데이터 전처리는 하면 할수록 실력이 느는 것 같다. 함수로 반복작업을 자동화 하는 게 재밌는데, 시간이 오래 걸려서 문제다.
학습시간 09:00~01:00(당일16H/누적261H)
◆ 오늘의 깨달음
-
레이블 인코딩(map)과 원핫 인코딩(get_dummies)은 다르다!
df['y'] = df['y'].map({'no': 0, 'yes': 1})
pd.get_dummies(df['job'], drop_first=True) -
데이터 로드 시 추가할 수 있는 기능이 꽤 많다.
-
CatBoost랑 LightGBM에는 카테고리 타입을 자동으로 변환하는 기능이 있다.
◆ 학습내용
예금 가입자 예측 모델 구현
이번 미션도 화이팅이다!
1. 데이터 전처리
이 녀석 어떻게 생겼나 먼저 함 보자.
df = pd.read_csv('bank-additional-full.csv')
df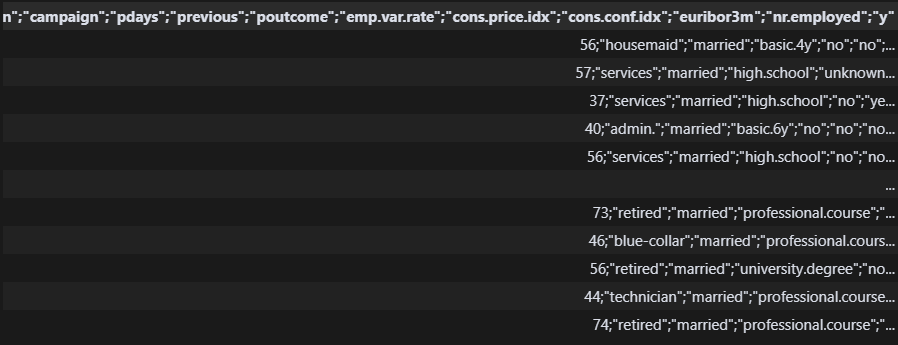 ?????????? 뭐야? 컬럼 분리가 안 되어 있다.
?????????? 뭐야? 컬럼 분리가 안 되어 있다.
데이터 로드 시 기능을 추가해야 한다고 한다. 자세히 보니 세미콜론이 분기점인 것 같다.
df = pd.read_csv('bank-additional-full.csv', sep=';')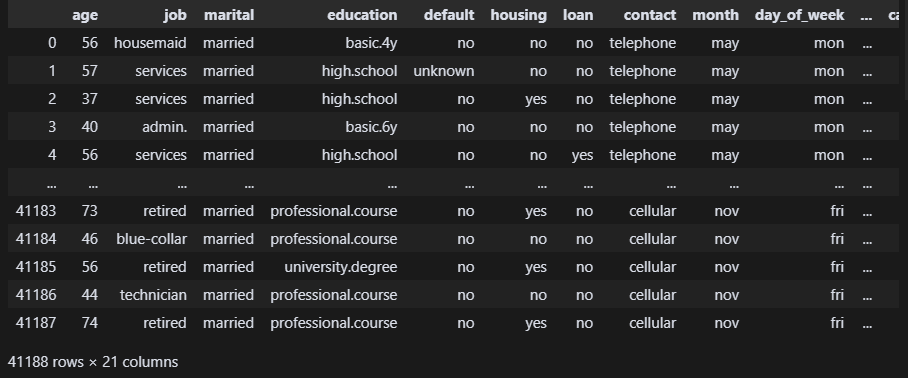 잘 나온다. 범주형과 수치형이 반반정도 섞여 있다.
잘 나온다. 범주형과 수치형이 반반정도 섞여 있다.
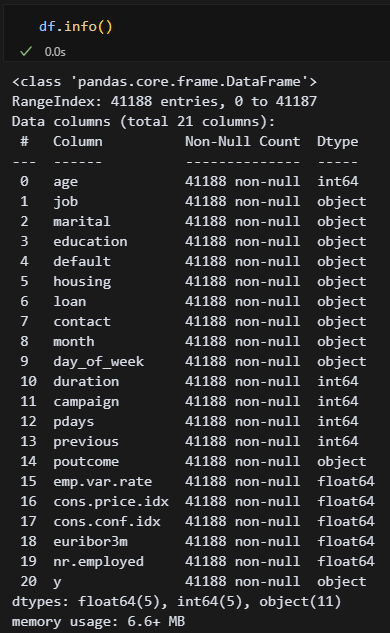 결측값은 없는 것 같다. 근데 오브젝트가 많아서 문자열 처리할 때 골치아플 것 같네..
결측값은 없는 것 같다. 근데 오브젝트가 많아서 문자열 처리할 때 골치아플 것 같네..
df.duplicated().sum()
df.drop_duplicates(inplace=True)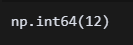 중복값이 12개 있어서 드랍시켰다.
중복값이 12개 있어서 드랍시켰다.
df_numeric = df.select_dtypes(include=['number']).columns
scl = MinMaxScaler()
df_scl = pd.DataFrame(scl.fit_transform(df[df_numeric]), columns=df_numeric)
plt.figure(figsize=(15, 8))
sns.boxplot(data=df_scl)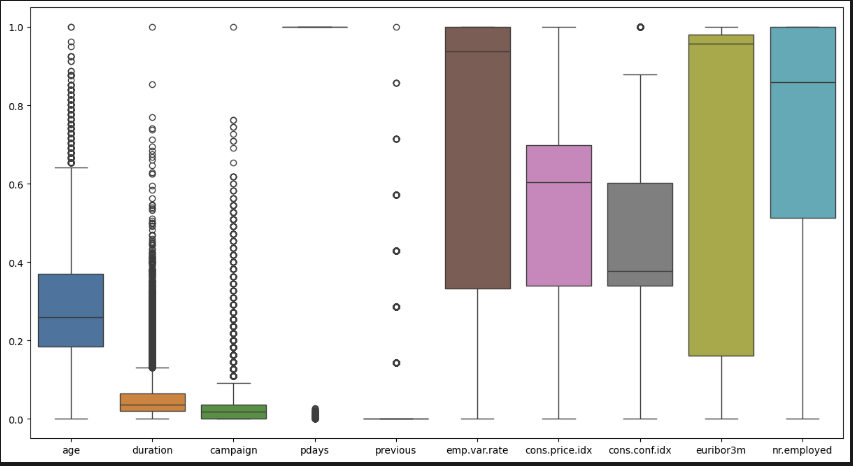 수치형 데이터를 먼저 보자. 조금 이상해 보이는 컬럼이 몇 개 있다. 일단 전부 보면서 생각해 보자.
수치형 데이터를 먼저 보자. 조금 이상해 보이는 컬럼이 몇 개 있다. 일단 전부 보면서 생각해 보자.
-
age(나이)
연령대 분포가 퍼져 있고 이상치(고령자)가 존재한다. 중년층이 중심이고 고령층도 있지만 드물다는 뜻. 제거할 필요는 없어 보인다. -
duration(콜 지속초)
대부분 전화를 금방 끊었다. 이상치가 많다. 전화를 길게 한 사람들의 통화 시간이 제각각이라는 뜻이다. 이상치가 너무 많으니 삭제. -
campaign(콜 횟수)
중앙값이 낮다. 박스가 아주 좁은 범위에 몰려 있다. 대부분의 고객은 1~2회 정도만 연락을 받았다는 뜻이다. 이상치를 mode값으로 대체. -
pdays(전 캠페인 후 경과일)
대부분의 값이 0 근처에 몰려 있다. 대부분 첫 연락이었다는 뜻이다. 범주형으로 사용하기 위해 0과 1로 변경. -
previous(이전 캠페인 동안 연락 횟수)
pdays와 비슷한 형태. 대부분 0으로, 응답 했던 적이 거의 없는 고객이 많음. 이것도 범주형으로 사용하기 위해 0과 1로 변경. -
emp.var.rate(고용 변화율)
이상치 없음. 분포가 넓어서 모델 학습에 좋아 보인다. -
cons.price.idx (소비자 물가 지수)
이상치 없음. -
cons.conf.idx (소비자 신뢰 지수)
일부 상위 이상치만 제거. -
euribor3m (3개월 유로 금리)
이상치 없음. 분포가 넓어서 모델 학습에 좋아 보인다. -
nr.employed (고용 인구 수)
이상치 없음.
# duration 삭제
df.drop(columns=['duration'], inplace=True)
# campaign 3사분위 이상 처리
upper_limit = (df['campaign'].quantile(0.75) + (1.5 * (df['campaign'].quantile(0.75) - df['campaign'].quantile(0.25))))
df['campaign'] = df['campaign'].where(df['campaign'] <= upper_limit, df['campaign'].mode()[0])
# pdays 이진화
df['pdays'] = df['pdays'].apply(lambda x: 0 if x == 999 else 1)
# previous 이진화
df['previous'] = df['previous'].apply(lambda x: 0 if x == 0 else 1)
# cons.conf.idx 3사분위 이상 처리
upper_limit = (df['cons.conf.idx'].quantile(0.75) + (1.5 * (df['cons.conf.idx'].quantile(0.75) - df['cons.conf.idx'].quantile(0.25))))
df['cons.conf.idx'] = df['cons.conf.idx'].where(df['cons.conf.idx'] <= upper_limit, df['cons.conf.idx'].mode()[0])전반적으로 이상치를 처리했다.
# 수정 반영 여부 확인
df_numeric = df.select_dtypes(include=['number']).columns
scl = MinMaxScaler()
df_scl = pd.DataFrame(scl.fit_transform(df[df_numeric]), columns=df_numeric)
plt.figure(figsize=(15, 8))
sns.boxplot(data=df_scl)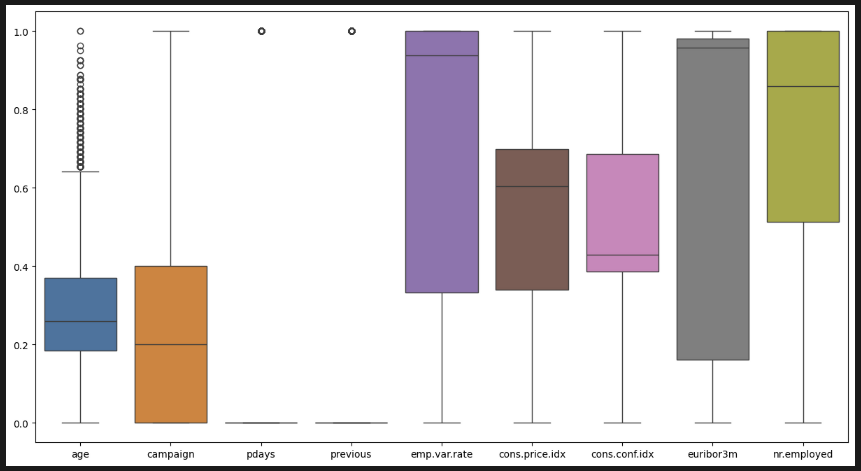 아까보다 훨씬 정돈된 느낌이다.
아까보다 훨씬 정돈된 느낌이다.
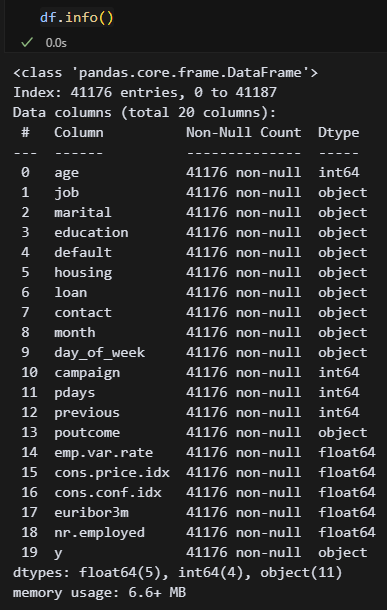 이제 문자열을 처리할 차례인데 생각보다 오브젝트가 많다.
이제 문자열을 처리할 차례인데 생각보다 오브젝트가 많다.
# 문자열 데이터 확인
print(df.select_dtypes(exclude=['number']).columns, "\n", '-' * 50)
def print_uniques(df, columns):
for column in columns:
counts = df[column].value_counts()
combined = [f"{word}({count})" for word, count in zip(counts.index, counts.values)]
print(f"{column}: {', '.join(combined)}")
print('-' * 50)
columns_to_check = df.select_dtypes(exclude=['number']).columns
print_uniques(df, columns_to_check)오브젝트를 한번에 보고 싶어서 연구하다가 함수를 하나 만들었다. 와 이거 하나 만드는데 한 시간이 넘게 걸렸다. 잘 저장해뒀다가 나중에도 써야지!
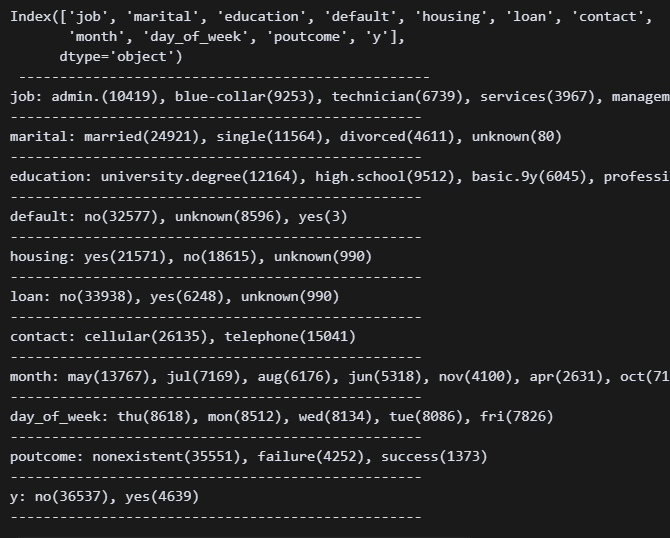 쭉 보니 정제할 게 몇 보인다.
쭉 보니 정제할 게 몇 보인다.
job: 온점과 대쉬 삭제. unknown 결측치로 판단하고 삭제.
marital: unknown 결측치로 판단하고 삭제.
education: professional, university, highschool, basic으로 통일. unknown 결측치로 판단하고 삭제. illiterate 몇 명 없으므로 최적화를 위해 삭제.
default: 예가 3명이고 나머지는 아니오&미확인이다. 이 컬럼은 드롭하는 게 좋을 듯하다.
housing: unknown 결측치로 판단하고 삭제.
loan: unknown 결측치로 판단하고 삭제.
contact: 이상 없음
month: 이상 없음
day_of_week: 이상 없음
poutcome: 이상 없음
y: 이상 없음
# 문자열 정제
df['job'] = (df['job']
.str.replace('.', '', regex=False)
.str.replace('-', '', regex=False)
.str.lower()
.str.strip()
)
df['education'] = (df['education']
.str.replace('university.degree', 'university', regex=False)
.str.replace('high.school', 'highschool', regex=False)
.str.replace('professional.course', 'professional', regex=False)
.str.replace('basic.9y', 'basic', regex=False)
.str.replace('basic.6y', 'basic', regex=False)
.str.replace('basic.4y', 'basic', regex=False)
.str.replace('illiterate', 'unknown', regex=False)
)
df = df[df['housing'] != 'unknown']
df = df[df['loan'] != 'unknown']
df = df[df['job'] != 'unknown']
df = df[df['education'] != 'unknown']
df = df[df['marital'] != 'unknown']
df = df.drop(columns=['default'])
df['y'] = df['y'].map({'yes': 1, 'no': 0})
columns_to_check = df.select_dtypes(exclude=['number']).columns
print_uniques(df, columns_to_check)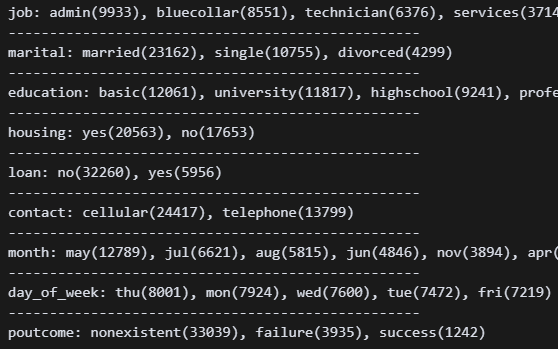 문자열 정제 완료. 종속변수도 미리 매핑해줬다.
문자열 정제 완료. 종속변수도 미리 매핑해줬다.
2. 시각화
# 시각화
plt.xticks(rotation=45); plt.show(sns.lineplot(data=df, x='age', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='job', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='marital', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='education', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='housing', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='loan', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='contact', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.lineplot(data=df, x='month', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='day_of_week', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='campaign', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='pdays', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='previous', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='poutcome', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.lineplot(data=df, x='emp.var.rate', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.lineplot(data=df, x='cons.price.idx', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.lineplot(data=df, x='cons.conf.idx', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.lineplot(data=df, x='euribor3m', y='y', errorbar=None, palette='Set2'))
plt.xticks(rotation=45); plt.show(sns.barplot(data=df, x='nr.employed', y='y', errorbar=None, palette='Set2'))계속 코드 쓰기 귀찮아서 한방에 다 넣었다. 그랬더니 진짜 한방에 다 나옴. 필요한 것만 코멘트 달아보겠음.
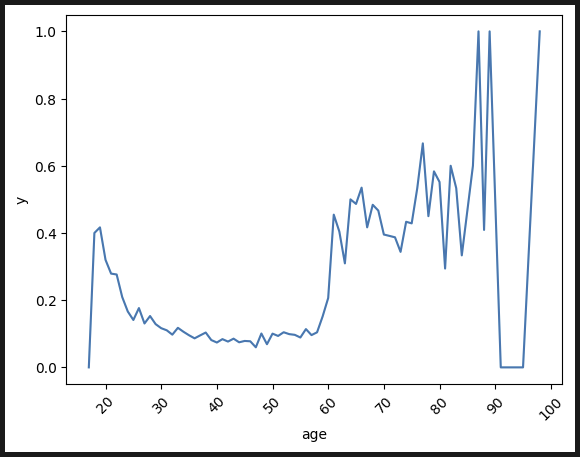 나이: 20대 초반 반짝, 그 후 60대부터 가입률이 높다. 30대부터 높을 것이라 추축했는데 의외의 결과다.
나이: 20대 초반 반짝, 그 후 60대부터 가입률이 높다. 30대부터 높을 것이라 추축했는데 의외의 결과다.
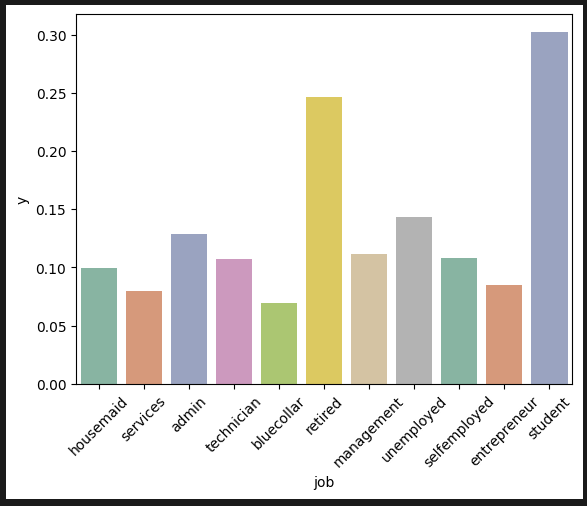 직업: 학생과 은퇴자 비율이 높다. 20대 초반과 60대 이후니 이해가 된다.
직업: 학생과 은퇴자 비율이 높다. 20대 초반과 60대 이후니 이해가 된다.
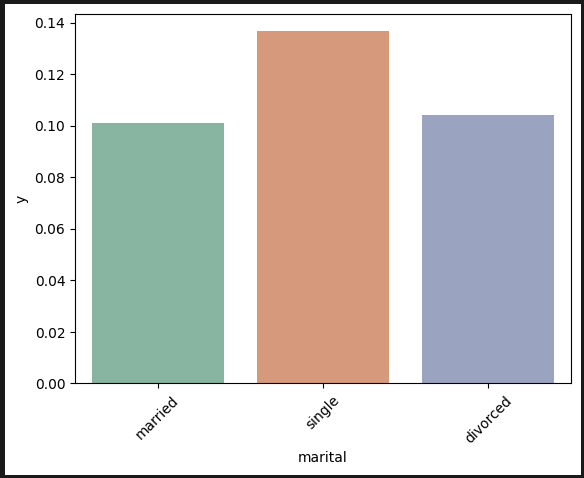 결혼여부: 싱글이 소폭 높다. 결혼하면 저축할 시간이 없을 것이라 생각했는데 어쩌면 맞았나..!?
결혼여부: 싱글이 소폭 높다. 결혼하면 저축할 시간이 없을 것이라 생각했는데 어쩌면 맞았나..!?
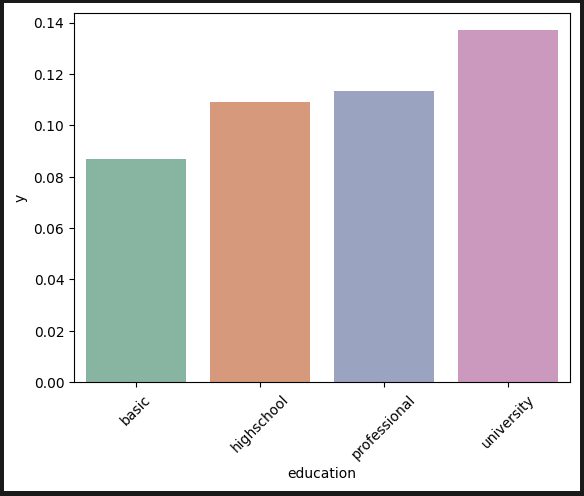 학력: 학력이 높을수록 가입률도 높다. 왜지?? 더 돈을 잘 벌어서 그런가?
학력: 학력이 높을수록 가입률도 높다. 왜지?? 더 돈을 잘 벌어서 그런가?
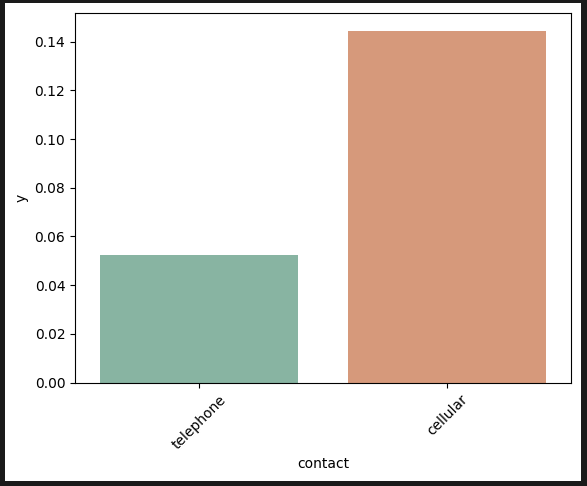 연락수단: 폰으로 연락할 때 가입률이 높다. 유선전화는 오래받기 싫어서 그럴 것이라 생각해 본다.
연락수단: 폰으로 연락할 때 가입률이 높다. 유선전화는 오래받기 싫어서 그럴 것이라 생각해 본다.
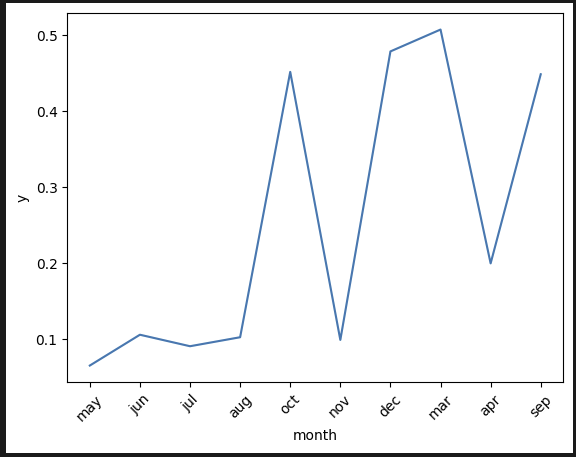 월: 순서가 약간 뒤죽박죽이긴 한데 3, 9, 10, 12월이 높다.
월: 순서가 약간 뒤죽박죽이긴 한데 3, 9, 10, 12월이 높다.
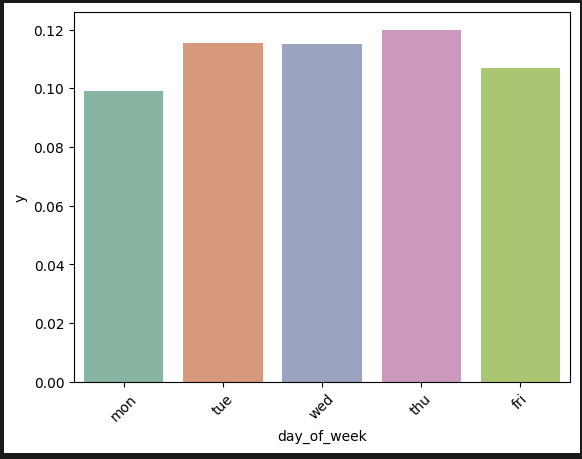 일: 요일은 관계가 없다.
일: 요일은 관계가 없다.
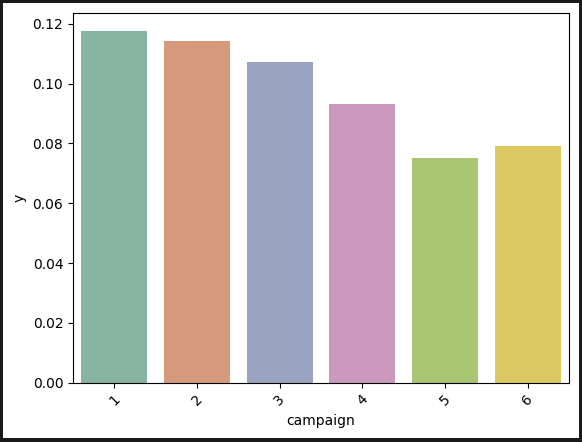 연락횟수: 많이 할수록 떨어진다.
연락횟수: 많이 할수록 떨어진다.
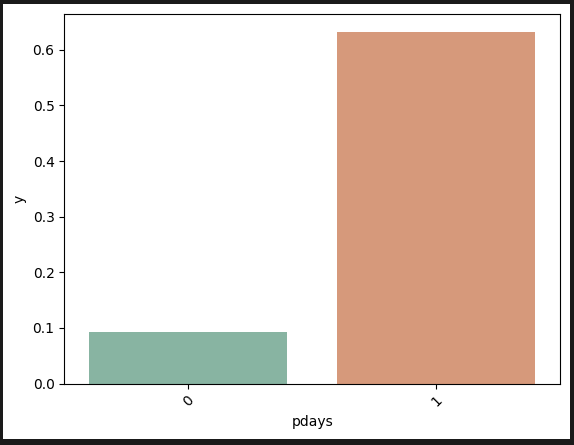 이전 캠페인 후 지난 일수: ?? 이건 이해를 못하겠다. 삭제!
이전 캠페인 후 지난 일수: ?? 이건 이해를 못하겠다. 삭제!
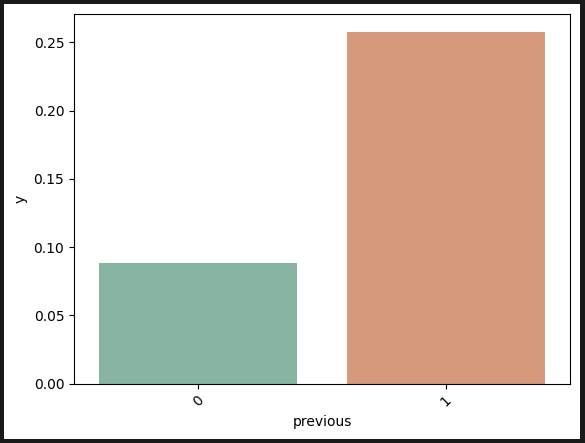 이전 캠페인에 연락했던 사람: 확실히 연락했던 사람이 더 잘 가입한다.
이전 캠페인에 연락했던 사람: 확실히 연락했던 사람이 더 잘 가입한다.
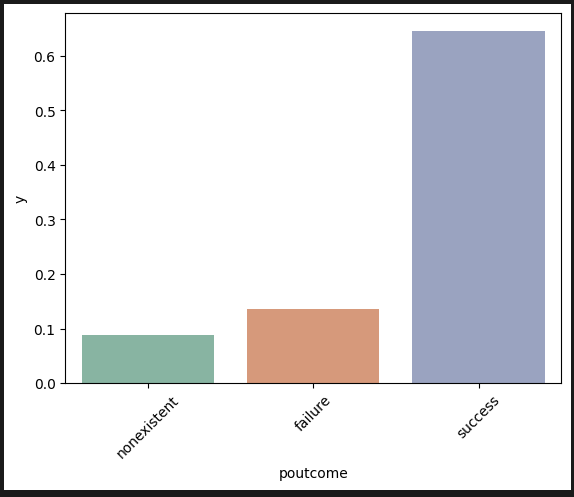 이전 캠페인 결과: 가입했던 사람이 더 잘 가입한다.
이전 캠페인 결과: 가입했던 사람이 더 잘 가입한다.
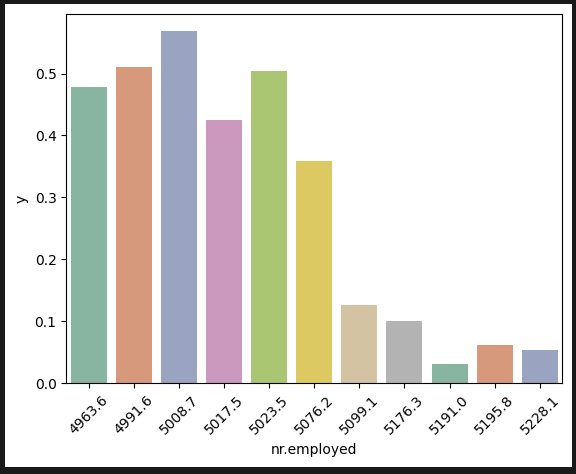 고용자 수: 고용률의 절대수치 같은 건가? 고용자 수가 높을 수록 예금 가입률은 떨어진다.
고용자 수: 고용률의 절대수치 같은 건가? 고용자 수가 높을 수록 예금 가입률은 떨어진다.
패턴이 보이지 않는 housing, loan, day_of_week, emp.var.rate, cons.price.idx, cons.conf.idx, euribor3는 삭제해야겠다.
df.drop(columns=[
'housing',
'loan',
'day_of_week',
'emp.var.rate',
'cons.price.idx',
'cons.conf.idx',
'euribor3m'], inplace=True) 오케이 필요한 열만 남았다. 이제 마지막으로 인코딩을 해보자!
오케이 필요한 열만 남았다. 이제 마지막으로 인코딩을 해보자!
# 문자열 인코딩 진행
# 원핫인코딩(랜덤포레스트 용)
df['month'] = df['month'].map({'jan': 1, 'feb': 2, 'mar': 3, 'apr': 4, 'may': 5, 'jun': 6, 'jul': 7, 'aug': 8, 'sep': 9, 'oct': 10, 'nov': 11, 'dec': 12})
df_encoded = pd.get_dummies(df, columns=['job', 'marital', 'education', 'contact', 'poutcome'], drop_first=True)
# 카테고리화(CatBoost, LightGBM 용)
df_cat = df.copy()
cat = ['job', 'marital', 'education', 'contact', 'poutcome']
df_cat[cat] = df_cat[cat].astype('category')
df_encoded.info()CatBoost랑 LightGBM에는 카테고리 타입을 자동으로 변환하는 기능이 있다고 한다. 그래서 비교해 보려고 df를 두 개로 나눴다. 이제 데이터 전처리는 끝난 것 같다. 내일은 모델을 구현해 보자!
