지도학습을 끝내고 비지도학습을 배우니 그래도 할만한 것 같다. 비지도학습은 시각화를 통해 의미를 찾아내는 것이 중요한 듯하다.
학습시간 09:00~01:00(당일16H/누적294H)
◆ 오늘의 깨달음
-
클러스터링은 원핫인코딩 & 스케일링을 해야한다.
-
차원축소는 데이터 정제를 위해서이기도 하지만 시각화를 위해서이기도 하다.
◆ 학습내용
1. 클러스터링 (Clustering)
(1) 정의
- 정답 없이 유사한 특성을 가진 데이터를 군집화하는 과정
(2) Hard Clustering
- 클러스터를 명확하게 구분
- 하나의 데이터는 하나의 클러스터에만 속함
- 대표 모델: KMeans
(3) Soft Clustering
- 클러스터의 포함 정도를 표현
- 하나의 데이터가 여러 클러스터에 속할 수 있음
(4) 클러스터링의 목표
- 군집 간 유사성 최소화: 다른 군집 간에는 데이터가 비슷하지 않아야 함
- 군집 내 유사성 최대화: 동일 군집 내에서는 데이터가 서로 유사해야 함
(5) KMeans 알고리즘
- 데이터를 k개의 그룹으로 나누는 대표적인 군집화 알고리즘
- 각 데이터는 가장 가까운 클러스터 중심에 할당됨
- 간단하고 효과적인 방법
A. Elbow Method
- 클러스터 수(k)를 정하는 기준
- SSE(Sum of Squared Errors)의 감소율이 완만해지는 지점 선택
B. 클러스터링 평가 지표 - 실루엣 점수
- 실루엣 계수는 -1 ~ 1 범위
- 1: 잘 군집화됨 / 0: 애매 / -1: 잘못된 군집
C. KMeans 특징과 한계
- 복잡한 데이터 분포에서는 성능이 낮을 수 있음
- 대용량 데이터에서 유리함
2. 차원축소 (Dimensionality Reduction)
(1) 정의
- 고차원 데이터를 저차원으로 압축하여 주요 정보 유지, 복잡성 감소
- 고차원에서는 거리 기반 계산이 어렵고 모델 성능이 떨어짐
- 차원 수가 많을수록 과적합 위험이 커짐
(2) 차원의 저주 (Curse of Dimensionality)
- 차원이 증가할수록 데이터는 희소해지고 분석이 어려워짐
- 따라서 아래와 같은 방법을 사용
A. 차원 축소
- 주요 정보를 유지하면서 차원을 줄이는 기법
- 계산 비용 감소, 성능 향상에 기여
B. 피처 선택
- 중요한 피처만 선택해 불필요한 피처 제거
- 상관관계, 정보이득, L1 규제 등 활용
C. 피처 엔지니어링
- 기존 피처를 변형하거나 새로운 피처를 생성
- 변수 간 비율, 차이 계산 등
D. 데이터 수집과 생성
- 데이터 희소성 문제를 보완하기 위한 수집 및 증강 전략
E. 알고리즘 선택
- 고차원 데이터에 강한 알고리즘 선택
- 예: 랜덤 포레스트 등
3. 주성분 분석 (PCA)
(1) 개요
- 데이터의 분산을 최대한 보존하면서 고차원 데이터를 저차원으로 투영
- 잔차 제곱 최소화 ↔ 분산 최대화 원리 사용
A. 데이터 표준화
- 평균 0, 분산 1로 스케일링
B. 공분산 행렬 계산
- 변수 간 관계를 나타내는 행렬 생성
C. 고유값 분해
- 고유값: 분산 비율
- 고유벡터: 주성분 방향
D. 주성분 선택
- 고유값이 큰 상위 k개의 주성분 선택
E. 데이터 변환
- 주성분 기준으로 데이터 재투영 → 차원 축소
(2) 주성분 선택 기법
A. 설명된 분산 비율 / 누적 설명 분산 비율
- 각 주성분이 설명하는 데이터 분산 비율 확인 후 선택
B. 스크리플롯
- 고유값 그래프에서 꺾이는 지점 기준으로 주성분 수 결정
(3) PCA 특징 및 활용
- 해석은 어렵지만 고차원 데이터 압축에 매우 유용
4. 코드 예시
(1) 스케일링
''' Mall_Customers 로 실습 진행'''
import pandas as pd
df = pd.read_csv('data/Mall_Customers.csv')
df = df.drop(columns=['CustomerID'])
df = pd.get_dummies(df, columns=['Gender'])
from sklearn.preprocessing import StandardScaler
X = df
scl = StandardScaler()
X_scl = scl.fit_transform(X)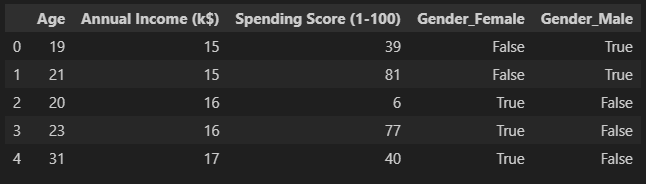
(2) 엘보우 시각화
from sklearn.cluster import KMeans
k_range = range(1, 11)
inertia_list = [KMeans(n_clusters=k).fit(X_scl).inertia_ for k in k_range]
plt.plot(k_range, inertia_list, '-o')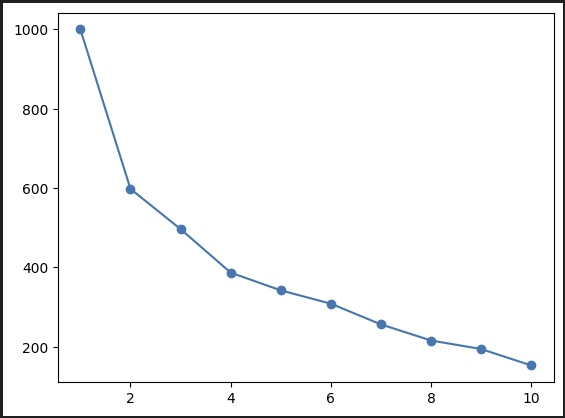
(3) 실루엣 시각화
from sklearn.metrics import silhouette_score
s_score = [silhouette_score(X_scl, KMeans(n_clusters=k).fit_predict(X_scl))for k in range(2, 11)]
plt.plot(range(2, 11), s_score, '-o')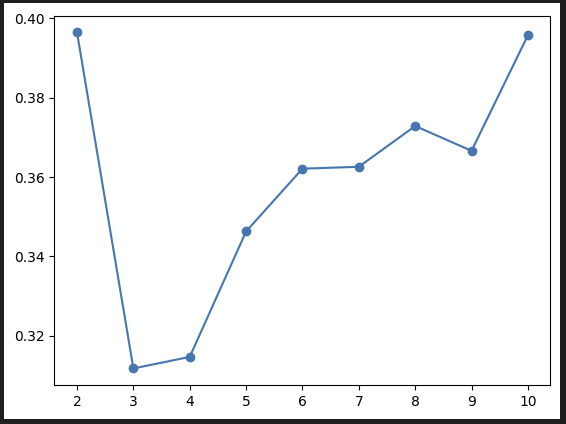
(4) k값 설정
from sklearn.cluster import KMeans
m_kmeans = KMeans(n_clusters=5)
pred_kmeans = m_kmeans.fit_predict(X_scl)시각화 그래프 참고하여 k=5로 설정함
(5) 차원축소 후 시각화
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scl)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=pred_kmeans, s=40)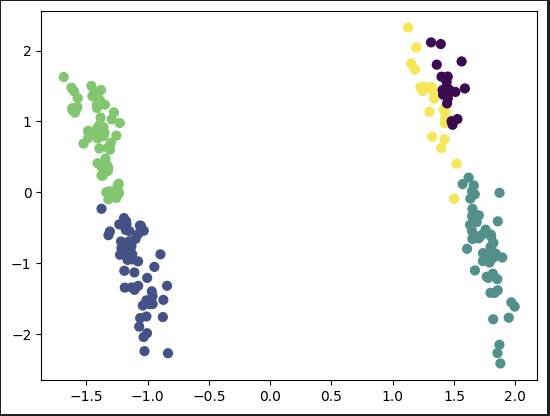 2차원 그래프로 보기 위해 2차원으로 축소. 5개 그룹이 잘 형성되었다.
2차원 그래프로 보기 위해 2차원으로 축소. 5개 그룹이 잘 형성되었다.
(6) 주성분 기여도 분석
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 1. 데이터 준비
iris = load_iris()
X = iris.data
X_scaled = StandardScaler().fit_transform(X)
# 2. PCA 수행
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# 3. 값 계산
explained_var = pca.explained_variance_ratio_
cumulative_var = np.cumsum(explained_var)
# 4. 몇 번째 주성분까지 90%를 설명하는지 계산
threshold = 0.9
num_components_90 = np.argmax(cumulative_var >= threshold) + 1
print(f"🔍 90% 설명하려면 최소 {num_components_90}개의 주성분이 필요해!")
# 5. 시각화
plt.figure(figsize=(10, 8))
# 개별 주성분 설명력 (막대)
plt.bar(range(1, len(explained_var)+1), explained_var,
alpha=0.6, align='center', label='individual components')
# 누적 설명력 (선)
plt.plot(range(1, len(cumulative_var)+1), cumulative_var,
marker='o', linestyle='-', color='royalblue', label='cum sum')
# 90% 기준선
plt.axhline(y=threshold, color='red', linestyle='--', label='threshold (90%)')
# 라벨 설정
plt.xlabel('num of principal components')
plt.ylabel('ratio')
plt.title('Explained Variance & 90% Threshold Point')
plt.xticks(range(1, len(explained_var)+1))
plt.grid(True, linestyle=':', alpha=0.7)
plt.legend()
plt.tight_layout()
plt.show()
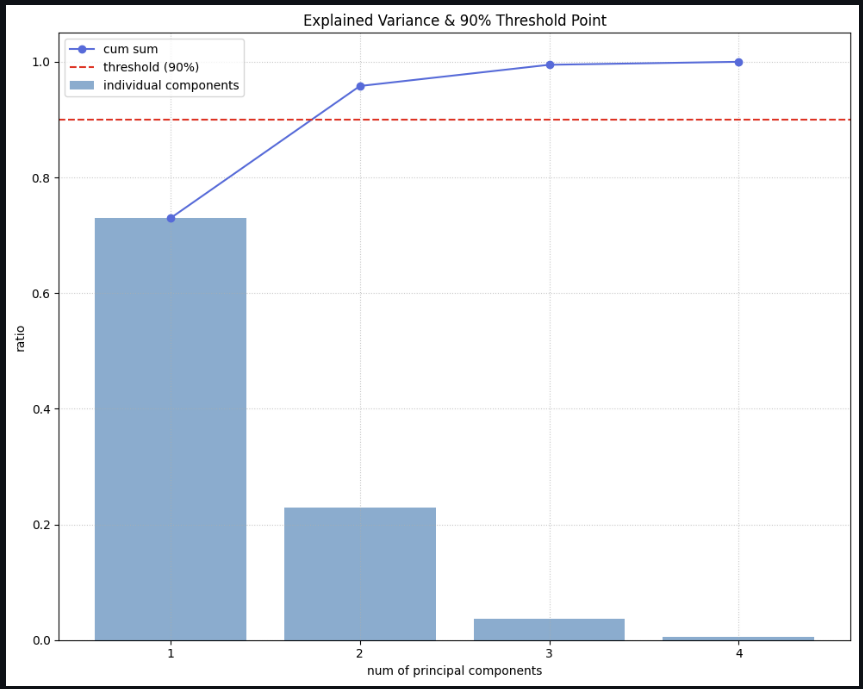 90% 이상 설명된 주성분을 구하려면 최소 2차원이어야 한다는 뜻.
90% 이상 설명된 주성분을 구하려면 최소 2차원이어야 한다는 뜻.
월요일에 내용을 조금 더 추가해야지!

AI Engineer