오토인코더 배우긴 했는데 이걸 어디다 써먹어야할지 잘 모르겠다...
학습시간 09:00~02:00(당일17H/누적411H)
◆ 학습내용
1. AutoEncoder
| 항목 | 내용 |
|---|---|
| 정의 | 입력을 압축한 뒤 복원하는 딥러닝 모델 |
| 구조 | Encoder → Latent Space → Decoder |
| 학습 방식 | 입력 = 출력, 비지도 학습 방식 |
| 목적 | 의미 있는 특징 표현 학습 |
| 손실 평가 | 입력과 출력의 유사도 측정 |
| 주요 용도 | 차원 축소, 이상 탐지, 노이즈 제거, 생성 모델 |
| 확장 예시 | Variational AutoEncoder, Denoising AutoEncoder 등 |
(1) AutoEncoder란?
- 입력 데이터를 압축하여 중요한 특징만 추출한 뒤, 이를 복원하는 딥러닝 기반의 비지도 학습 모델
- 입력과 출력이 동일한 구조를 가지며, 압축된 표현(잠재 벡터)은 데이터의 의미 있는 저차원 표현 역할을 함
- 주된 활용 분야: 차원 축소, 특징 학습, 이상 탐지, 이미지 노이즈 제거, 데이터 생성 등
(2) 표현 학습
- 표현 학습(Representation Learning)이란 데이터의 특징을 스스로 학습하는 것
- 고차원 데이터(예: 이미지)의 각 픽셀은 의미가 명확하지 않기 때문에 모델이 스스로 중요한 특징을 추출해야 함
- 사람은 "안경", "웃는 얼굴"처럼 추상적인 특징을 통해 대상을 인식함. 오토인코더는 이처럼 의미 있는 표현을 벡터 형태로 자동 학습함
(3) 잠재공간
- 원본 데이터는 고차원 공간에 존재하지만, 이를 더 간단한 저차원 공간으로 바꾸는 것이 핵심
- 이 공간은 잠재공간(latent space)이라 부르며, 데이터의 본질적인 속성만을 담고 있음
- 잠재공간에서의 수치 조작은 의미적 변화로 이어짐
- 예: 원통 이미지의 '높이'를 바꾸고 싶을 때 픽셀을 수정하는 대신, 잠재공간에서 관련 벡터값을 조정
(4) 구조
- Encoder: 입력 데이터를 압축하여 핵심 정보만 남김
- Decoder: 압축된 정보를 바탕으로 원래의 데이터를 복원함
- 구조는 대칭적으로 설계되는 경우가 많음
입력 → [Encoder] → 잠재 벡터 → [Decoder] → 출력
| 구성 요소 | 설명 |
|---|---|
| Input Layer | 원본 데이터 (예: 이미지, 텍스트 등) |
| Encoder | 데이터를 압축 (MLP, CNN, RNN 등 사용 가능) |
| Latent Space | 데이터의 요약 정보 표현 공간 |
| Decoder | 원본 데이터와 유사하게 재구성 |
| Output Layer | 입력과 동일한 형태의 출력 생성 |
(5) 학습 방식
- 입력과 출력 간의 차이를 최소화하는 방식으로 학습함
- 라벨을 사용하지 않기 때문에 비지도 학습에 속함
- 입력 데이터를 인코더에 전달하여 잠재 벡터 생성
- 디코더를 통해 잠재 벡터로부터 출력 생성
- 입력과 출력의 차이를 줄이도록 모델의 파라미터를 최적화
(6) 특징
- 라벨 없이도 의미 있는 표현 학습 가능
- 노이즈 제거, 이상 탐지, 데이터 압축 등 실용성이 뛰어남
- 하지만 구조가 단순해 복잡한 데이터 표현에 한계가 있음
- 보다 정교한 표현 학습을 위해 Variational AutoEncoder(VAE) 등의 확장이 필요함
(7) 활용 분야
| 활용 분야 | 설명 |
|---|---|
| 차원 축소 | PCA처럼 고차원 데이터를 저차원으로 압축 |
| 이상 탐지 | 재구성 오차가 큰 데이터를 이상치로 판별 |
| 노이즈 제거 | 잡음이 포함된 입력에서 깨끗한 이미지를 복원 |
| 데이터 생성 | 잠재 공간을 조작해 새로운 데이터 생성 가능 |
| Feature Learning | 다른 작업에 사용할 특징 벡터 추출 가능 |
2. 코드 예시
MNIST 손글씨 재구현(?)
(1) 데이터 로드
# ✅ 1. 데이터 로드
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import v2
transforms = v2.Compose([
v2.ToTensor(),
v2.ToDtype(torch.float32, scale=True),
])
train_dataset = datasets.MNIST(
root='./data/MNIST',
train=True,
download=False,
transform=transforms
)
test_dataset = datasets.MNIST(
root='./data/MNIST',
train=False,
download=False,
transform=transforms
)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=False)
print(f'▶ Train set: {len(train_dataset)} | Test set: {len(test_dataset)}')
print(next(iter(train_dataloader))[0].shape)
 트레인셋 6만 개, 테스트셋 1만 개. 1채널, 28x28 픽셀. 배치는 64로 했다.
트레인셋 6만 개, 테스트셋 1만 개. 1채널, 28x28 픽셀. 배치는 64로 했다.
(2) 데이터 시각화
# ✅ 2. 데이터 시각화
import matplotlib.pyplot as plt
import random
indices = random.sample(range(len(train_dataset)), 15)
images = [train_dataset[i][0] for i in indices]
labels = [train_dataset[i][1] for i in indices]
plt.figure(figsize=(10, 6))
for i in range(15):
plt.subplot(3, 5, i + 1)
plt.imshow(images[i].squeeze(), cmap='gray')
plt.title(f'Label: {labels[i]}', fontsize=10)
plt.axis('off')
plt.tight_layout()
plt.show()
 데이터에 담긴 이미지 모습. 누가 9를 저렇게 쓰냐...??
데이터에 담긴 이미지 모습. 누가 9를 저렇게 쓰냐...??
(3) 모델 생성
# ✅ 3. 모델 생성
import torch
import torch.nn as nn
import torch.nn.functional as F
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.ec_fc1 = nn.Linear(28*28, 128)
self.ec_fc2 = nn.Linear(128, 64)
self.ec_fc3 = nn.Linear(64, 32)
self.ec_fc4 = nn.Linear(32, 16)
self.dc_fc1 = nn.Linear(16, 32)
self.dc_fc2 = nn.Linear(32, 64)
self.dc_fc3 = nn.Linear(64, 128)
self.dc_fc4 = nn.Linear(128, 28*28)
def forward(self, x):
x = x.view(x.size(0), -1)
x = F.leaky_relu(self.ec_fc1(x))
x = F.leaky_relu(self.ec_fc2(x))
x = F.leaky_relu(self.ec_fc3(x))
x = F.leaky_relu(self.ec_fc4(x))
x = F.leaky_relu(self.dc_fc1(x))
x = F.leaky_relu(self.dc_fc2(x))
x = F.leaky_relu(self.dc_fc3(x))
x = torch.sigmoid(self.dc_fc4(x))
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AutoEncoder().to(device)
summary(model, input_size=(64, 1, 28, 28))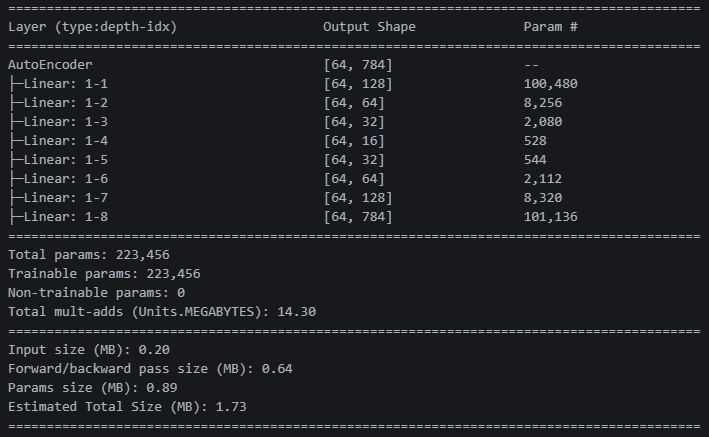 성능이 궁금해서 활성화함수에 리키렐루를 넣어봤다. 출력은 시그모이드로 뽑았다. 웨이트 약 10만 개!
성능이 궁금해서 활성화함수에 리키렐루를 넣어봤다. 출력은 시그모이드로 뽑았다. 웨이트 약 10만 개!
(4) 모델 학습
# ✅ 4. 모델 학습
import torch.optim as optim
from tqdm import tqdm # 진행 바 출력
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=5e-3)
epochs = 5
for epoch in range(epochs):
model.train()
total_loss = 0.0
for images, _ in tqdm(train_dataloader):
images = images.to(device)
outputs = model(images)
loss = criterion(outputs, images.view(images.size(0), -1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'[Epoch {epoch+1}/{epochs}] Loss: {total_loss / len(train_dataloader):.4f}')
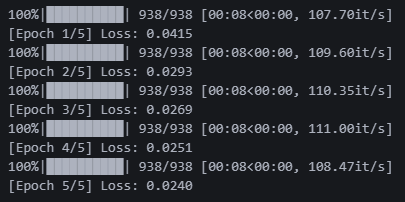 tqdm 라이브러리 넣으니까 진행 현황이 보인다. 한국인 필수템인듯. 에폭 5회만 돌렸는데도 로스가 괜찮게 나온다.
tqdm 라이브러리 넣으니까 진행 현황이 보인다. 한국인 필수템인듯. 에폭 5회만 돌렸는데도 로스가 괜찮게 나온다.
(5) 시각화
# ✅ 5. 시각화
import matplotlib.pyplot as plt
import random
model.eval()
n = 7
indices = random.sample(range(len(test_dataset)), n)
samples = torch.stack([test_dataset[i][0] for i in indices]).to(device)
with torch.no_grad():
outputs = model(samples)
outputs = outputs.view(-1, 1, 28, 28).cpu()
plt.figure(figsize=(14, 4))
for i in range(n):
plt.subplot(2, n, i + 1)
plt.imshow(samples[i].cpu().squeeze(), cmap='gray')
plt.title(f"Input {i+1}", fontsize=9)
plt.axis('off')
plt.subplot(2, n, i + 1 + n)
plt.imshow(outputs[i].squeeze(), cmap='gray')
plt.title(f"Recon {i+1}", fontsize=9)
plt.axis('off')
plt.tight_layout()
plt.show()
 성능이 나쁘진 않은 것 같다. 마지막 인풋 이미지 뭐지...? 7을 저렇게 쓴다고?
성능이 나쁘진 않은 것 같다. 마지막 인풋 이미지 뭐지...? 7을 저렇게 쓴다고?
NLP도 해야하는데 진짜 무슨 소린지 이해가 1도 안 된다.

AI Engineer