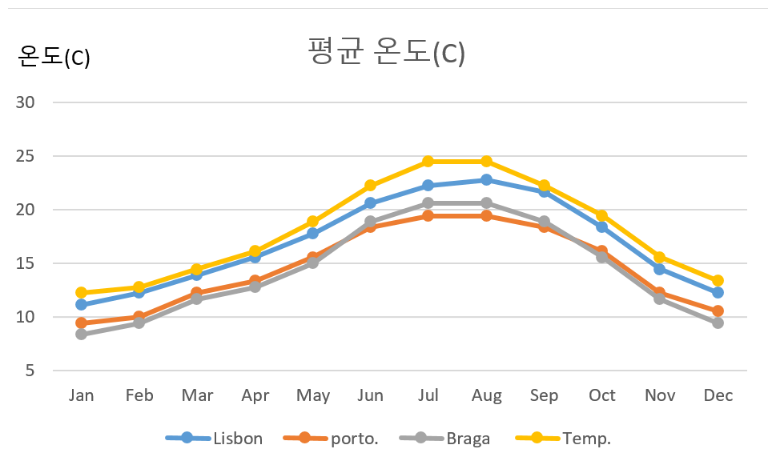 다른 사이트에서 포르투갈 평균 온도를 찾아보니 역시나 7월 8월이 한여름이었다. 여름 성수기에 미어터지는 건 어느 호텔이나 만찬가지인 것 같다.
다른 사이트에서 포르투갈 평균 온도를 찾아보니 역시나 7월 8월이 한여름이었다. 여름 성수기에 미어터지는 건 어느 호텔이나 만찬가지인 것 같다.
그럼 성수기 취소율이 높은 segment를 찾아서 공략하면 호텔 취소율을 전반적으로 낮출 수 있을 것이다. 어떤 Segment의 성수기 취소율이 가장 높을까?
(5) Segment별 상관관계
group_df = df[df['market_segment'] == 'Groups']
corporate_df = df[df['market_segment'] == 'Corporate']
direct_df = df[df['market_segment'] == 'Direct']
online_ta_df = df[df['market_segment'] == 'Online TA']
offline_ta_df = df[df['market_segment'] == 'Offline TA/TO']segment별로 데이터프레임을 따로 만들었다. 아까 그래프 중에 segment 그래프가 있었는데, Groups와 Online TA 비중이 가장 높았다. 그래도 Groups, Corporate, Direct, Online TA 이렇게 4개 정도는 확인해 보자!
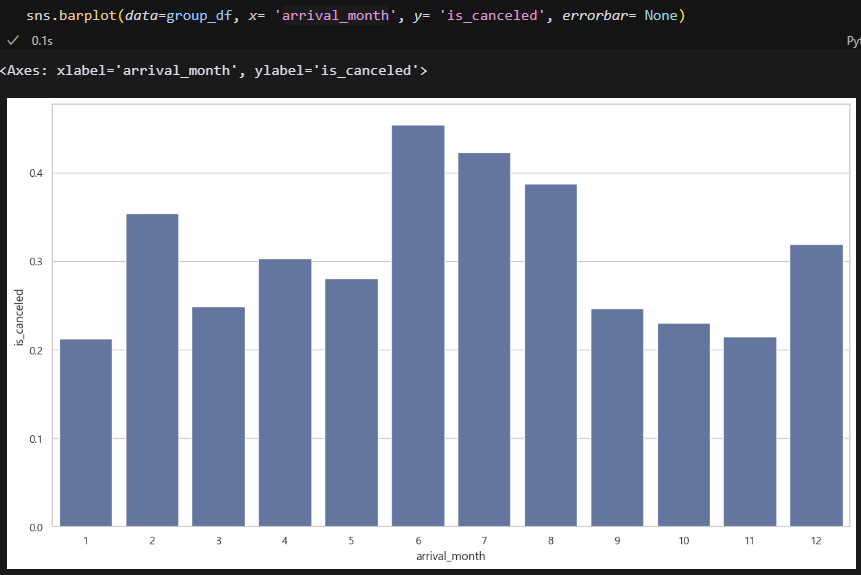 Groups. 6~8월 취소율이 높다. 40% 정도다.
Groups. 6~8월 취소율이 높다. 40% 정도다.
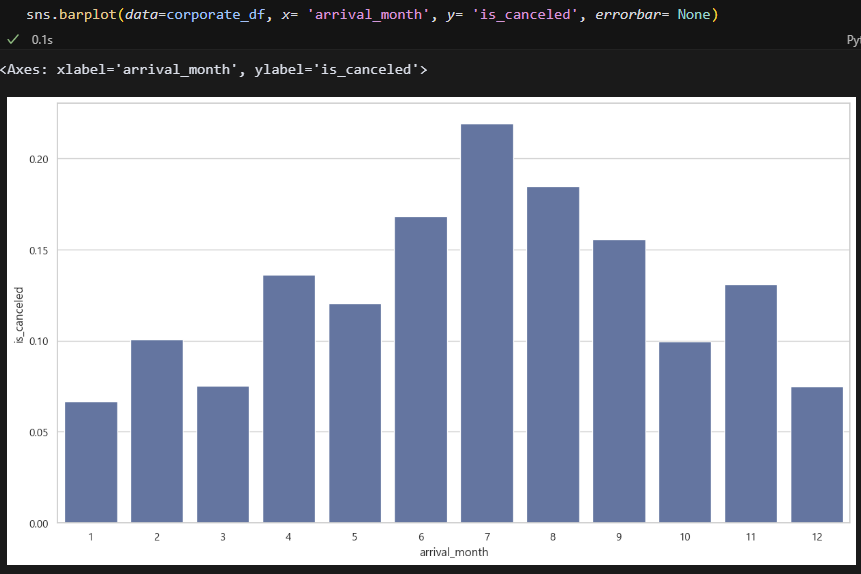 Corporate. 6~8월 취소율이 높다. 20% 정도다.
Corporate. 6~8월 취소율이 높다. 20% 정도다.
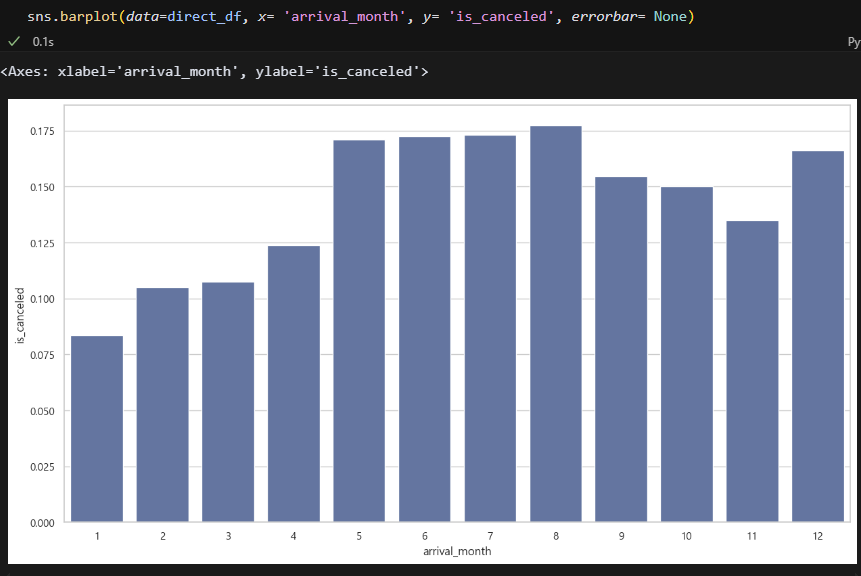 Direct. 1분기 제외 전반적으로 취소율이 비슷하다. 17% 정도다.
Direct. 1분기 제외 전반적으로 취소율이 비슷하다. 17% 정도다.
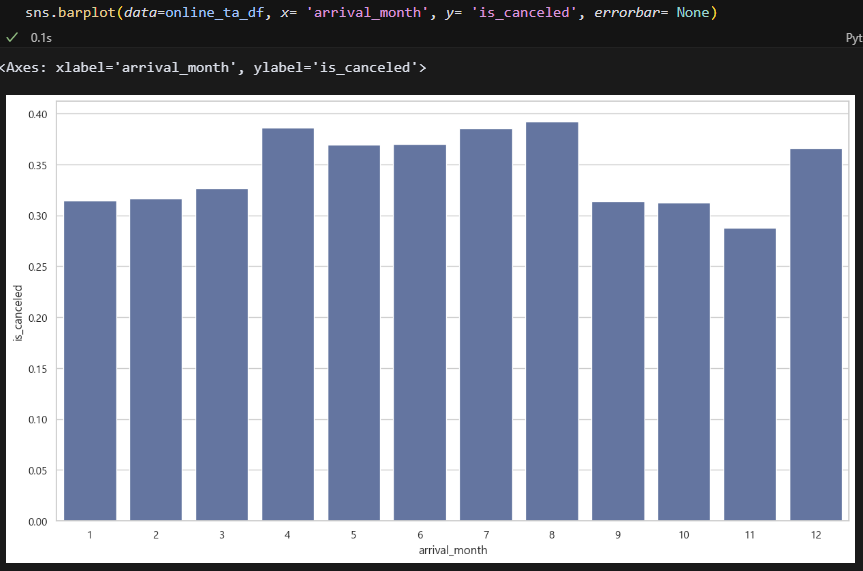 Online TA. 전반적으로 취소율이 높다. 35% 정도다.
Online TA. 전반적으로 취소율이 높다. 35% 정도다.
종합해 보자면,
- 성수기(7~8월)에 취소율이 높다.
- 취소 건수는 OTA가 큰 비중을 차지한다.
- Group 성수기 취소 비중이 높다.
- Corperate 성수기 취소 비중이 높다.
이에 따르면, Groups와 Corperate는 성수기에 집중 관리를 해야할 것이다. 내 생각에 하계휴양소 때문인 것 같은데, 보통 연간 계약하니까 계약 시에 취소 규정을 약간 타이트하게 가져가는 게 좋지 않을까. 그리고 OTA는 전반적으로 규정을 변경할 필요가 있어 보인다.
다음은 요일 별로 볼 차례다. 내 생각에는 금토 취소율이 높을 것 같다. 보통 여행은 금토로 잡고 가니까.
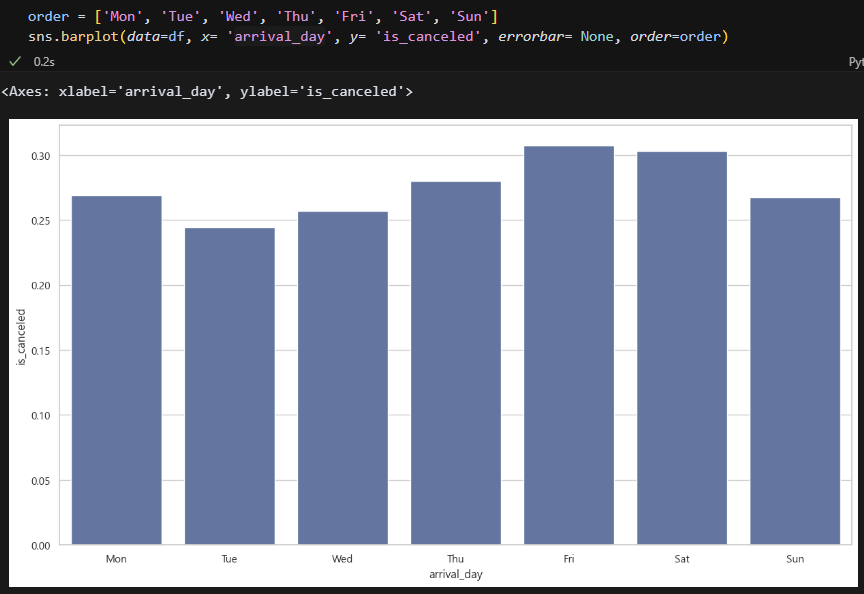 order 변수를 만들어서 요일을 정렬했다. 역시 예상했던 대로 금토 취소율이 가장 높다.
order 변수를 만들어서 요일을 정렬했다. 역시 예상했던 대로 금토 취소율이 가장 높다.
그럼 어느 Segment의 금토 취소율이 제일 높을까? 이게 가장 중요한 것 같다.
(6) 요일 & Segment별 상관관계
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
fig.suptitle('group_df', fontsize=20, fontweight='bold')
sns.countplot(data=group_df, x='arrival_day', order=order, ax=axes[0], color='c')
sns.barplot(data=group_df, x='arrival_day', y='is_canceled', errorbar=None, order=order, ax=axes[1], color='r')그래프 두 개를 한 결과물로 출력하는 코드다. 몰라서 열심히 찾아보다가 결국 알아냄..! 이건 꼭 외워야겠다. 일단 Segment별 그래프를 아래에 싹 다 넣고 요약하겠음!
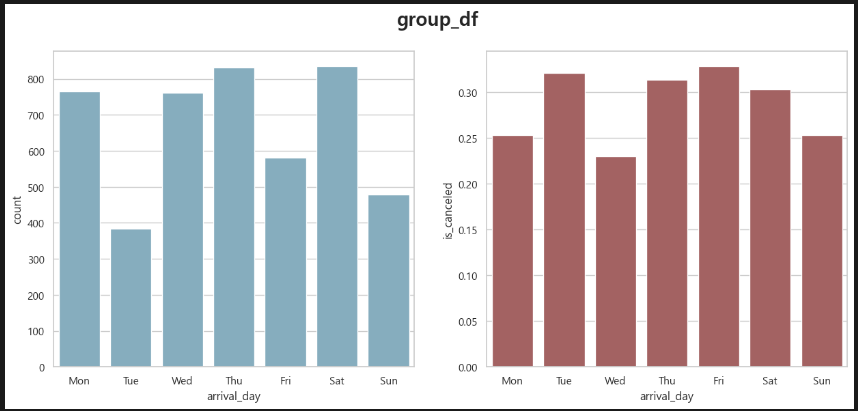 Group. 금토 예약 약 1,400건 취소율 약 30%(420건).
Group. 금토 예약 약 1,400건 취소율 약 30%(420건).
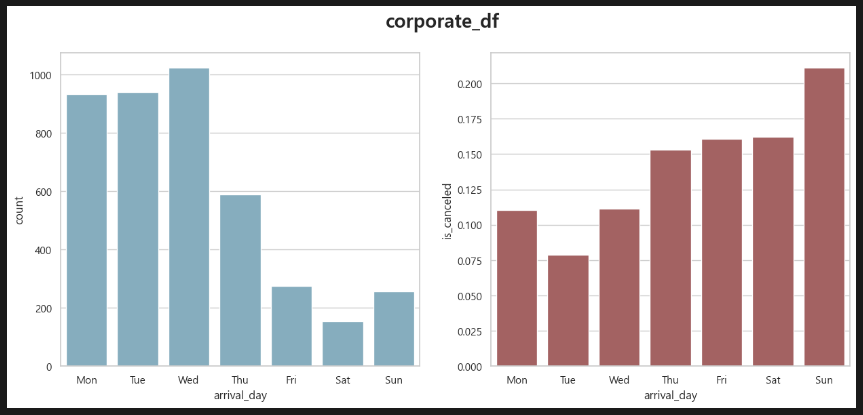 Corporate. 금토 예약 약 400건 취소율 약 15%(60건).
Corporate. 금토 예약 약 400건 취소율 약 15%(60건).
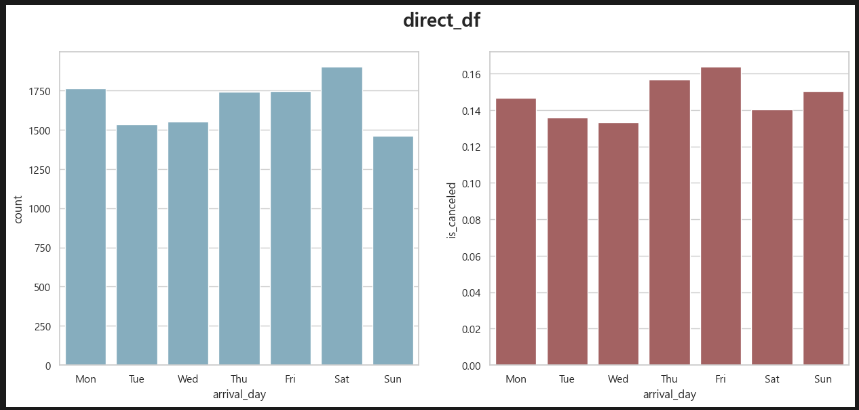 Direct. 금토 예약 약 3,600건 취소율 약 15%(540건).
Direct. 금토 예약 약 3,600건 취소율 약 15%(540건).
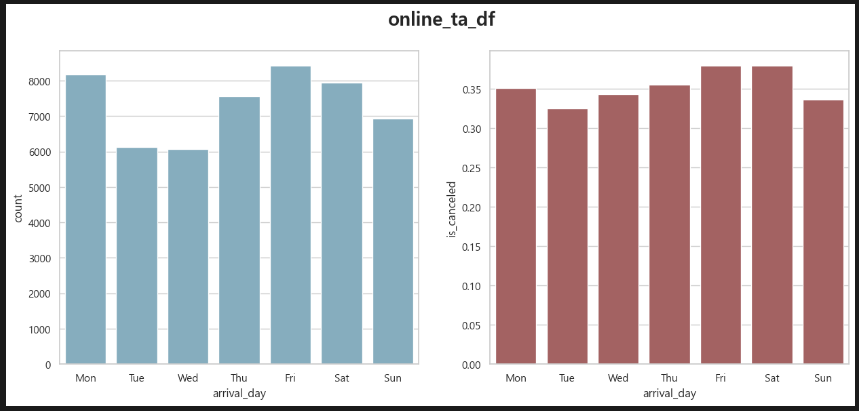 Online TA. 금토 예약 약 16,000건 취소율 약 37%(5,920건).
Online TA. 금토 예약 약 16,000건 취소율 약 37%(5,920건).
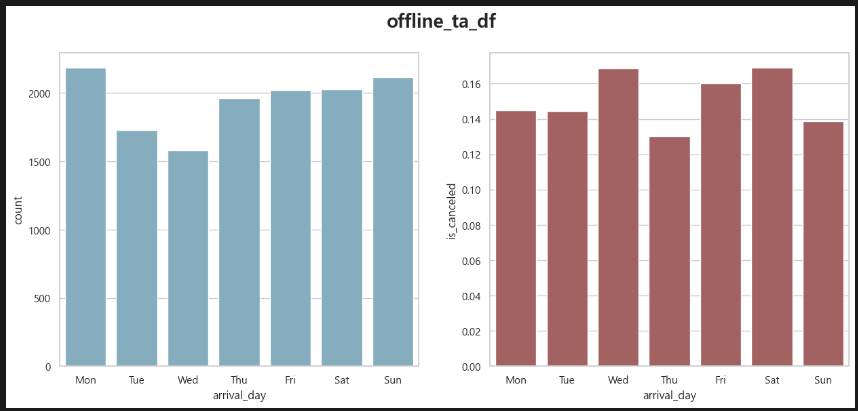 Offline TA. 금토 예약 약 4,000건 취소율 약 15%(600건).
Offline TA. 금토 예약 약 4,000건 취소율 약 15%(600건).
요약하면, 데이터 전체 기간 중 금토 취소 건수는 아래와 같다.
- Group 420건
- Corporate 60건
- Direct 540건
- Online TA 5,920건
- Offline TA 600건건
건수로 보나 비율로 보나 OTA 이 녀석이 가장 문제다. 이 말은 즉, OTA에서 금토 취소가 덜 나오도록 관리하면 호텔의 전반적인 취소율을 개선할 수 있다는 뜻이다.
3. 결론 & 해결방안
(1) 칼럼별
A. 현재상황
- 투숙객 3인일 때 취소율이 약 10% 더 높다.
- 자녀 2인 동반 시 취소율이 약 15% 더 높다.
- OTA와 Groups 취소율이 약 20% 더 높다.
- 첫 방문 고객 취소율이 약 15% 더 높다.
- P & L 타입 객실은 100% 취소된다.
B. 해결방안
- 3인 예약 시 프로모션 제공!
- 자녀 2인 동반 시 프로모션 제공!
- OTA와 Groups 예약 시 프로모션 제공!
- 첫 방문 고객에게 프로모션 제공!
- P & L 타입 객실 개선!
(2) 국가별
A. 현재상황
- 상위 6개 예약국은 포르투갈(27,000건), 영국(10,000건), 프랑스(8,000건), 스페인(7,000건), 독일(5,000건), 이탈리아(3,000건) 이다.
- 포르투갈과 이탈리아의 취소율은 약 35%로 타국 대비 약 15% 높다.
- 건수로 보면 포르투갈 취소자가 가장 많다.
- 비율로 보면 이탈리아 취소자가 가장 많다.
B. 해결방안
- 이탈리아 예약 발생 시 취소를 염두에 두고 오버부킹 진행!
- 포르투갈은 예약자가 많으니 market segment별 대처 필요!
- 아래 (5)번과 (6)번의 내용 참고!
(3) 연별
A. 현재상황
- 체크인 140일 전 예약된 건은 거의 취소된다.
- 매년 취소율이 약 5%씩 상승하고 있다.
B. 해결방안
- 체크인 수개월 전 예약한 고객에게 프로모션가 적용!
- 호텔평판 하락으로 인한 취소율 증가일 수 있으니 확인!
- 경기침체로 인한 취소율 증가라면 일시적으로 객실료 조정!
(4) 월별
A. 현재상황
- 예약자와 평균온도를 고려하면 호텔 성수기는 7~8월로 보인다.
- 7~8월 예약 건수 및 취소율이 가장 높다.
- Group과 Corporate의 7~8월 취소율이 높다.
- OTA은 한 해 전반적으로 취소율이 높다.
B. 해결방안
- Groups와 Corperate의 성수기 하계휴양소의 취소율이 어느정도 되는지 확인!
- OTA는 취소 규정을 소폭 강화할 필요가 있음!
(5) 일별
A. 현재상황
- 금토 취소율이 타 요일에 비해 약 5% 높다.
- Corporate는 금토 투숙 건수가 현저히 낮고, 타 seg는 비슷하다.
- OTA 금토 투숙 건수가 가장 높고, 취소율도 약 37%로 가장 높다.
- 데이터 전체 기간 중 금토 취소 건수는 아래와 같다.
- Group 420건
- Corporate 60건
- Direct 540건
- Online TA 5,920건
- Offline TA 600건
B. 해결방안
- OTA 금토 취소율을 낮추면 호텔 전반적인 취소율 개선 가능!
(6) OTA 개선점
OTA 취소율을 낮추기 위해 어떤 전략을 세울 수 있는가?
A. 무료 취소 기한 조정
무료 취소 기한이 길면 고객들이 쉽게 예약하고 쉽게 취소할 가능성이 높다. 반발이 없는 적정지점을 찾아 무료 취소 기한을 단축하거나, 기한에 따른 페널티를 추가한다.
B. 환불불가 요금제 도입
객실을 저렴한 가격에 제공하는 대신 환불이 불가능한 요금제를 추가한다. 총매출이 소폭 감소할 수 있으나 취소율을 개선할 수 있다. 하지만, 객실 가동률이 이미 높다면 굳이 저렴한 요금제를 만들지 않아도 매출에 큰 영향이 없으므로 권장하지 않는다.
C. 일정 변경 옵션 제공
당 호텔 객실 가동률이 이미 높을 경우, 취소를 희망하는 고객에게 1회에 한하여 일정 변경을 할 수 있는 옵션을 주어 취소를 방지한다. 단, 이때 일정을 변경한 고객은 이후에 절대로 취소할 수 없도록 한다.
D. OTA 고객 프로모션
OTA를 통해 예약한 고객에게 체크인 시 웰컴 드링크, 무료 조식 등의 혜택을 제공한다. 단순히 높은 요금 때문에 타 호텔 투숙을 고려하는 고객이라면 취소를 방지할 수 있다.
E. OTA 플랫폼 최적화
OTA 플랫폼에 호텔 정보가 명확히 기입되어 있는지 확인한다. 숙박 시설 정책, 추가 요금, 위치 등을 상세하게 업데이트한다. 최소한 고객이 잘못된 정보에 의해 예약하고 취소하는 일은 없어야 한다.
이정도면 결론으로 충분하겠지? 내일은 이 데이터 다루었던 순서와 과정을 전반적으로 복습해야겠다!

전반적으로 예약 취소가 어떤 형태를 띄는지 파악할 수 있었어요! 제가 미처 파악하지 못했던 부분도 알게 돼서 좋았습니다.
예약 취소에 대한 일차적인 원인 파악은 어느정도 된 거 같은데요, 왜 이런 결과가 나왔는지에 대한 데이터 분석을 해보면 좋을 거 같아요! 그 원인이 어떻게 일어났는지, 그 원인을 발생시킨 주요 군집은 어디인지 등 계속 꼬리를 무는거죠. 예를 들어 PRT 국가는 데이터의 개수가 많은데도 불구하고 다른 나라보다 취소율이 확연히 높은 것을 알 수 있는데요, 왜 PRT국가가 다른 나라보다 취소율이 높을까? 라는 질문에 대한 데이터 분석도 해보는 것을 추천드려요!
그리고 글을 보면서 궁금한 게 생겼는데요. 연도별로 취소율이 높은 것을 볼 수 있었는데, 그럼 연도에 따른 월별 취소율은 어떻게 되나요? 추측상 동일하게 7-8월에 높으려나? 저는 연도별로 취소율이 높아지게 된 원인을 데이터 분석을 통해 찾아봐야겠네요!
개인적으로 seaborn의 regplot을 잘 활용하시는 거 인상 깊게 봤습니다!