seaborn에서 다양한 서브플롯 셋팅이 가능하다는 사실을 알았다. 서브타이틀까지 추가하니 꽤나 근사한 그래프가 나온다. 가독성은 더할 나위 없이 좋다. 역시 코드, 데이터 프레임, 그래프 뭐가 되었든 가독성이 가장 중요하다. 나만 이해할 수 있는 지식은 죽은 지식이다.
학습시간 09:00~01:00(당일16H/누적153H)
1. 오늘 깨달은 것
- rename으로 컬럼명을 쉽게 변경할 수 있다.
df.rename(columns={'assigned_room_type': 'room_type'}, inplace=True)- describe에 loc을 사용할 수 있다.
df.describe().loc[['mean', 'max']].T- 다중 그래프 출력에 서브타이틀을 꾸밀 수 있다.
fig, axes = plt.subplots(3, 1, figsize=(16, 8))
fig.suptitle('Yearly Canceled Reservation', fontsize=20, fontweight='bold')
sns.lineplot(data=df_2015, x='arrival_month', y='is_canceled', ax=axes[0], color='r')
axes[0].set_title('2015', fontsize=14, fontweight='black', loc='left', pad=-10,
bbox=dict(facecolor='white', edgecolor='black', boxstyle='square, pad=0.3'))
sns.lineplot(data=df_2016, x='arrival_month', y='is_canceled', ax=axes[1], color='g')
axes[1].set_title('2016', fontsize=14, fontweight='black', loc='left', pad=-10,
bbox=dict(facecolor='white', edgecolor='black', boxstyle='square, pad=0.3'))
sns.lineplot(data=df_2017, x='arrival_month', y='is_canceled', ax=axes[2], color='b')
axes[2].set_title('2017', fontsize=14, fontweight='black', loc='left', pad=-10,
bbox=dict(facecolor='white', edgecolor='black', boxstyle='square, pad=0.3'))- 중복값 카운트 시 조건을 걸 수 있다.
# 1. 모든 컬럼을 기준으로 중복 행 계산
df.value_counts()\
# 2. 중복 횟수를 'count' 컬럼에 저장
.reset_index(name='count')\
# 3. 중복 횟수가 1이상인 행만 필터링
.query("count > 1")\
# 4. 중복 횟수가 많은 순으로 내림차순
.sort_values(by='count', ascending=False)
2. 호텔 데이터 전처리 & 시각화
(1) 데이터 로드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option('display.max_columns', None)
df = pd.read_csv('hotel_data.csv')
df.info()라이브러리를 가져오고 칼럼이 다 보이도록 셋팅했다. 파일도 불러오고 바로 인포도 봤다. 한 번 해봐서 그런지 이제 주피터노트북 한 셀에 무엇을 적어야 할지 감이 잡힌다.
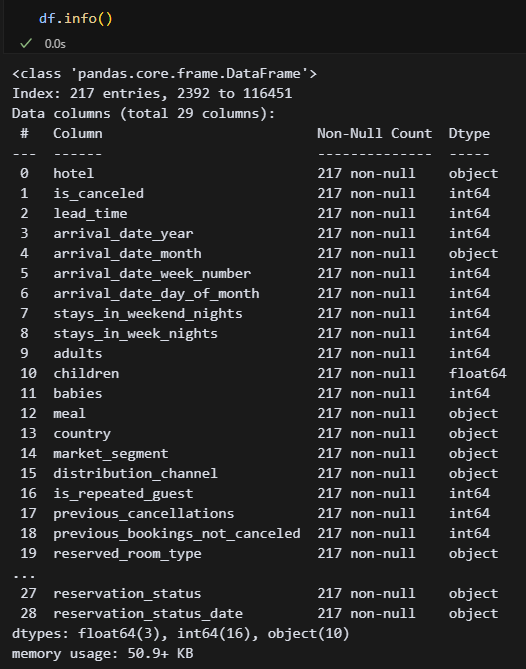 데이터 타입, 컬럼명을 간단히 확인한다. 모든 열이 다 안 나오기 때문에 그냥 116,451행과 29열로 이루어진 데이터라는 것을 보기 위한 작업이라고 보면 된다.
데이터 타입, 컬럼명을 간단히 확인한다. 모든 열이 다 안 나오기 때문에 그냥 116,451행과 29열로 이루어진 데이터라는 것을 보기 위한 작업이라고 보면 된다.
(2) 결측값 처리
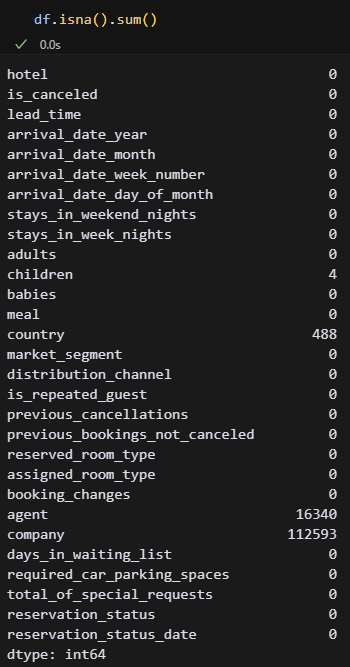 원래 isnull함수를 사용했는데, isna함수와 완전 동일한 함수라고 한다. 한 글자라도 덜 적기 위해 이제 isna를 쓰기로 했다. 일단 결측값이 어느 정도인지 확인했다.
원래 isnull함수를 사용했는데, isna함수와 완전 동일한 함수라고 한다. 한 글자라도 덜 적기 위해 이제 isna를 쓰기로 했다. 일단 결측값이 어느 정도인지 확인했다.
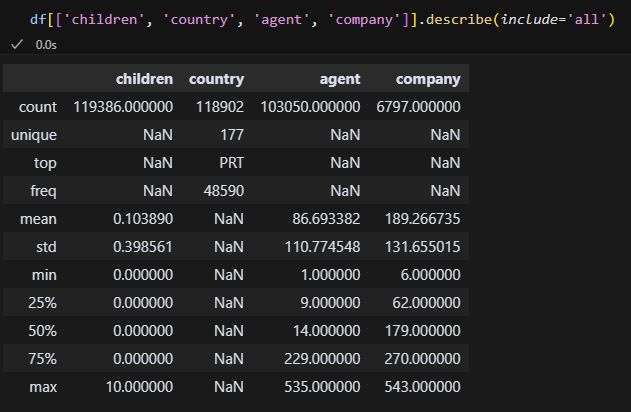 그리고 결측값이 존재하는 각 열마다 수치인지 문자인지 확인한다. 오 근데 이렇게는 처음 해본다. 원래 df.describe()로 모든 열을 봤는데, 내가 보고 싶은 열을 지정할 수도 있는 것 같다. 또 하나 배웠다.
그리고 결측값이 존재하는 각 열마다 수치인지 문자인지 확인한다. 오 근데 이렇게는 처음 해본다. 원래 df.describe()로 모든 열을 봤는데, 내가 보고 싶은 열을 지정할 수도 있는 것 같다. 또 하나 배웠다.
df[['children', 'country', 'agent', 'company']].dtypes
df['children'].fillna(0.0, inplace=True)
df['country'].fillna('OTH', inplace=True)
df['agent'].fillna(0.0, inplace=True)
df['company'].fillna(0.0, inplace=True)
df.isna().sum()dtype을 확인하며 결측값 4열을 채웠다. 그리고 isna로 재확인까지 했다. 이걸로 결측값 처리 끝이다. 처음 할 때보다 속도가 엄청나게 빨라졌다. 내가 뭘 해야하는지 이제는 정확히 알고 있기 때문일 듯하다.
(3) 중복값 처리
# 1. 모든 컬럼을 기준으로 중복 행 계산
df.value_counts()\
# 2. 중복 횟수를 'count' 컬럼에 저장
.reset_index(name='count')\
# 3. 중복 횟수가 1이상인 행만 필터링
.query("count > 1")\
# 4. 중복 횟수가 많은 순으로 내림차순
.sort_values(by='count', ascending=False)
중복값을 가지고 놀다가 알아낸 코드다. 중복 횟수가 특정 수치 이상인 것을 찾아낼 수 있다. 알아두면 언젠가 쓸모가 있겠지. 직관적이긴 한데 익숙하지가 않다. 그래도 저장해 놨다가 외워야지. 아차 그리고 \를 붙이면 줄바꿈해도 코드가 실행되는 걸 처음 알았다.
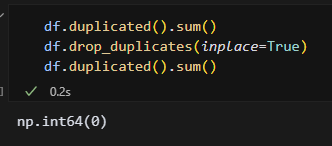 중복값을 드롭하고 재확인했다. 중복값 처리 끝! 필요 없는 데이터는 빨리 날려주고 다음 단계로 넘어가자!
중복값을 드롭하고 재확인했다. 중복값 처리 끝! 필요 없는 데이터는 빨리 날려주고 다음 단계로 넘어가자!
(4) 이상치 처리
df.drop(columns=[\
'lead_time',\
'arrival_date_week_number', \
'stays_in_weekend_nights', \
'stays_in_week_nights', \
'agent', \
'company', \
'distribution_channel', \
'reserved_room_type', \
'reservation_status'], \
inplace=True)필요없다고 판단한 9개의 컬럼을 드롭했다. 모바일 가독성을 위해 줄바꿈 후\를 함께 붙였다.
df['hotel'].unique()
df['meal'].unique()
df['country'].unique()
df['market_segment'].unique()
df['assigned_room_type'].unique()문자열로 이루어진 칼럼에 오타 없음을 확인했다. 아 근데 오타가 있어야 문자열 정제하는 연습을 하는데,,,
df.rename(columns={'assigned_room_type': 'room_type'}, inplace=True)
df.rename(columns={'reservation_status_date': 'reservation_date'}, inplace=True)
df.rename(columns={'days_in_waiting_list': 'waiting_days'}, inplace=True)
df.rename(columns={'previous_cancellations': 'previous_cancel'}, inplace=True)
df.rename(columns={'previous_bookings_not_canceled': 'previous_not_cancel'}, inplace=True)
df.rename(columns={'required_car_parking_spaces': 'parking_spaces'}, inplace=True)
df.rename(columns={'total_of_special_requests': 'special_requests'}, inplace=True)
df.columns 처음 했을 때 이름이 별로인 컬럼이 있었다. 이번엔 rename()함수를 찾아서 적용한다. 딕셔러니 형태로 변경하는 것 같다. 컬럼 이름이 마음에 드니까 데이터가 조금 더 잘 와닿는 느낌이다.
처음 했을 때 이름이 별로인 컬럼이 있었다. 이번엔 rename()함수를 찾아서 적용한다. 딕셔러니 형태로 변경하는 것 같다. 컬럼 이름이 마음에 드니까 데이터가 조금 더 잘 와닿는 느낌이다.
# July같은 월(문자)를 월(숫자)로 변환
df['arrival_date_month'] = pd.to_datetime(
df['arrival_date_month'], format='%B'
).dt.month
# 년월일 문자열로 더한 후 날짜형으로 변환
df['arrival_date'] = pd.to_datetime(
df['arrival_date_year'].astype(str) + '-' +
df['arrival_date_month'].astype(str).str.zfill(2) + '-' +
df['arrival_date_day_of_month'].astype(str).str.zfill(2)
)
df.drop(columns=[
'arrival_date_year',
'arrival_date_month',
'arrival_date_day_of_month'
], inplace=True)
날짜를 yyyy-mm-dd 형태로 합치고 재료로 사용한 컬럼은 드롭했다.
df['arrival_date'] = pd.to_datetime(df['arrival_date'])
df['reservation_date'] = pd.to_datetime(df['reservation_date'])
date 컬럼 2개를 datetime 포맷으로 변경했다.
df['arrival_year'] = df['arrival_date'].dt.year
df['arrival_month'] = df['arrival_date'].dt.month
df['arrival_day'] = df['arrival_date'].dt.strftime('%a')필요한 컬럼을 다시 만들었다. 근데 생각해 보니 이러면 애초에 삭제했던 4개의 재료 칼럼을 삭제할 필요 없는 거잖아...? 흠...
to_float = ['is_canceled',
'adults',
'children',
'babies',
'is_repeated_guest',
'previous_cancel',
'previous_not_cancel',
'booking_changes',
'waiting_days',
'parking_spaces',
'special_requests']
df[to_float] = df[to_float].astype(float)
df.dtypes어쨌든 수치열로 넘어와서, 이번에는 int 타입말고 float타입으로 변환해서 사용해 보려고 한다.
df['adults'] = df['adults'].where(df['adults'] <= 5, df['adults'].mode())
df['children'] = df['children'].where(df['children'] <= 3, df['children'].mode())
df['babies'] = df['babies'].where(df['babies'] <= 3, df['babies'].mode())
df.describe().loc[['mean', 'max']].T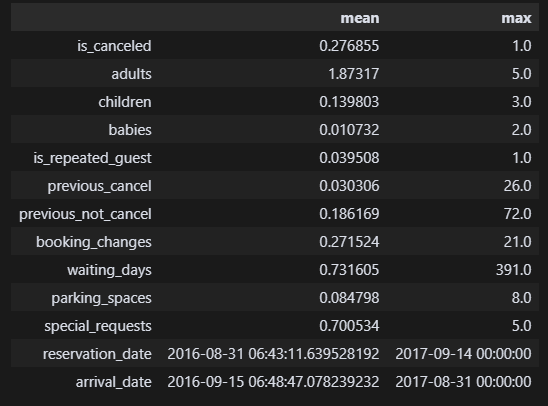 describe()함수에 loc[] 명령어를 추가하면 필요한 속성만 확인할 수 있다. 아주 좋다.
describe()함수에 loc[] 명령어를 추가하면 필요한 속성만 확인할 수 있다. 아주 좋다.
(5) 시각화
sns.set_theme(
rc={'figure.figsize':(15, 8)},
style='whitegrid',
font='Malgun Gothic',
font_scale=1,
palette='Set2'
)시각화에 들어가기 전에 seaborn을 먼저 셋팅했다. 이번에 팔레트는 Set2를 사용했다. 근데 팔레트 종류도 몇 개 정도는 외워야할 것 같다. 막상 기입하려니 생각나는 게 없다.
sns.heatmap(
df.corr(numeric_only=True), #숫자열만
annot=True, #각 셀에 값 표시
cmap='RdYlGn', #맵 색상 설정
vmin=-1, #최소값 설정
vmax=1, #최대값 설정
center=0, #중앙값 설정
square=True, #정사각형 모양
linewidths=.5, #셀 간의 경계선 두께
fmt='.2f', #소수점 2자리만
cbar_kws={'shrink': 1} #막대 크기
)히트맵을 먼저 보려고 셋팅했다. 이번에는 지난 번과 달리 히트맵 셋팅에 요소를 많이 추가했다. 히트맵 모양과 막대 크기도 설정할 수 있다. 진짜 이건 볼수록 만능인 것 같다. 코드만 알면 내 맘대로 할 수 있잖아??
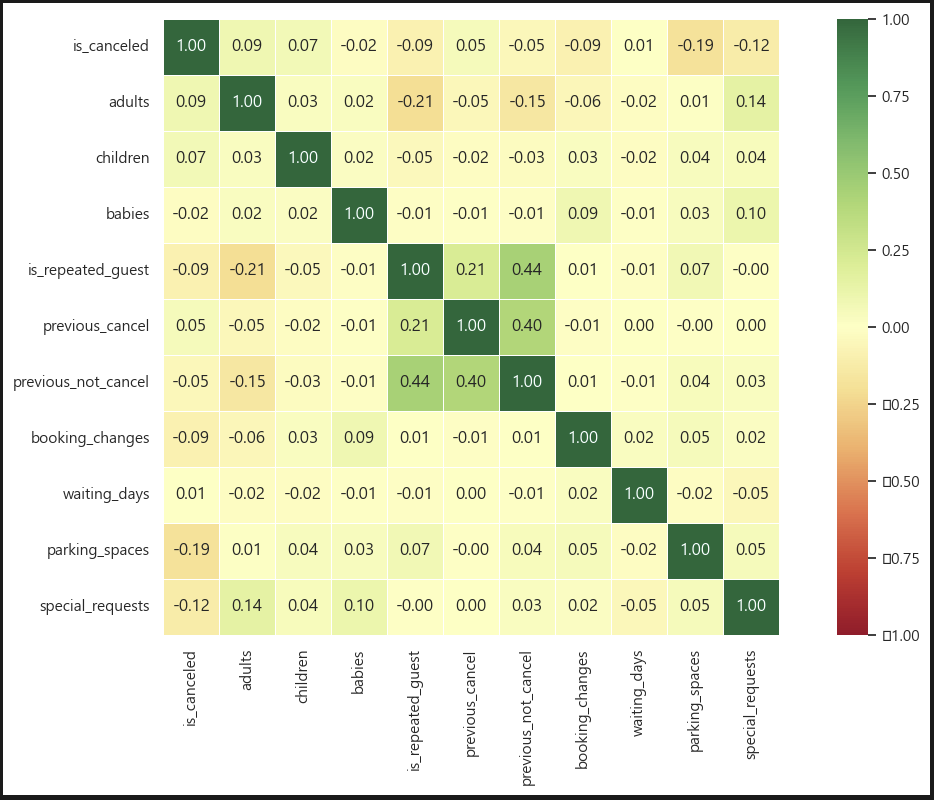 오 확실히 셋팅을 바꾸니 눈에 확 들어오는 것 같다! 초록색과 빨간색의 조합이라!
오 확실히 셋팅을 바꾸니 눈에 확 들어오는 것 같다! 초록색과 빨간색의 조합이라!
df_2015 = df[df['arrival_year'] == 2015]
df_2016 = df[df['arrival_year'] == 2016]
df_2017 = df[df['arrival_year'] == 2017]지난 번엔 3개년 데이터를 한 번에 봤는데, 이번엔 연도별로 나눠서 보려고 한다. 아! 근데 생각해 보니 어제 그래프 여러 개를 동시에 출력하는 법을 배웠다. 바로 써먹어 보자!
fig, axes = plt.subplots(3, 1, figsize=(12, 8))
fig.suptitle('Yearly Canceled Reservation', fontsize=20, fontweight='bold')
sns.barplot(data=df_2015, x='arrival_month', y='is_canceled', ax=axes[0], color='r')
axes[0].set_title('2015', fontsize=14, fontweight='bold', loc='left')
sns.barplot(data=df_2016, x='arrival_month', y='is_canceled', ax=axes[1], color='g')
axes[1].set_title('2016', fontsize=14, fontweight='bold', loc='left')
sns.barplot(data=df_2017, x='arrival_month', y='is_canceled', ax=axes[2], color='b')
axes[2].set_title('2017', fontsize=14, fontweight='bold', loc='left')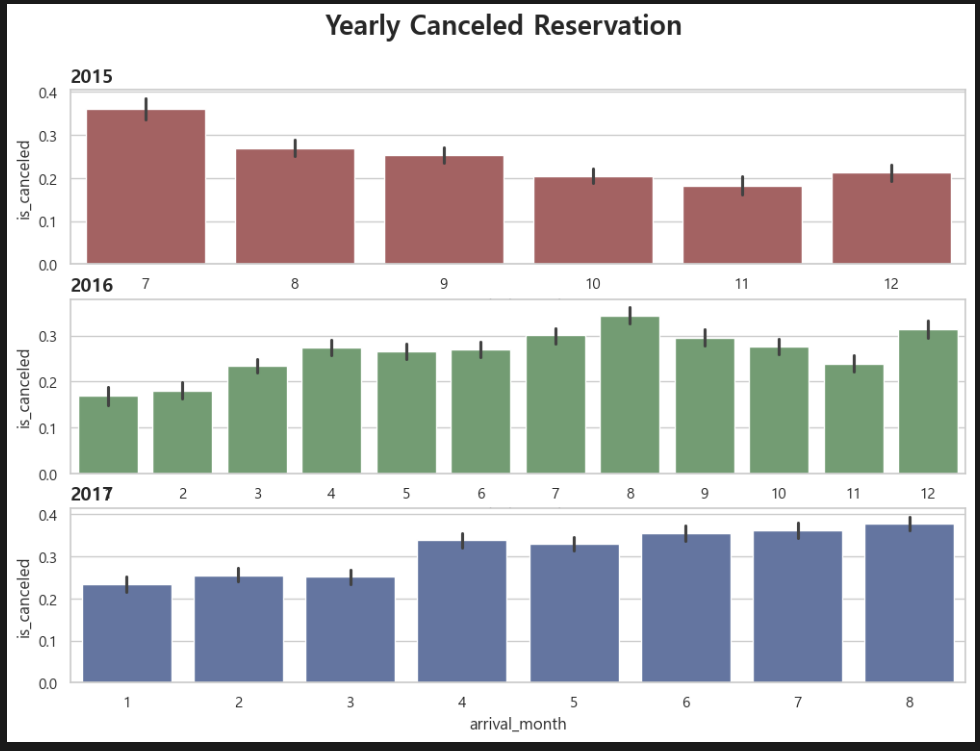 오!!! 한 화면에 3개가 나온다! 이 코드는 진짜 어떻게든 외워야겠다...
오!!! 한 화면에 3개가 나온다! 이 코드는 진짜 어떻게든 외워야겠다...
fig, axes = plt.subplots(3, 1, figsize=(16, 8))
fig.suptitle('Yearly Canceled Reservation', fontsize=20, fontweight='bold')
sns.lineplot(data=df_2015, x='arrival_month', y='is_canceled', ax=axes[0], color='r')
axes[0].set_title('2015', fontsize=14, fontweight='black', loc='left', pad=-10,
bbox=dict(facecolor='white', edgecolor='black', boxstyle='square, pad=0.3'))
sns.lineplot(data=df_2016, x='arrival_month', y='is_canceled', ax=axes[1], color='g')
axes[1].set_title('2016', fontsize=14, fontweight='black', loc='left', pad=-10,
bbox=dict(facecolor='white', edgecolor='black', boxstyle='square, pad=0.3'))
sns.lineplot(data=df_2017, x='arrival_month', y='is_canceled', ax=axes[2], color='b')
axes[2].set_title('2017', fontsize=14, fontweight='black', loc='left', pad=-10,
bbox=dict(facecolor='white', edgecolor='black', boxstyle='square, pad=0.3'))배운 코드를 조금 더 응용했다. 색상은 딱히 생각나는 게 없어서 RGB를 한 글자씩 넣었는데 우연히 잘 작동한다. 확실히 bar 수량이 많으면 barplot보다는 lineplot이 눈에 확 들어오는 것 같다. 서브타이틀 꾸미는 코드를 추가했더니 조금 더 느낌이 산다.
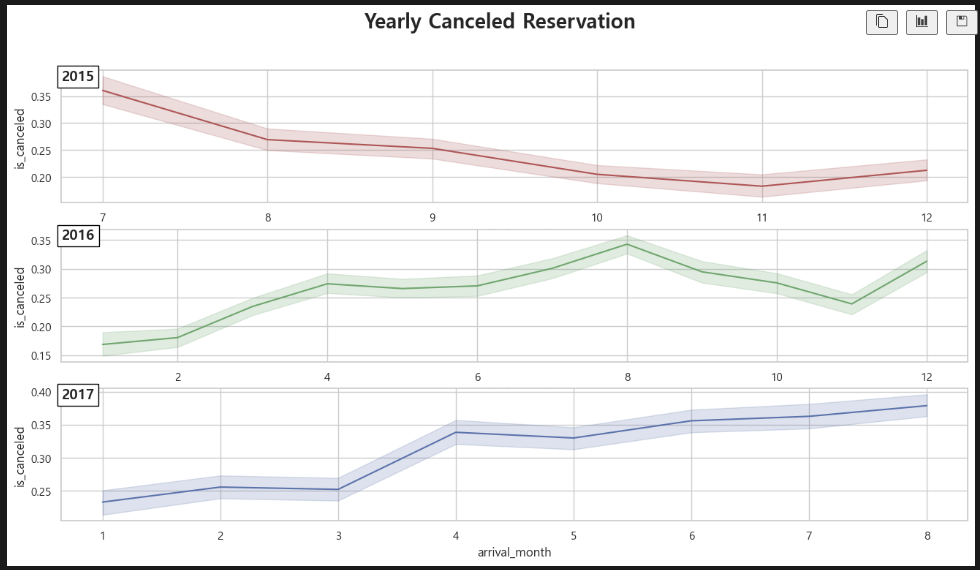 연도별로 나누어 보아도 여름 취소율이 가장 높다.
연도별로 나누어 보아도 여름 취소율이 가장 높다.
group_2015 = df_2015[df_2015['market_segment'] == 'Groups']
corporate_2015 = df_2015[df_2015['market_segment'] == 'Corporate']
direct_2015 = df_2015[df_2015['market_segment'] == 'Direct']
ota_2015 = df_2015[df_2015['market_segment'] == 'Online TA']
group_2016 = df_2016[df_2016['market_segment'] == 'Groups']
corporate_2016 = df_2016[df_2016['market_segment'] == 'Corporate']
direct_2016 = df_2016[df_2016['market_segment'] == 'Direct']
ota_2016 = df_2016[df_2016['market_segment'] == 'Online TA']
group_2017 = df_2017[df_2017['market_segment'] == 'Groups']
corporate_2017 = df_2017[df_2017['market_segment'] == 'Corporate']
direct_2017 = df_2017[df_2017['market_segment'] == 'Direct']
ota_2017 = df_2017[df_2017['market_segment'] == 'Online TA']이번엔 세그먼트 4개를 3개년으로 나눴다. 과연 이것도 한 그래프로 합칠 수 있을까!?
fig, axes = plt.subplots(4, 1, figsize=(12, 8))
fig.suptitle('2015 Canceled by Market Segment', fontsize=20, fontweight='bold')
sns.lineplot(data=group_2015, x='arrival_month', y='is_canceled', ax=axes[0], color='r')
axes[0].set_title('2015 Group', fontsize=14, fontweight='bold', loc='left')
sns.lineplot(data=corporate_2015, x='arrival_month', y='is_canceled', ax=axes[1], color='g')
axes[1].set_title('2015 Corporate', fontsize=14, fontweight='bold', loc='left')
sns.lineplot(data=direct_2015, x='arrival_month', y='is_canceled', ax=axes[2], color='b')
axes[2].set_title('2015 Direct', fontsize=14, fontweight='bold', loc='left')
sns.lineplot(data=ota_2015, x='arrival_month', y='is_canceled', ax=axes[3], color='y')
axes[3].set_title('2015 OTA', fontsize=14, fontweight='bold', loc='left')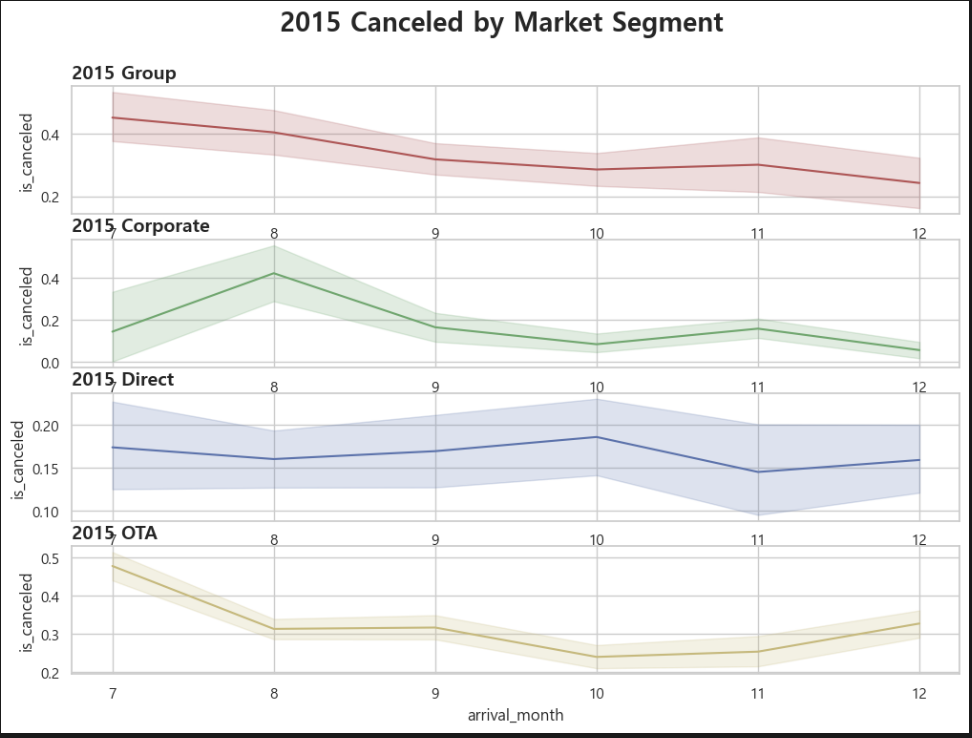 와! 나온다! 2015년!
와! 나온다! 2015년!
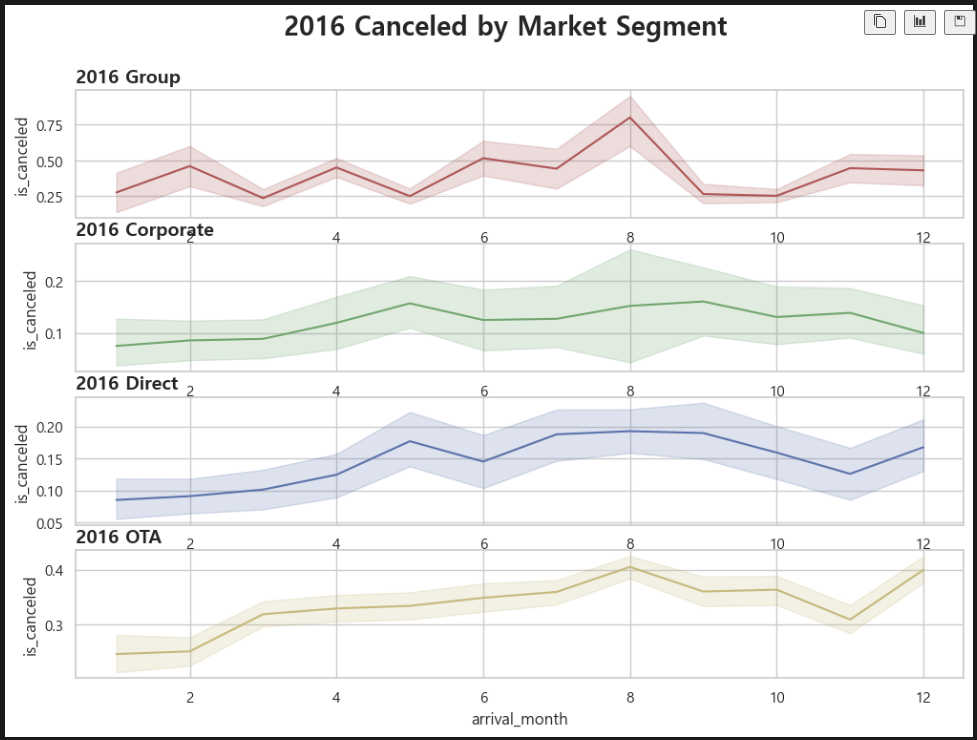 2016년!
2016년!
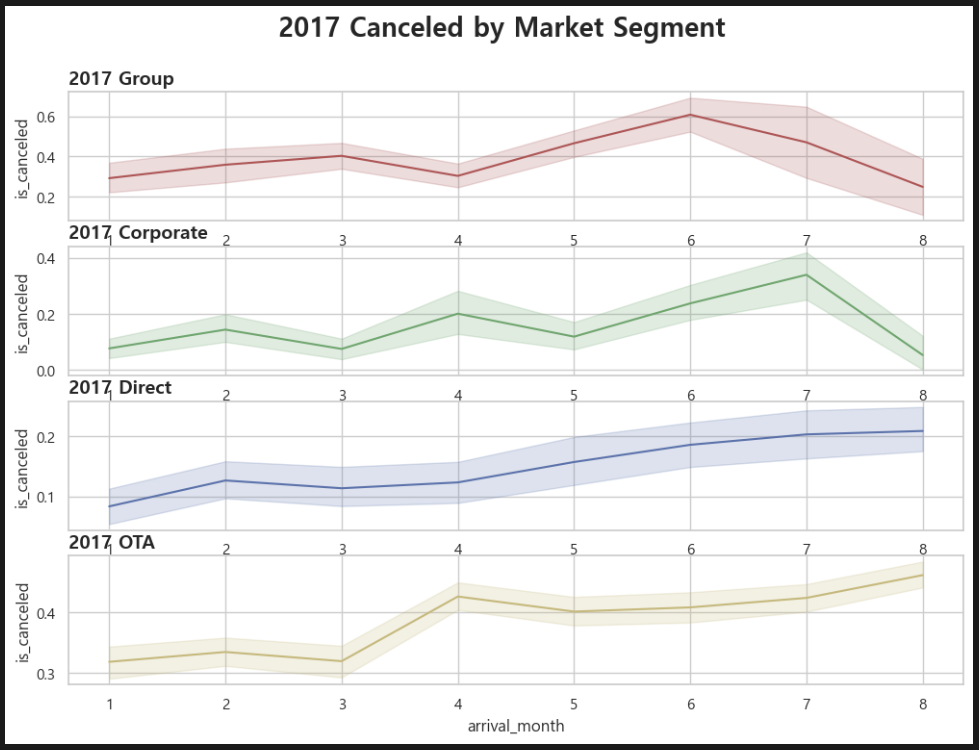 2017년!
2017년!
연도별로 나누어서 보니,
2015년: OTA > Group > Corporate > Direct
2016년: OTA > Group > Corporate > Direct
2017년: OTA > Group > Corporate > Direct
3개년 모두 동일 순서로 취소율 절대값이 높다.
오늘의 결론 또한 어제와 같다. 이 호텔이 취소율을 낮추어 매출을 높이기 위해서는, OTA 예약 건과 단체행사 예약 건에 대한 취소 규정을 다소 조정할 필요가 있다.
이정도면 데이터 전처리 입문은 한 것 같다. 이제 머신러닝으로 가보자! 즐거운 시간이었습니다 seaborn!
