강의 커리큘럼이 너무 혹독하다. 퍼셉트론에 익숙해지지도 않았는데 바로 이미지 처리라니... 멘탈 꽉 잡고 버티자...
학습시간 09:00~01:00(당일16H/누적327H)
◆ 학습내용
1. FCN (Fully Convolutional Network)
(1) 특징
- 완전 연결층 없이 모든 레이어를 합성곱(Conv)으로 구성한 신경망
- 이미지의 각 픽셀에 대한 예측이 가능해, 주로 Semantic Segmentation에 사용됨
- CNN에서 FC Layer를 1×1 Convolution으로 대체
- 출력 크기를 원래 이미지 크기로 맞추기 위해 업샘플링(Deconvolution) 적용
- 다양한 크기의 입력 이미지 처리 가능
(2) 장점
- 픽셀 단위 예측 → 정밀한 분할 가능
- FC 제거 → 입력 크기 유연성 확보
- End-to-End 학습 가능
(3) 한계
- Pooling으로 공간 정보 손실 발생
- 경계 표현이 부정확할 수 있음
- 해상도 손실 복원이 어려워, U-Net 등 발전된 구조 필요
(4) 왜 잘 사용되지 않는가?
- 기본 FCN은 경계 정보 복원에 약함
- 복잡한 구조나 미세한 객체 구분에 부족
- 최근에는 Skip Connection을 강화한 U-Net, 다중 스케일 추출이 가능한 DeepLab, 정교한 feature decoder 구조를 가진 SegNet 등이 성능적으로 훨씬 우수
- 따라서 FCN은 역사적 출발점으로 의미가 있고, 실전에서는 거의 개선된 구조를 사용함
2. CNN (Convolutional Neural Network)
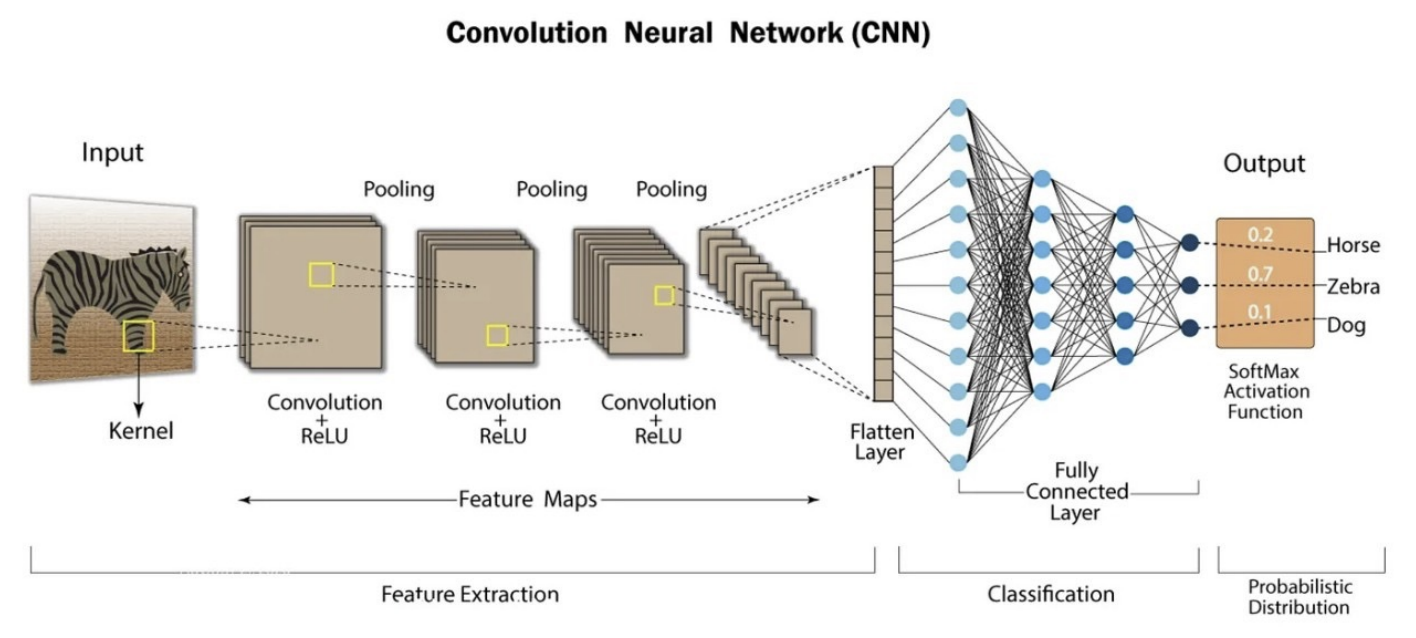
(1) 정의
- CNN은 이미지나 영상처럼 공간적인 패턴이 있는 데이터를 효과적으로 처리하는 딥러닝 구조야.
- 입력 데이터의 지역적인 특징(엣지, 색, 패턴 등)을 작은 필터로 추출해서 전체적인 의미를 점점 넓은 범위로 확장해나가는 방식이야.
(2) 특징
- 부분 연결(Local Connectivity)
- 입력 전체를 연결하지 않고, 필터가 일정 영역(지역)만 보며 특징 추출 → 연산량 감소 + 지역 패턴 학습에 유리
- 가중치 공유(Weight Sharing)
- 같은 필터를 전체 이미지에 적용함으로써 파라미터 수를 획기적으로 줄임 → 학습 효율 증가
- 계층적 특징 표현(Hierarchical Feature Extraction)
- 초기 레이어는 엣지, 색상 등 저수준 특징을, 깊은 레이어는 형태, 물체 등 고수준 특징을 학습
- 공간 구조 보존(Spatial Hierarchy 유지)
- MLP는 벡터화로 위치 정보 손실이 크지만, CNN은 이미지의 2D 구조와 공간적 의미를 유지한 채 처리 가능
- 전처리 최소화(Automatic Feature Extraction)
- 수작업 특징 추출 없이, CNN이 데이터에서 자동으로 유용한 특징을 학습
(3) 구조 및 역할
CNN Network
├── Conv Layer 1
│ ├── Filter 1 → Feature Map 1-1
│ ├── Filter 2 → Feature Map 1-2
│ └── Filter 3 → Feature Map 1-3
│
├── Conv Layer 2
│ ├── Filter 1 → Feature Map 2-1
│ ├── Filter 2 → Feature Map 2-2
│ └── Filter 3 → Feature Map 2-3
│
├── Conv Layer 3
│ ├── Filter 1 → Feature Map 3-1
│ ├── Filter 2 → Feature Map 3-2
│ └── Filter 3 → Feature Map 3-3- Convolution Filter(Kernel): 입력 데이터에서 특징을 뽑아내는 작은 창 (필터)
- Stride: 필터가 이동하는 간격. 클수록 출력 크기가 작아짐
- Padding: 입력 가장자리에 0을 추가해서 출력 크기를 조절하거나 정보 손실을 막음
- Pooling Layer: 특징 맵에서 중요한 값만 뽑아내어 데이터 크기를 줄임
- Max Pooling: 가장 큰 값 선택
- Average Pooling: 평균 값 계산
| 요소 | 정의 | 역할 | 상위 포함 관계 |
|---|---|---|---|
| Filter (Kernel) | 작은 창(sliding window) | 입력 이미지에서 특정 특징 추출 (예: 엣지, 텍스처 등) | 레이어 안에 여러 개 존재 |
| Layer (Convolutional Layer) | 여러 필터가 모인 층 | 각 필터가 독립적으로 입력을 스캔하여 다양한 특징 맵(feature map) 생성 | 네트워크의 하나의 구성 단위 |
| Network (CNN) | 여러 레이어가 연결된 전체 구조 | 입력 이미지로부터 점점 고차원적인 특징을 추출하여 최종 출력 생성 | CNN 전체 구조 |
(4) 대표 모델
- ImageNet: 14백만 이미지, 2만 클래스. ILSVRC 대회 (2010~2017)로 유명
- LeNet-5 (1998): CNN의 시초. 손글씨 숫자 인식(MNIST)용으로 설계됨
- AlexNet (2012): GPU 병렬 연산, ReLU, Dropout 도입. CNN + GPU 조합의 시초
- VGGNet (2014): 3x3 필터만 반복 사용, 구조 단순화. 깊은 네트워크 구조
- GoogLeNet (2014): 다양한 필터를 병렬로 쓰는 Inception 구조, 연산 효율 높임
- ResNet (2015): Residual Block, Skip Connection 도입 → 매우 깊은 네트워크 가능
| 모델 | 연도 | 주요 특징 | 파라미터 수 |
|---|---|---|---|
| LeNet-5 | 1998 | 초기 CNN 구조, MNIST 숫자 분류용 | 약 60K |
| AlexNet | 2012 | ReLU, Dropout, GPU 활용, Top-5 error 감소 | 약 60M |
| VGGNet | 2014 | 3x3 커널 반복, 깊은 구조 | 약 144M |
| GoogLeNet | 2014 | Inception 구조, 연산 최적화 | 약 5M |
| ResNet | 2015 | Residual Learning, Gradient 소실 해결 | 약 60M~ |
(5) 코드 예시 (PyTorch)
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc = nn.Linear(64 * 6 * 6, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
return self.fc(out)(6) CNN 커널 필터 종류
A. Sobel X: 수직 경계 감지
[[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]]B. Sobel Y: 수평 경계 감지
[[-1, -2, -1],
[ 0, 0, 0],
[ 1, 2, 1]]C. Prewitt X: 수직 경계 감지
[[-1, 0, 1],
[-1, 0, 1],
[-1, 0, 1]]D. Laplacian: 에지(모서리) 감지 (2차 미분)
[[ 0, -1, 0],
[-1, 4, -1],
[ 0, -1, 0]]E. Gaussian Blur: 흐림/노이즈 제거
[[1, 2, 1],
[2, 4, 2],
[1, 2, 1]] # 전체를 16으로 나눠서 평균처리F. Sharpen: 이미지 선명화
[[ 0, -1, 0],
[-1, 5, -1],
[ 0, -1, 0]]G. Emboss: 양각(3D 입체감) 효과
[[-2, -1, 0],
[-1, 1, 1],
[ 0, 1, 2]](7) 아웃풋 크기 공식
A. 공식 설명
| 기호 | 의미 |
|---|---|
| W | 입력 크기 (Width or Height) |
| K | 커널 크기 |
| P | 패딩 크기 |
| S | 스트라이드 크기 |
B. 사용 예시
[ 입력값 ]
이미지 크기: 300*400
커널: 3
패딩: 1
스트라이드: 2
149.5 + 1로 150.5가 나오지만, 내림하여 150임
199.5 + 1로 200.5가 나오지만, 내림하여 200임
[ 출력값 ]
이미지 크기: 150*200
(8) 레이어 순서 및 종류
A. 레이어 순서
| 단계 | 레이어 종류 | 설명 |
|---|---|---|
| 1 | Input Layer | 이미지 입력 (예: 3채널 RGB 이미지) |
| 2 | Conv Layer | 필터로 로우레벨 특징 추출 (엣지, 선 등) |
| 3 | Activation (ReLU) | 비선형성 부여 |
| 4 | BatchNorm (옵션) | 출력값 정규화, 학습 안정화 |
| 5 | Pooling Layer | 크기 축소, 연산량 감소 |
| 6 | (반복) | Conv → ReLU → BatchNorm → Pooling 을 여러 블록 반복 |
| 7 | Flatten Layer | 2D → 1D 벡터 변환 |
| 8 | Fully Connected Layer | 예측 학습 (분류 or 회귀) |
| 9 | Dropout (옵션) | 과적합 방지 |
| 10 | Output Layer | Softmax or Sigmoid 등으로 최종 예측 |
B. 레이어 종류
| 레이어 이름 | 정의 및 역할 | 주요 키워드 | PyTorch 예시 코드 | 장점 | 단점 |
|---|---|---|---|---|---|
| Convolutional Layer | 입력 이미지에서 커널을 이용해 특징을 추출하는 기본 레이어 | 필터, 스트라이드, 패딩 | nn.Conv2d(3, 16, 3, 1, 1) | 다양한 패턴 추출 가능, 파라미터 공유로 효율적 | 고정된 커널 크기로 인해 장기 의존 정보 반영 한계 |
| Depthwise Conv Layer | 채널별로 각각의 커널을 적용하여 파라미터 수를 줄이는 경량화 기법 | MobileNet, 채널별 연산 | nn.Conv2d(..., groups=in_channels) | 연산량과 파라미터 대폭 감소, 모바일에 적합 | 채널 간 상호작용 부족 → 성능 저하 가능 |
| Dilated Conv Layer | 커널 사이 간격을 늘려 더 넓은 수용 영역 확보 | Atrous convolution, receptive field 확장 | dilation 파라미터 추가 | 수용 영역 확장으로 넓은 문맥 정보 처리 가능 | 커널 간 간격으로 인한 정보 손실, 그리드 아티팩트 발생 가능 |
| Separable Conv Layer | 공간별-채널별 분리 연산으로 효율성 향상 | Xception, 경량화 | Depthwise + Pointwise | 연산량 줄이면서 성능 유지 가능 | 구현 복잡성 증가, 튜닝 민감 |
| Transposed Conv Layer | 업샘플링(해상도 증가)에 사용되는 역 컨볼루션 레이어 | Deconvolution, GAN, U-Net | nn.ConvTranspose2d(...) | 학습 기반 업샘플링 가능, 복원/생성에 유용 | Checkerboard 아티팩트 발생 위험 |
| Pooling Layer | 특징맵의 크기를 줄이는 다운샘플링 레이어 | MaxPooling, AveragePooling | nn.MaxPool2d(2, 2) | 연산량 감소, 과적합 방지, 핵심 특징 유지 | 위치 정보 손실, 세밀한 정보 무시 가능 |
| Global Pooling Layer | 특징맵 전체를 평균 or 최댓값으로 요약하여 1D 벡터로 만듦 | GlobalAveragePooling | Adaptive Pool 사용 | 파라미터 없음, Flatten 대체 가능 | 지역 정보 손실, 정밀한 위치 정보 반영 어려움 |
| Activation Layer | 비선형성 부여 (복잡한 패턴 학습 가능) | ReLU, GELU, LeakyReLU | nn.ReLU(), nn.GELU() | 복잡한 함수 근사 가능, 모델 표현력 향상 | ReLU는 죽은 뉴런 문제, Sigmoid는 Gradient Vanishing 위험 |
| Normalization Layer | 출력값을 정규화하여 학습 안정화 | BatchNorm, LayerNorm | nn.BatchNorm2d(16) | 학습 수렴 가속화, 과적합 감소 | 작은 배치에서는 불안정할 수 있음 |
| Dropout Layer | 일부 뉴런 무작위 제거로 과적합 방지 | Regularization, 무작위 비활성화 | nn.Dropout(0.5) | 간단한 정규화 방식, 과적합 방지에 효과적 | 과도하게 사용 시 성능 저하 가능 |
| Fully Connected Layer | 특징을 바탕으로 최종 예측 수행 | Dense, Linear, Flatten | nn.Linear(128, 10) | 모든 특징 고려 가능, 예측 적합 | 파라미터 수 많아 과적합 우려, 공간 구조 손실 |
| Output Layer | 분류 확률 또는 회귀 값 출력 | Softmax, Sigmoid | nn.Softmax(dim=1) | 직관적인 예측 결과 제공 (확률 기반) | 출력 해석 오류 가능, 잘못된 로짓 처리 |

AI Engineer