오늘 포스팅도 코드로 대체... ㅠㅠ
학습시간 09:00~02:00(당일17H/누적377H)
◆ 학습내용
DNN 모델로 FashionMNIST 이미지 분류
1. 코드
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import random
# ✅ 1. 데이터 로드
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
]
)
train_dataset = datasets.FashionMNIST(
root='data/FashionMNIST',
train=True,
download=False,
transform=transform
)
test_dataset = datasets.FashionMNIST(
root='data/FashionMNIST',
train=False,
download=False,
transform=transform
)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64)
# ✅ 2. 모델 생성
class DNN(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28*28, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
model = DNN()
from torchinfo import summary
print(summary(model, input_size=(32, 1, 28, 28)))
# ✅ 3. 모델 학습(함수)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train_model(model, dataloader, loss_fn, optimizer, epochs=5):
model.to(device)
for epoch in range(epochs):
model.train()
total_loss = 0
correct = 0
total = 0
for x_batch, y_batch in dataloader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
preds = model(x_batch)
loss = loss_fn(preds, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = preds.max(1)
correct += (predicted == y_batch).sum().item()
total += y_batch.size(0)
acc = correct / total
avg_loss = total_loss / len(dataloader)
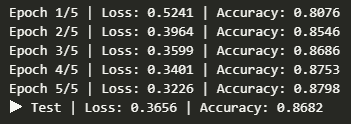
print(f"Epoch {epoch+1}/{epochs} | Loss: {avg_loss:.4f} | Accuracy: {acc:.4f}")
train_model(model, train_loader, loss_fn, optimizer, epochs=5)
# ✅ 4. 모델 평가(함수)
def test_model(model, dataloader, loss_fn):
model.eval()
correct = 0
total = 0
total_loss = 0
with torch.no_grad():
for x_batch, y_batch in dataloader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
preds = model(x_batch)
loss = loss_fn(preds, y_batch)
total_loss += loss.item()
_, predicted = preds.max(1)
correct += (predicted == y_batch).sum().item()
total += y_batch.size(0)
avg_loss = total_loss / len(dataloader)
acc = correct / total
print(f"▶ Test | Loss: {avg_loss:.4f} | Accuracy: {acc:.4f}")
test_model(model, test_loader, loss_fn)
# ✅ 5. 시각화(함수)
class_names = [
"T-shirt", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"
]
def show_random_predictions(model, dataset, n=12):
model.eval()
indices = random.sample(range(len(dataset)), n)
images = torch.stack([dataset[i][0] for i in indices]).to(device)
labels = torch.tensor([dataset[i][1] for i in indices]).to(device)
with torch.no_grad():
outputs = model(images)
_, preds = outputs.max(1)
plt.figure(figsize=(12, 12))
for i in range(n):
img = images[i].cpu().squeeze()
label = labels[i].item()
pred = preds[i].item()
plt.subplot(3, n//3, i+1)
plt.imshow(img, cmap='gray')
title = f"True: {class_names[label]}\nPred: {class_names[pred]}"
color = 'green' if label == pred else 'red'
plt.title(title, color=color, fontsize=15)
plt.axis('off')
plt.tight_layout()
plt.show()
show_random_predictions(model, test_dataset, n=12)
# ✅ 6. 모델 세이브
import os
os.mkdir('model')
torch.save(model.state_dict(), './model/housing_model_0411_1.pth')
os.listdir('./model')
# ✅ 7. 모델 로드
class HousingModel_new(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28*28, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
model_loaded = HousingModel()
model_loaded.load_state_dict(torch.load('./model/housing_model_0411_1.pth'))
model_loaded.to(device)
print(model.state_dict().keys() == model_loaded.state_dict().keys())
for key in model.state_dict():
print(key, torch.equal(model.state_dict()[key], model_loaded.state_dict()[key]))
 가끔 틀린다. 근데 저건 내가 봐도 모르겠는데...?
가끔 틀린다. 근데 저건 내가 봐도 모르겠는데...?
2. 코드 설명
(1). 데이터 로드
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor(), # 이미지를 [0,1] 범위의 Tensor로 변환
transforms.Normalize((0.5,), (0.5,)) # 평균 0.5, 표준편차 0.5로 정규화
])
train_dataset = datasets.FashionMNIST(
root='data/FashionMNIST',
train=True,
download=False,
transform=transform
)
test_dataset = datasets.FashionMNIST(
root='data/FashionMNIST',
train=False,
download=False,
transform=transform
)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64)
transforms.Compose(): 입력 이미지를 텐서로 변환하고, 정규화하여 학습 안정화 유도DataLoader:batch_size=64: 한 번에 64장 이미지 처리shuffle=True: 매 epoch마다 데이터를 섞어 학습 성능 향상
(2). 모델 구현
a, b = next(iter(train_loader)); print(a.shape, b.shape)
# 출력 예시: torch.Size([64, 1, 28, 28]) torch.Size([64])
# torch.Size.([배치 사이즈, 채널, 세로 픽셀, 가로 픽셀])
class DNN(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() # (28,28) → (784,) 벡터로 변환
self.fc1 = nn.Linear(28*28, 256) # 첫 번째 완전연결 계층
self.fc2 = nn.Linear(256, 128) # 두 번째 완전연결 계층
self.fc3 = nn.Linear(128, 10) # 출력층 (10개 클래스)
self.relu = nn.ReLU() # ReLU 활성화 함수
self.dropout = nn.Dropout(0.2) # 20% 드롭아웃 적용
def forward(self, x):
x = self.flatten(x) # 이미지 평탄화
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x) # 과적합 방지
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x) # 최종 클래스 출력
return x
model = DNN()
from torchinfo import summary
print(summary(model, input_size=(32, 1, 28, 28)))
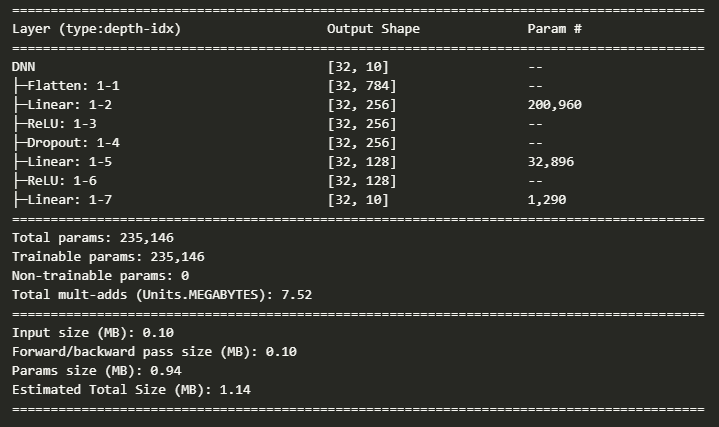
- DNN 구조:
784 → 256 → 128 → 10Fully Connected - ReLU 활성화: 비선형성 부여, gradient vanishing 방지
- Dropout(0.2): 학습 중 일부 뉴런 무작위 제거 → 일반화 향상
- 모델 선언만 했고, 아직
device로 올리진 않음 - summary로 모델 현황 한눈에 볼 수 있음
(3). 모델 학습
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
loss_fn = nn.CrossEntropyLoss() # 다중분류 손실 함수
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam 최적화 사용
def train_model(model, dataloader, loss_fn, optimizer, epochs=5):
model.to(device) # 모델을 GPU/CPU로 이동
for epoch in range(epochs):
model.train() # 학습 모드 설정
total_loss = 0
correct = 0
total = 0
for x_batch, y_batch in dataloader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
preds = model(x_batch) # 순전파
loss = loss_fn(preds, y_batch) # 손실 계산
optimizer.zero_grad()
loss.backward() # 역전파
optimizer.step() # 가중치 업데이트
total_loss += loss.item()
_, predicted = preds.max(1) # 예측 클래스 선택
correct += (predicted == y_batch).sum().item()
total += y_batch.size(0)
avg_loss = total_loss / len(dataloader)
acc = correct / total
print(f"Epoch {epoch+1}/{epochs} | Loss: {avg_loss:.4f} | Accuracy: {acc:.4f}")
train_model(model, train_loader, loss_fn, optimizer, epochs=5)
model.to(device): GPU 사용 가능 시 모델을 GPU로 이동- 학습 루프 구조:
zero_grad()→backward()→step()순서로 학습loss.item()은 scalar 값만 추출preds.max(1)은 확률이 가장 높은 클래스 선택
model.train()상태에서는 드롭아웃, 배치정규화 등이 활성화됨
(4). 모델 평가
def test_model(model, dataloader, loss_fn):
model.eval() # 평가 모드 (dropout 등 off)
correct = 0
total = 0
total_loss = 0
with torch.no_grad(): # gradient 계산 비활성화
for x_batch, y_batch in dataloader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
preds = model(x_batch)
loss = loss_fn(preds, y_batch)
total_loss += loss.item()
_, predicted = preds.max(1)
correct += (predicted == y_batch).sum().item()
total += y_batch.size(0)
avg_loss = total_loss / len(dataloader)
acc = correct / total
print(f"▶ Test | Loss: {avg_loss:.4f} | Accuracy: {acc:.4f}")
test_model(model, test_loader, loss_fn)
model.eval(): 평가 시 dropout 중단, 더 안정된 결과 출력torch.no_grad(): 메모리와 연산 최적화 (역전파 생략)- 학습과 거의 동일한 구조지만 optimizer 및 backward 없음
- 평가 성능은 이후 모델 선택, 저장 여부 판단 기준
(5). 시각화
class_names = [
"T-shirt", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"
]
def show_random_predictions(model, dataset, n=12):
model.eval()
indices = random.sample(range(len(dataset)), n) # 무작위 샘플 선택
images = torch.stack([dataset[i][0] for i in indices]).to(device)
labels = torch.tensor([dataset[i][1] for i in indices]).to(device)
with torch.no_grad():
outputs = model(images)
_, preds = outputs.max(1)
plt.figure(figsize=(12, 12))
for i in range(n):
img = images[i].cpu().squeeze()
label = labels[i].item()
pred = preds[i].item()
plt.subplot(3, n//3, i+1)
plt.imshow(img, cmap='gray')
title = f"True: {class_names[label]}\nPred: {class_names[pred]}"
color = 'green' if label == pred else 'red'
plt.title(title, color=color, fontsize=15)
plt.axis('off')
plt.tight_layout()
plt.show()
show_random_predictions(model, test_dataset, n=12)
- 학습된 모델의 랜덤 예측 결과를 시각적으로 확인
- 예측이 맞았을 때 초록색, 틀렸을 때 빨간색으로 표시
random.sample()로 중복 없는 n개 샘플 선택model.eval()및torch.no_grad()는 항상 함께 사용!
(6). 모델 세이브
import os
# [1] 모델 저장용 폴더 생성 (이미 존재하면 에러 발생함)
os.mkdir('model')
# [2] 학습 완료된 모델의 가중치(state_dict)를 저장 (구조는 저장하지 않음)
torch.save(model.state_dict(), './model/housing_model_0411_1.pth')
# [3] 저장된 파일 목록 확인 (제대로 저장됐는지 시각적으로 확인용)
os.listdir('./model')
(7). 모델 로드
# [1] 빈 껍데기 모델 생성(Key가 완전 동일해야 함, 아래 예시)
class HousingModel_new(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28*28, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
# [2] 새로운 동일 구조의 모델 인스턴스 생성 (학습 전 모델)
model_loaded = HousingModel()
# [3] 저장된 가중치를 로드하여 모델에 적용
model_loaded.load_state_dict(torch.load('./model/housing_model_0411_1.pth'))
# [4] 불러온 모델도 GPU/CPU로 이동 (원래 모델과 같은 device로 맞춰줌)
model_loaded.to(device)
# [5] 원본 모델과 불러온 모델의 레이어 키(구조)가 같은지 확인 (True면 구조 동일)
print(model.state_dict().keys() == model_loaded.state_dict().keys())
# [6] 각 레이어의 파라미터 값이 정확히 같은지 개별 비교
for key in model.state_dict():
print(key, torch.equal(model.state_dict()[key], model_loaded.state_dict()[key]))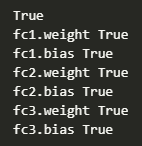
^^...

AI Engineer