오늘 포스팅은 코드로 대체...
학습시간 09:00~02:00(당일17H/누적360H)
◆ 학습내용
1. FCN 기본 모델 구현
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from torch import nn
import torch.optim as optim
from sklearn.preprocessing import StandardScaler
from tqdm import tqdm
# 1. 데이터 로드
df = pd.read_csv('data/codeit/abalone_train.csv', names=[
'Length', 'Diameter', 'Height', 'Whole weight',
'Shucked weight', 'Viscera weight', 'Shell weight', 'Age'])
input_data = df.drop(columns=['Age']).to_numpy().astype(np.float32)
target_data = df['Age'].to_numpy().astype(np.float32)
# 2. Dataset Class 생성
# 레이어 생성 전 배치&피처 확인!!!
# x, y = next(iter(train_dataloader))
# print(x.shape, y.shape)
# torch.Size([32, 7]) torch.Size([32])
class AbaloneDataset(Dataset):
def __init__(self, input_data, target_data, scaler=None):
self.input_data = input_data
self.target_data = target_data
self.scaler = scaler
def __len__(self):
return len(self.input_data)
def __getitem__(self, index):
input_tensor = torch.tensor(self.input_data[index], dtype=torch.float32)
target_tensor = torch.tensor(self.target_data[index], dtype=torch.float32)
return input_tensor, target_tensor
def inverse_transform(self, data):
if self.scaler:
return self.scaler.inverse_transform(data)
else:
return data
# 3. 데이터 분할
train_size = int(len(input_data) * 0.8)
val_size = int(len(input_data) * 0.1)
test_size = int(len(input_data) * 0.1)
train_inputs = input_data[:train_size]
val_inputs = input_data[train_size:train_size + val_size]
test_inputs = input_data[train_size + val_size:]
train_target = target_data[:train_size]
val_target = target_data[train_size:train_size + val_size]
test_target = target_data[train_size + val_size:]
# 4. 스케일링
scaler = StandardScaler()
scaler.fit(train_inputs)
train_inputs_scaled = scaler.transform(train_inputs)
val_inputs_scaled = scaler.transform(val_inputs)
test_inputs_scaled = scaler.transform(test_inputs)
# 5. Dataset
train_dataset = AbaloneDataset(train_inputs_scaled, train_target, scaler)
val_dataset = AbaloneDataset(val_inputs_scaled, val_target, scaler)
test_dataset = AbaloneDataset(test_inputs_scaled, test_target, scaler)
# 6. DataLoader
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32)
test_dataloader = DataLoader(test_dataset, batch_size=32)
# 7. 모델
class AbaloneModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(7, 32)
self.fc2 = nn.Linear(32, 16)
self.fc3 = nn.Linear(16, 8)
self.fc4 = nn.Linear(8, 1)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.relu(self.fc3(x))
x = self.fc4(x)
return x
model = AbaloneModel()
# 8. 모델 학습
epochs = 20
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
step = 0
for epoch in range(epochs):
running_loss = 0.0
total_batches = len(train_dataloader)
loop = tqdm(train_dataloader, desc=f"Epoch {epoch+1}", leave=False)
for train_batch in loop:
x_train, y_train = train_batch[0].to(device), train_batch[1].to(device)
y_train = y_train.view(-1, 1)
pred = model(x_train)
loss = loss_fn(pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
loop.set_postfix(loss=loss.item())
step += 1
avg_train_loss = running_loss / total_batches
# Validation
model.eval()
val_loss = 0.0
with torch.no_grad():
for val_batch in val_dataloader:
x_val, y_val = val_batch[0].to(device), val_batch[1].to(device)
y_val = y_val.view(-1, 1)
pred = model(x_val)
loss = loss_fn(pred, y_val)
val_loss += loss.item()
avg_val_loss = val_loss / len(val_dataloader)
model.train()
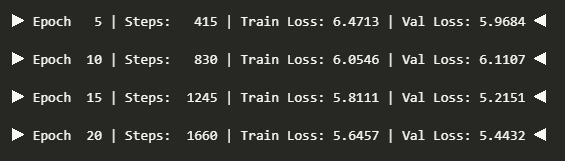
if (epoch + 1) % 5 == 0:
print(f"▶ Epoch {epoch+1:>3} | Steps: {step:>5} | Train Loss: {avg_train_loss:.4f} | Val Loss: {avg_val_loss:.4f} ◀")
2. 코드 설명
(1) 데이터 로드
# 1. 데이터 로드
# Abalone 데이터셋 CSV 파일을 pandas DataFrame으로 불러옴
df = pd.read_csv('data/codeit/abalone_train.csv', names=[
'Length', 'Diameter', 'Height', 'Whole weight',
'Shucked weight', 'Viscera weight', 'Shell weight', 'Age'])
# 입력 변수(X)와 타겟 변수(y)를 분리하여 numpy 배열로 변환
input_data = df.drop(columns=['Age']).to_numpy().astype(np.float32) # shape: (n_samples, 7)
target_data = df['Age'].to_numpy().astype(np.float32) # shape: (n_samples,)
(2) Dataset Class 생성
# 2. Dataset Class 생성
# 이 클래스를 사용하면 DataLoader를 통해 데이터를 배치 단위로 쉽게 불러올 수 있음
class AbaloneDataset(Dataset):
def __init__(self, input_data, target_data, scaler=None):
self.input_data = input_data # 입력 데이터
self.target_data = target_data # 타겟 데이터
self.scaler = scaler # 정규화 스케일러
def __len__(self):
return len(self.input_data) # 전체 샘플 개수 반환
def __getitem__(self, index):
# 특정 인덱스의 데이터를 PyTorch 텐서로 반환
# Dataloader는 이 메서드를 사용해서 배치 데이터를 자동으로 생성함
input_tensor = torch.tensor(self.input_data[index], dtype=torch.float32)
target_tensor = torch.tensor(self.target_data[index], dtype=torch.float32)
return input_tensor, target_tensor
def inverse_transform(self, data):
# 입력 데이터를 원래 스케일로 되돌릴 때 사용 (예: 예측 결과 복원용)
if self.scaler:
return self.scaler.inverse_transform(data)
else:
return data # 스케일러 없으면 그대로 반환
(3) 데이터 분할
# 3. 훈련/검증/테스트 데이터셋 분할
# 전체 데이터를 8:1:1 비율로 나눔
train_size = int(len(input_data) * 0.8)
val_size = int(len(input_data) * 0.1)
test_size = int(len(input_data) * 0.1)
# 인덱스 슬라이싱으로 각 세트 구분
train_inputs = input_data[:train_size]
val_inputs = input_data[train_size:train_size + val_size]
test_inputs = input_data[train_size + val_size:]
train_target = target_data[:train_size]
val_target = target_data[train_size:train_size + val_size]
test_target = target_data[train_size + val_size:]
(4) 스케일링
# 4. 스케일링
# 머신러닝에서 일반적으로 특성 값을 평균 0, 표준편차 1로 정규화하면 성능이 향상됨
scaler = StandardScaler()
scaler.fit(train_inputs) # 학습 데이터 기준으로 정규화 기준(평균, 표준편차)을 학습
# 학습된 스케일러를 기반으로 train/val/test 입력 데이터 변환
# -> target은 회귀 문제이므로 정규화하지 않음 (예측값 해석을 쉽게 하기 위해)
train_inputs_scaled = scaler.transform(train_inputs)
val_inputs_scaled = scaler.transform(val_inputs)
test_inputs_scaled = scaler.transform(test_inputs)
(5) 데이터셋 생성
# 5. 정규화된 데이터를 Dataset 클래스로 감싸기
# 각 세트를 PyTorch Dataset 인스턴스로 만듦
train_dataset = AbaloneDataset(train_inputs_scaled, train_target, scaler)
val_dataset = AbaloneDataset(val_inputs_scaled, val_target, scaler)
test_dataset = AbaloneDataset(test_inputs_scaled, test_target, scaler)
(6) DataLoader 사용
# 6. DataLoader를 통해 배치 단위로 데이터 불러오기
# 학습 데이터는 셔플로 순서 섞기 → 일반적인 학습 안정화 기법
# 검증 및 테스트 데이터는 셔플이 의미가 없음
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32)
test_dataloader = DataLoader(test_dataset, batch_size=32)
(7) 모델 생성
# 7. 회귀용 신경망 모델
class AbaloneModel(nn.Module):
def __init__(self):
super().__init__()
# 완전 연결된 계층 (fully-connected layers)
self.fc1 = nn.Linear(7, 32) # 입력 7차원 → 은닉층 32차원
self.fc2 = nn.Linear(32, 16)
self.fc3 = nn.Linear(16, 8)
self.fc4 = nn.Linear(8, 1) # 출력 1차원 (Age 예측)
self.relu = nn.ReLU() # 비선형 활성화 함수
def forward(self, x):
# 순전파 (입력 → 출력 방향)
x = self.relu(self.fc1(x)) # 1층 + ReLU
x = self.relu(self.fc2(x)) # 2층 + ReLU
x = self.relu(self.fc3(x)) # 3층 + ReLU
x = self.fc4(x) # 출력층 (회귀 문제이므로 활성화 함수 없음)
return x
# 모델 인스턴스 생성
model = AbaloneModel()
(8) 학습 설정
# 8. 학습 설정
epochs = 50 # 학습을 반복할 에폭 수
loss_fn = nn.MSELoss() # 회귀 문제용 손실 함수: 평균 제곱 오차
optimizer = optim.SGD(model.parameters(), # 옵티마이저: 확률적 경사하강법 (모멘텀 포함)
lr=0.01, momentum=0.9)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # GPU 사용 가능 여부 확인
model.to(device) # 모델을 디바이스(GPU/CPU)로 이동
step = 0 # 총 학습 배치 수 (스텝 수) 카운터
(9) 모델 학습
# === 학습 루프 ===
for epoch in range(epochs):
running_loss = 0.0
total_batches = len(train_dataloader) # 현재 에폭에 들어있는 배치 수 (보통 고정)
loop = tqdm(train_dataloader, desc=f"Epoch {epoch+1}", leave=False) # 진행 상황 표시용
for train_batch in loop:
# 배치 단위로 입력값/타겟값 불러오기 (GPU로 이동)
x_train, y_train = train_batch[0].to(device), train_batch[1].to(device)
y_train = y_train.view(-1, 1) # shape: (batch_size,) → (batch_size, 1)
pred = model(x_train) # 예측 수행 (순전파)
loss = loss_fn(pred, y_train) # 손실 계산
optimizer.zero_grad() # 이전 기울기 초기화
loss.backward() # 역전파: 손실 함수 기준으로 기울기 계산
optimizer.step() # 가중치 업데이트
running_loss += loss.item() # 손실 값 누적 (에폭 평균 손실 계산용)
loop.set_postfix(loss=loss.item()) # 현재 배치 손실 표시
step += 1 # 누적 스텝 수 증가 (전체 학습에서 몇 번째 배치인지 추적)
avg_train_loss = running_loss / total_batches # 에폭당 평균 학습 손실
# === 검증 단계 ===
model.eval() # 평가 모드 전환 (dropout, batchnorm 비활성화)
val_loss = 0.0
with torch.no_grad(): # 검증 시 기울기 계산 비활성 (메모리 절약, 속도 향상)
for val_batch in val_dataloader:
x_val, y_val = val_batch[0].to(device), val_batch[1].to(device)
y_val = y_val.view(-1, 1)
pred = model(x_val)
loss = loss_fn(pred, y_val)
val_loss += loss.item()
avg_val_loss = val_loss / len(val_dataloader) # 평균 검증 손실 계산
model.train() # 다시 학습 모드로 전환
# === 5 에폭마다 상태 출력 ===
if (epoch + 1) % 5 == 0:
print(f"▶ Epoch {epoch+1:>3} | Steps: {step:>5} | Train Loss: {avg_train_loss:.4f} | Val Loss: {avg_val_loss:.4f} ◀")
(10) 번외
# init 레이어 생성 전 배치&피처 확인!!!
x, y = next(iter(train_dataloader))
print(x.shape, y.shape)
torch.Size([32, 7]) torch.Size([32])
# 차원 확인
print(len(train_dataset), len(val_dataset), len(test_dataset))
print(next(iter(train_dataloader))) 하나 꺼내보기
for train_batch in train_dataloader:
print(train_batch[0].shape, train_batch[1])
break
for val_batch in val_dataloader:
print(val_batch[0].shape, val_batch[1])
break
for test_batch in test_dataloader:
print(test_batch[0].shape, test_batch[1])
break아 정말 재밌다

AI Engineer
오.. 재밌어지고 싶다고 한 게 며칠 전이었던 거 같은데 벌써 즐기고 계시네요 멋져요