일단 지도 학습의 전반적인 단계는 파악한 것 같다. 모델 구현하는 원리도 이제 감이 잡힌다. 관건은 최적화인데, 이건 하다 보면 되리라 믿는다.
학습시간 09:00~00:00(당일15H/누적229H)
◆ 오늘 깨달은 것
-
데이터 스플릿 할 때는 X_train, y_train 이 순서로 하면 안 된다. 무조건 X_train, X_test, y_train, y_test 순서로!
-
종속변수가 없는 데이터는 예측값과 실제값의 차이를 확인할 수 없기 때문에 R2 스코어가 0일 수밖에 없다.
-
종속변수를 로그변환했을 때 더 좋은 모델이 되는 경우가 있다.
◆ 자전거 대여 예측 모델
1. 데이터 전처리
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_train.head()
df_test.head() 데이터 전처리는 지난 주와 별 다를 게 없을 것 같다.
데이터 전처리는 지난 주와 별 다를 게 없을 것 같다.
- datetime을 4개 컬럼(year, month, day, dayofweek)으로 나눈다.
- casual, registered열 드롭 후 count열만 남긴다.
- temp와 atemp는 사실상 동일하니 체감온도도 드롭한다.
- 두 파일 모두 동일하게 만든다.
df_train.drop(columns=['casual', 'registered'], inplace=True)
df_test['count'] = ''
 casual, registered열을 지우고 count열만 남겼다.
casual, registered열을 지우고 count열만 남겼다.
df_train['year'] = pd.to_datetime(df_train['datetime']).dt.year
df_train['month'] = pd.to_datetime(df_train['datetime']).dt.month
df_train['day'] = pd.to_datetime(df_train['datetime']).dt.day
df_train['dayofweek'] = pd.to_datetime(df_train['datetime']).dt.dayofweek
df_train['hour'] = pd.to_datetime(df_train['datetime']).dt.hour
df_train.drop(columns=['atemp'], inplace=True)
df_train.drop(columns=['datetime'], inplace=True)
df_test['year'] = pd.to_datetime(df_test['datetime']).dt.year
df_test['month'] = pd.to_datetime(df_test['datetime']).dt.month
df_test['day'] = pd.to_datetime(df_test['datetime']).dt.day
df_test['dayofweek'] = pd.to_datetime(df_test['datetime']).dt.dayofweek
df_test['hour'] = pd.to_datetime(df_test['datetime']).dt.hour
df_test.drop(columns=['atemp'], inplace=True)
df_test.drop(columns=['datetime'], inplace=True)
df_train.head()
깔끔하다. 이제 dtype을 보자.
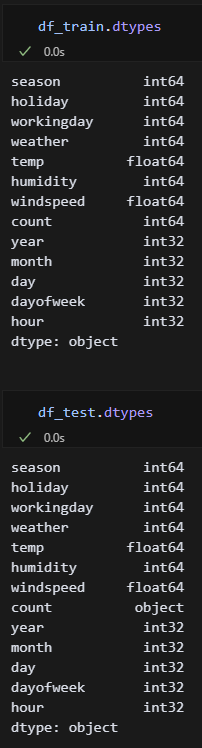 dtype확인. test파일은 count가 object로 되어있어서 int로 변경해야겠다.
dtype확인. test파일은 count가 object로 되어있어서 int로 변경해야겠다.
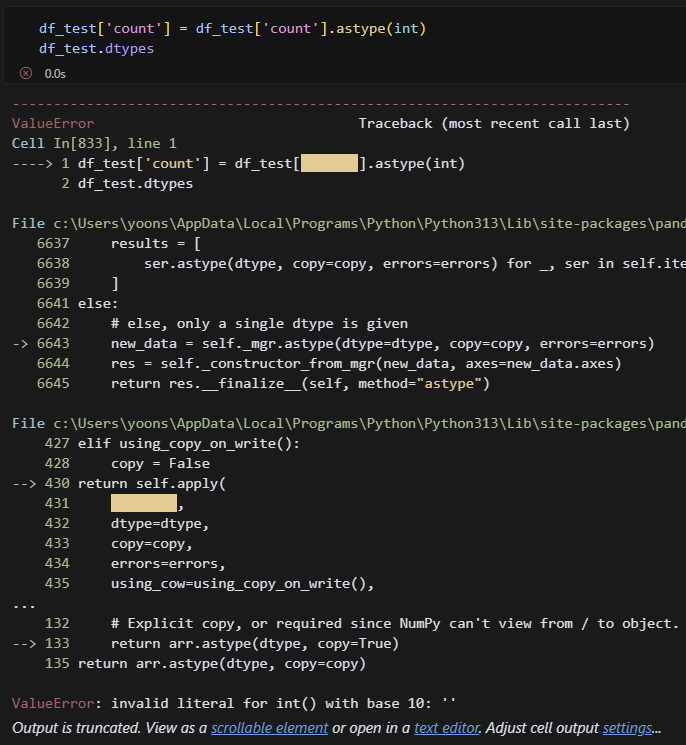 에러가 떳다. 아, df_test의 count열을 숫자가 아니라 공백으로 넣어서 그런가?
에러가 떳다. 아, df_test의 count열을 숫자가 아니라 공백으로 넣어서 그런가?
df_test['count'] = '0'공백대신 0으로 채워줌.
 int로 변경됐다.
int로 변경됐다.
이제 중복값 처리할 차례다.
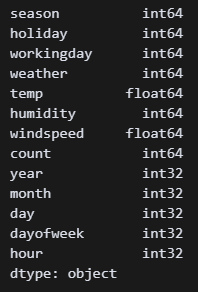
print(df_train.isnull().sum())
df_train.drop_duplicates(inplace=True)
print(df_train.duplicated().sum())
print('--------------')
print(df_test.isnull().sum())
df_test.drop_duplicates(inplace=True)
print(df_test.duplicated().sum())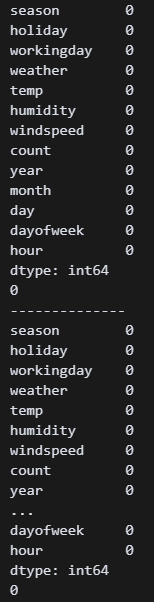 두 파일 모두 중복값이 소량 있어 처리했다.
두 파일 모두 중복값이 소량 있어 처리했다.
df_train.describe().loc[['mean', 'std', 'min', 'max']].T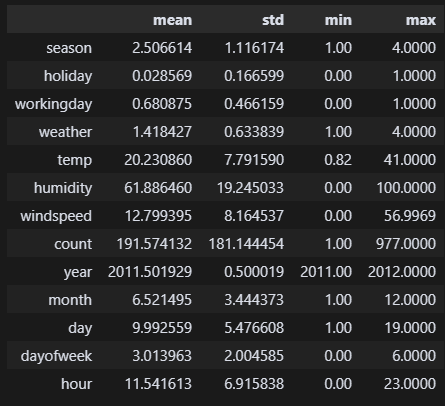 풍속 56m/s이 여전히 걸린다. 일단 이번에는 그냥 두고 진행해봐야겠다.
풍속 56m/s이 여전히 걸린다. 일단 이번에는 그냥 두고 진행해봐야겠다.
2. 상관관계 분석
sns.heatmap(df_train.corr(), annot=True, fmt='.1f')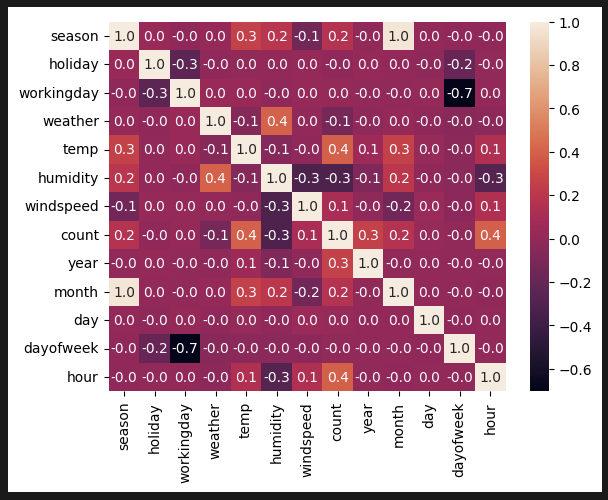 히트맵 분석. 온도, 습도, 계절, 시간과 큰 연관이 있다.
히트맵 분석. 온도, 습도, 계절, 시간과 큰 연관이 있다.
sns.lineplot(data=df_train, x='hour', y='count', hue='workingday')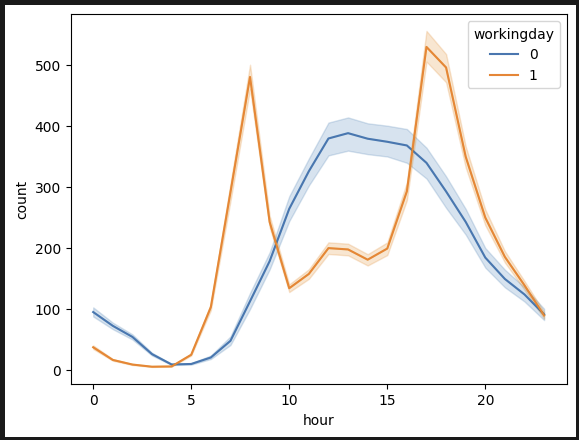
시간별 분석. 근무일엔 출퇴근 시간(8시, 18시)에 몰린다. 휴무일엔 12시~17시에 몰린다.
sns.lineplot(data=df_train, x='temp', y='count', hue='workingday')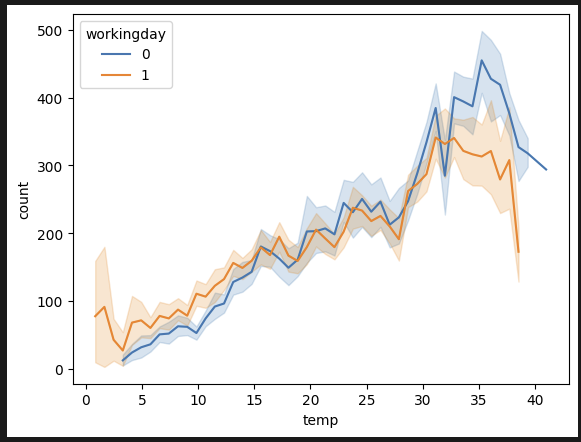 기온별 분석. 근무일 관계없이 30~37도 정도에 대여량이 많다. 휴무일에는 조금 더워도 나가서 노는 경향이 있는 듯하다.
기온별 분석. 근무일 관계없이 30~37도 정도에 대여량이 많다. 휴무일에는 조금 더워도 나가서 노는 경향이 있는 듯하다.
sns.lineplot(data=df_train, x='humidity', y='count', hue='workingday')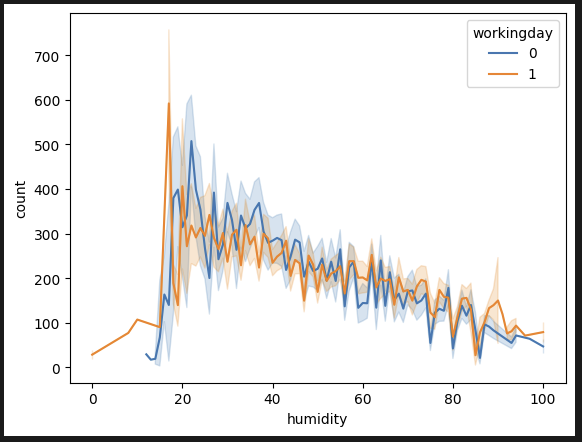 습도별 분석. 습도 20~30% 정도에 대여량이 많다.
습도별 분석. 습도 20~30% 정도에 대여량이 많다.
sns.lineplot(data=df_train, x='month', y='count', hue='workingday')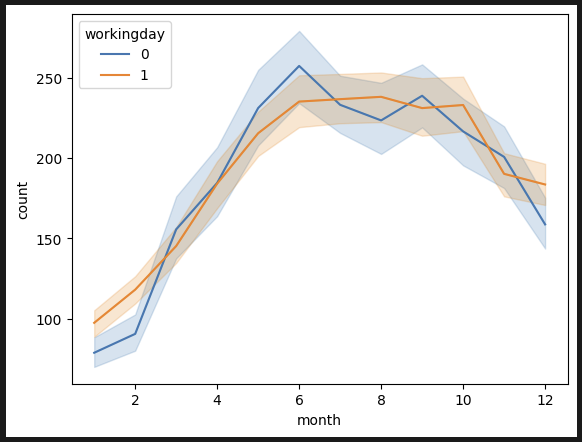 계절별 분석. 1분기(봄)에는 대여량이 별로 없다.
계절별 분석. 1분기(봄)에는 대여량이 별로 없다.
sns.barplot(data=df_train, x='dayofweek', y='count', errorbar=None)
sns.barplot(data=df_train, x='workingday', y='count', errorbar=None)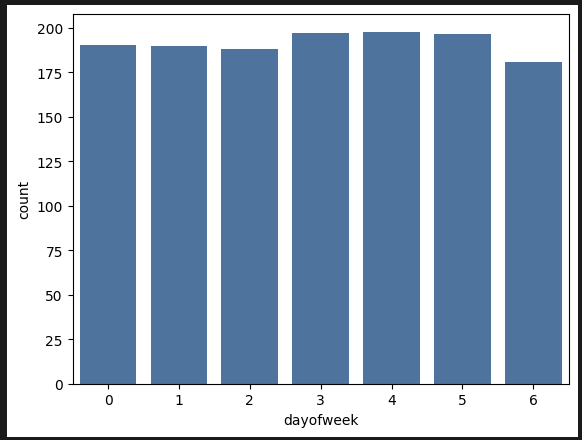
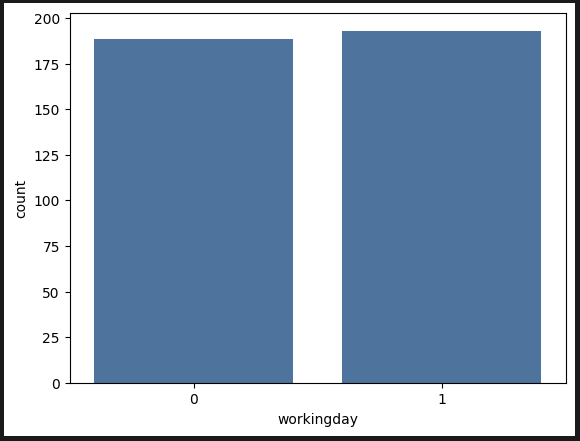 요일별, 휴무일, 근무일에 따른 대여량 차이가 크게 없다.
요일별, 휴무일, 근무일에 따른 대여량 차이가 크게 없다.
중요한 지표는 다 나온 듯하다.
- 근무일엔 출퇴근 시간(8시, 18시)에 몰린다. 휴무일엔 12시~17시에 몰린다.
- 근무일 관계없이 30~37도 정도에 대여량이 많다.
- 근무일 관계없이 습도 20~30% 정도에 대여량이 많다.
- 1분기(봄)엔 대여량이 적고 그 외 대여량이 약 2배 높다.
- 요일별, 휴무일, 근무일에 따른 대여량 차이가 크게 없다.
3. 데이터 스플릿
X_train = df_train.drop(columns=['count'])
y_train = df_train['count']
X_test = df_test.drop(columns=['count'])
y_test = df_test['count']데이터를 나눴다. 원래 train_test_split 함수를 사용해서 test_size와, random_state를 설정하며 나눴는데, 파일이 이미 2개로 분리되어 있는 상태니까 이렇게 진행했다. 이게 맞겠지..?
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=3)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
from sklearn.preprocessing import StandardScaler
scl = StandardScaler()
X_train_scl = scl.fit_transform(X_train_poly)
X_test_scl = scl.transform(X_test_poly)3차식으로 변환 후 스케일링을 돌렸다. 지난 번처럼 scl.fit_ 를 두 번 사용하는 실수를 범하지 않도록 더블체크 했다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train_scl, y_train)y_train_pred = lr.predict(X_train_poly)
y_test_pred = lr.predict(X_test_poly)일반 선형회귀 모델에 학습시켰다. 제발 잘 예측해주길...ㅠㅠ!!
4. 모델 평가
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print("Train set metrics")
print("MAE:", mean_absolute_error(y_train, y_train_pred))
print("MSE:", mean_squared_error(y_train, y_train_pred))
print("RMSE:", mean_squared_error(y_train, y_train_pred) ** 0.5)
print("R2 Score:", r2_score(y_train, y_train_pred))
print("--------------------------------")
print("Test set metrics")
print("MAE:", mean_absolute_error(y_test, y_test_pred))
print("MSE:", mean_squared_error(y_test, y_test_pred))
print("RMSE:", mean_squared_error(y_test, y_test_pred) ** 0.5)
print("R2 Score:", r2_score(y_test, y_test_pred))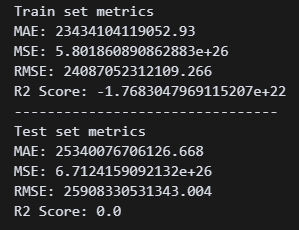 일단 모델이 만들어지긴 했는데, 지표가 엉망이다. 수치가 왜이렇게 높지..?
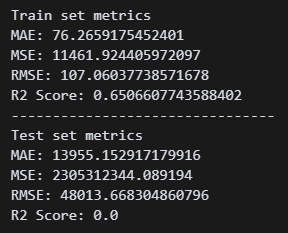
일단 모델이 만들어지긴 했는데, 지표가 엉망이다. 수치가 왜이렇게 높지..?
 ㅎㅎㅎ 스케일링 해놓고 사용하지 않았다고 한다.
ㅎㅎㅎ 스케일링 해놓고 사용하지 않았다고 한다.
y_train_pred = lr.predict(X_train_scl)
y_test_pred = lr.predict(X_test_scl)다시 예측 실시!!
 아까보단 나은 것 같은데, RMSE 수치가 48000이다 ㅋㅋㅋㅋ 3차식 말고 2차식으로 해야하나?
아까보단 나은 것 같은데, RMSE 수치가 48000이다 ㅋㅋㅋㅋ 3차식 말고 2차식으로 해야하나?
poly = PolynomialFeatures(degree=2)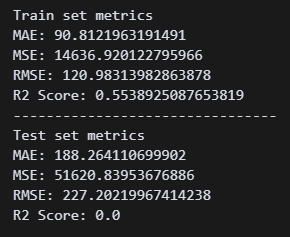 오 아까보다 훨씬 좋은 점수가 나왔다. 근데 왜 R2 스코어는 0점이지..?
오 아까보다 훨씬 좋은 점수가 나왔다. 근데 왜 R2 스코어는 0점이지..?
도와줘여 지선생...
 아직도 과적합 상태구나. 그럼 차원을 낮추고 일반 선형회귀 대신 릿지회귀로 모델로 해야하나..?
아직도 과적합 상태구나. 그럼 차원을 낮추고 일반 선형회귀 대신 릿지회귀로 모델로 해야하나..?
poly = PolynomialFeatures(degree=1)1차식으로 변경했다
-> 실패
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=10.0)
ridge.fit(X_train_scl, y_train)
y_train_pred_ridge = ridge.predict(X_train_scl)
y_test_pred_ridge = ridge.predict(X_test_scl)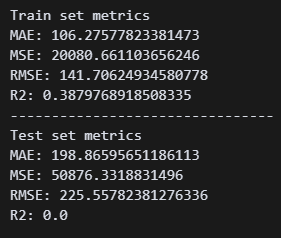 릿지 회귀를 사용했다.
릿지 회귀를 사용했다.
-> 실패
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=10.0)
lasso.fit(X_train_scl, y_train)
y_train_pred_lasso = lasso.predict(X_train_scl)
y_test_pred_lasso = lasso.predict(X_test_scl)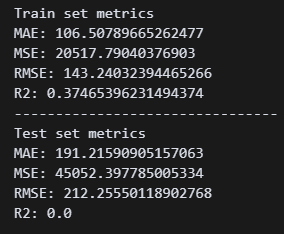 라쏘 회귀 사용.
라쏘 회귀 사용.
-> 실패
 아 계수가 높은 피처만 들고가는 거였어?
아 계수가 높은 피처만 들고가는 거였어?
-> 실패.
이후로도,,,
-> 실패 -> 실패 -> 실패 -> 실패 -> 실패 -> 실패 -> 실패 -> 실패 -> 실패
그리고 결국,,, 원인을 찾아냈다. 종속변수가 없는 데이터이기 때문에 예측값과 실제값의 차이를 확인할 수가 없는 것. 그래서 R2 스코어가 0일 수밖에 없는 것.
 그렇다는 건, 일단 내가 모델 만들기에는 성공했다는 뜻일 것이다.
그렇다는 건, 일단 내가 모델 만들기에는 성공했다는 뜻일 것이다.
from sklearn.metrics import mean_squared_error
import numpy as np
# Train set metrics
print("Train set metrics")
print("MSE:", mean_squared_error(y_train, y_train_pred))
print("RMSE:", mean_squared_error(y_train, y_train_pred) ** 0.5)
print("RMSLE:", np.sqrt(np.mean((np.log1p(y_train) - np.log1p(y_train_pred)) ** 2)))
print("------------------")
print("Test set metrics")
print("MSE:", mean_squared_error(y_test, y_test_pred))
print("RMSE:", mean_squared_error(y_test, y_test_pred) ** 0.5)
print("RMSLE:", np.sqrt(np.mean((np.log1p(y_test) - np.log1p(y_test_pred)) ** 2)))
내가 구해야 하는 RMSLE 지표를 추가했다.
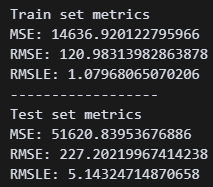 테스트셋 RMSLE는 5.1정도다. 조금 더 낮출 수 있으면 좋겠는데,,
테스트셋 RMSLE는 5.1정도다. 조금 더 낮출 수 있으면 좋겠는데,,
5. 모델개선
RMSLE 수치를 낮추기 위해 여러 방법을 시도해 보자.
from sklearn.linear_model import Ridge
model = Ridge()
model.fit(X_train_scl, y_train)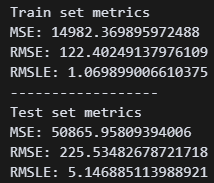 릿지, 라쏘, 엘라스틱넷 다 해봤는데 릿지가 가장 수치가 좋았다. 그래도 일반 선형회귀보다는 0.003 정도 높다
릿지, 라쏘, 엘라스틱넷 다 해봤는데 릿지가 가장 수치가 좋았다. 그래도 일반 선형회귀보다는 0.003 정도 높다
from sklearn.linear_model import SGDRegressor
model = SGDRegressor()
model.fit(X_train_scl, y_train)
print(model.n_iter_)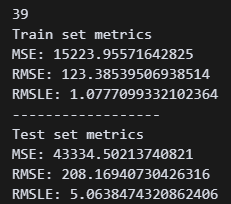
확률적 경사하강법을 진행했다. 39회 반복 후 RMSLE 5.06이 됐다. 현재까지 한 것 중에 가장 낮은 수치다.
from sklearn.linear_model import SGDRegressor
model = SGDRegressor(loss='huber', max_iter=5000)
model.fit(X_train_scl, y_train)
print(model.n_iter_)팀원으로부터 y를 로그로 변환하면 조금 더 개선된다는 정보를 얻었다.
''' 확률적 경사하강법 + 로그변환 모델 '''
# y값을 log1p로 변환
y_train_log = np.log1p(y_train)
y_test_log = np.log1p(y_test)
from sklearn.linear_model import SGDRegressor
model = SGDRegressor(random_state=20)
model.fit(X_train_scl, y_train_log)
print(model.n_iter_)
y_train_pred_log = model.predict(X_train_scl)
y_test_pred_log = model.predict(X_test_scl)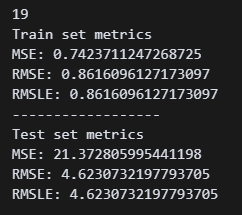 4.62까지 내려왔다!
4.62까지 내려왔다!
이번엔 서포트 벡터 모델!
y_train_log = np.log1p(y_train)
y_test_log = np.log1p(y_test)
from sklearn.svm import SVR
svr_model = SVR(kernel='rbf', C=1.0, epsilon=1)
svr_model.fit(X_train_scl, y_train_log)
y_train_pred_log_svr = svr_model.predict(X_train_scl)
y_test_pred_log_svr = svr_model.predict(X_test_scl)kernel='rbf' 이걸 설정해 주는 게 핵심인 것 같다.
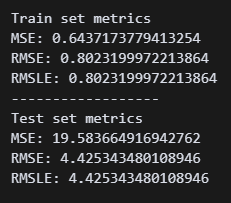 4.42!! 아무래도 내가 할 수 있는 건 이게 한계다..
4.42!! 아무래도 내가 할 수 있는 건 이게 한계다..
6. 마치며
(1). 데이터 요약
특정 시간대의 자전거 대여 패턴
- 근무일엔 출퇴근 시간(8시, 18시)에 몰린다. 휴무일엔 12시~17시에 몰린다.
날씨와 자전거 대여 수요 간의 상관관계
- 근무일 관계없이 30~37도 정도에 대여량이 많다.
- 근무일 관계없이 습도 20~30% 정도에 대여량이 많다.
계절별 자전거 대여 패턴의 차이
- 1분기(봄)엔 대여량이 적고 그 외 대여량이 약 2배 높다.
주말과 평일의 자전거 대여 수요 차이
- 요일별, 휴무일, 근무일에 따른 대여량 차이가 크게 없다.
자전거 대여 수요를 예측하기 위해 사용할 수 있는 가장 중요한 변수
- 시간대, 기온, 습도, 계절
(2). 운영 전략
A. 시간대별 자전거 집중 배치
- 근무일: 오전 7:30 이전, 오후 17:30 이전에 주요 지점에 자전거 충분히 배치
- 휴무일: 12시~17시 수요 대비해 도심 관광지나 공원 근처에 배치 강화
B. 날씨 기반 실시간 모니터링 운영
- 기온이 30~37도, 습도 20~30% 예상 시 → 수요 급증 사전 예고
- 해당 조건이 충족되면 자동으로 자전거를 인기 지점으로 재배치하는 시스템 도입 고려
C. 계절별 재배치 정책 조정
- 봄(1분기)엔 수요가 절반이므로 유휴 자전거 점검, 정비 집중 시기로 활용
D. 수요 예측 핵심 변수 기반 AI 모델 강화
- 시간, 기온, 습도, 계절만으로도 예측 정확도가 높으므로 단순하고 빠른 예측 모델 구축 가능
- 이를 통해 수요 폭증 시간대 실시간 알림 및 배차 자동화 가능성 확보
7. 마지막 재도전
test셋의 종속변수가 없어서 RMSLE 수치를 제대로 확인할 수 없다고 한다. 그렇다는 건 내가 지금까지 제대로 했다는 것이다. train셋 수치만 보면 되고 그럼 0.8이다. 지선생과 함께 하이퍼 파라미터 튜닝까지 진행해보자!
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_log_error
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# 1. 다항식 변환 (degree=2)
poly = PolynomialFeatures(degree=2)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
# 2. 스케일링
scl = StandardScaler()
X_train_scl = scl.fit_transform(X_train_poly)
X_test_scl = scl.transform(X_test_poly)
# 3. 기본 모델 학습 (baseline)
m = SVR(kernel='rbf', C=1.0, epsilon=1)
m.fit(X_train_scl, y_train_log)
# 4. 예측 및 RMSLE 평가
y_train_pred = np.expm1(m.predict(X_train_scl))
print("▶ Baseline Train RMSLE:", np.sqrt(mean_squared_log_error(y_train, y_train_pred)))2차식으로 변환, 서포트벡터로 진행,
 0.78이 나왔다.
0.78이 나왔다.
# 5. 랜덤서치용 하파 분포 설정
param_dist = {
'C': uniform(0.1, 100),
'epsilon': uniform(0.1, 1),
'gamma': ['scale', 'auto']
}
# 6. 랜덤서치 실행
random_search = RandomizedSearchCV(
SVR(kernel='rbf'),
param_distributions=param_dist,
n_iter=10,
scoring='neg_mean_squared_log_error',
cv=3,
verbose=1,
random_state=42
)
random_search.fit(X_train_scl, y_train_log)랜덤서치로 하이퍼 파라미터를 튜닝한다.
# 7. 최고 성능 출력
print("Best params:", random_search.best_params_)
print("Best CV RMSLE:", np.sqrt(-random_search.best_score_))
# 8. 전체 결과 테이블 출력
cv_results = pd.DataFrame(random_search.cv_results_)
cv_results = cv_results.sort_values(by='mean_test_score', ascending=False)
print("\n전체 실험 결과 (상위 5개):")
print(cv_results[['params', 'mean_test_score']].head())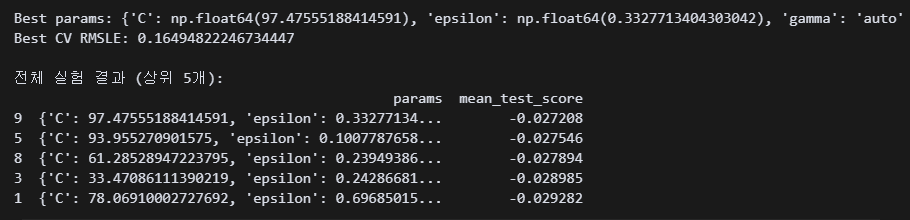 5분 정도 돌리니 베스트 하파값이 나왔다. C가 97.48, 엡실론0.33, 감마 오토라고 한다.
5분 정도 돌리니 베스트 하파값이 나왔다. C가 97.48, 엡실론0.33, 감마 오토라고 한다.
# 9. 베스트 모델 재학습
best_svr = SVR(kernel='rbf', C=97.48, epsilon=0.33, gamma='auto')
best_svr.fit(X_train_scl, y_train_log)
# 10. 재예측
y_train_pred = np.expm1(best_svr.predict(X_train_scl))
y_test_pred = np.expm1(best_svr.predict(X_test_scl))
# 11. RMSLE 계산
from sklearn.metrics import mean_squared_log_error
print("▶ Best Train RMSLE:", np.sqrt(mean_squared_log_error(y_train, y_train_pred)))다시 넣고 돌림
 끝.
끝.
세 번재 미션도 어찌어찌 완료다...
