딥러닝 기본 모델을 몇 개 해보니까 이제 흐름이 보인다. 데이터 스플릿, 모델 생성, 학습, 평가는 코드가 다 거기서 거기다. 파일 유형에 따라 전처리와 시각화 방법만 달라지는 것 같다.
학습시간 09:00~02:00(당일17H/누적394H)
◆ 학습내용
1. CNN 모델 구현
꽃 사진 분류 모델
(1) 이미지 로드 + 증강 + 시각화
# ✅ 1. 이미지 로드 + 증강
transforms_train = v2.Compose([
v2.ToImage(),
v2.RandomHorizontalFlip(),
v2.RandomResizedCrop(size=(180, 180)),
v2.RandomRotation(degrees=15),
v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
transforms_test = v2.Compose([
v2.ToImage(),
v2.Resize((180, 180)),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
dataset = datasets.ImageFolder(
root='data/flower_photos',
transform=transforms_train
)
# ✅ 2. 증강 시각화(함수 생성)
def visualize_augmented_grid(folder_path, transform, n_rows, n_cols):
total = n_rows * n_cols
# 이미지 경로
all_image_paths = []
for root, _, files in os.walk(folder_path):
for file in files:
if file.lower().endswith(('jpg', 'jpeg', 'png')):
all_image_paths.append(os.path.join(root, file))
# 에러 방지
if len(all_image_paths) < total:
raise ValueError(f"Not enough images in folder. Found {len(all_image_paths)}.")
# 랜덤 선택
selected_paths = random.sample(all_image_paths, total)
# 시각화
fig, axes = plt.subplots(n_rows, n_cols, figsize=(n_cols * 2.5, n_rows * 2.5))
for i, img_path in enumerate(selected_paths):
image_pil = Image.open(img_path).convert('RGB')
aug_img = transform(image_pil)
if isinstance(aug_img, torch.Tensor):
img_np = aug_img.permute(1, 2, 0).numpy()
else:
img_np = np.array(aug_img)
img_np = img_np.clip(0, 1) if img_np.max() <= 1 else img_np.astype('uint8')
row, col = i // n_cols, i % n_cols
ax = axes[row][col]
ax.imshow(img_np)
ax.axis('off')
plt.tight_layout()
plt.show()
visualize_augmented_grid('data/flower_photos', transforms_train, n_rows=5, n_cols=5) 증강이 잘 됐다. 정규화 후 시각화 하면 칙칙해진다고 한다.
증강이 잘 됐다. 정규화 후 시각화 하면 칙칙해진다고 한다.
(2) 모델 생성 및 학습
# ✅ 4. 모델 생성
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class FlowerCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 45 * 45, 128)
self.fc2 = nn.Linear(128, 5)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
return self.fc2(x)
model = FlowerCNN().to(device)
model.load_state_dict(torch.load('./model/flowerCNN_0414_1.pth', map_location=device))
# ✅ 5. 모델 학습
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 5
for epoch in range(epochs):
model.train()
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
preds = outputs.argmax(1)
correct += (preds == labels).sum().item()
total += labels.size(0)
acc = correct / total
print(f"Epoch {epoch+1}/{epochs}, Val Accuracy: {acc:.4f}")
torch.save(model.state_dict(), './model/flowerCNN_0414_1.pth')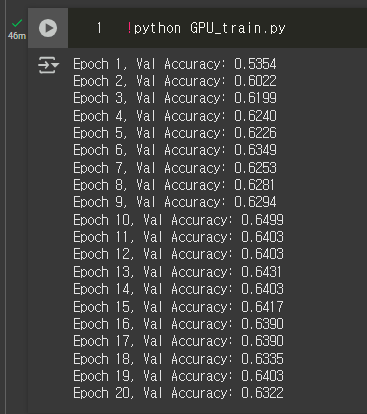 GPU 때문에 학습만 코랩에서 돌렸는데 46분이나 걸렸다 ㅠㅠ 중간에 코드가 뭔가 잘못됐나..?
GPU 때문에 학습만 코랩에서 돌렸는데 46분이나 걸렸다 ㅠㅠ 중간에 코드가 뭔가 잘못됐나..?
(3) 모델 평가
# ✅ 6. 모델 평가
def get_validation_loss(model, dataloader, loss_fn):
model.eval()
total_loss = 0.0
count = 0
with torch.no_grad():
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = loss_fn(outputs, labels)
total_loss += loss.item() * images.size(0)
count += images.size(0)
avg_loss = total_loss / count
print(f"Validation Loss: {avg_loss:.4f}")
return avg_loss
get_validation_loss(model, val_loader, criterion)
# ✅ 7. 모델 성능 시각화
class_names = dataset.classes
def visualize_model_predictions(model, dataloader, n_images):
model.eval()
images_shown = 0
plt.figure(figsize=(12, 9))
with torch.no_grad():
for images, labels in dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
preds = outputs.argmax(1)
for i in range(images.size(0)):
if images_shown >= n_images:
break
img = images[i].cpu().permute(1, 2, 0).numpy()
img = (img * 0.5 + 0.5).clip(0, 1) # 역정규화
plt.subplot(3, 5, images_shown + 1)
plt.imshow(img)
plt.title(f"Predict: {class_names[preds[i]]}\nActual: {class_names[labels[i]]}",
color='green' if preds[i] == labels[i] else 'red')
plt.axis('off')
images_shown += 1
if images_shown >= n_images:
break
plt.tight_layout()
plt.show()
visualize_model_predictions(model, val_loader, n_images=15) 만족스러운 로스는 아닌데 그래도 잘 맞추는듯.. 신기하다!
만족스러운 로스는 아닌데 그래도 잘 맞추는듯.. 신기하다!
2. RNN 이론
(1) 정의
- Recurrent Neural Network(순환 신경망)은 이전 단계의 출력을 다음 단계의 입력으로 전달해 시간 의존성을 모델링할 수 있도록 설계된 신경망
- 순서가 중요한 데이터(예: 문장, 음성, 영상 프레임 등)를 처리하는 구조로, 시간의 흐름에 따라 정보를 기억하고 반영하는 특징을 가짐
- RNN의 응용 분야
| 분야 | 예시 |
|---|---|
| 자연어 처리 | 번역, 감정 분석, 챗봇 |
| 시계열 예측 | 주식 가격, 날씨 예보 |
| 생성 모델 | 음악, 텍스트 생성 |
| 음성 인식 | 음성 → 텍스트 변환 |
(2) 순차 데이터와 자연어
A. 순차 데이터(Sequential Data)의 정의
- 시간 순서 또는 순서 의존성이 중요한 데이터
- 이전 시점의 데이터가 현재 시점에 영향을 미침
- 예: 주가, 날씨, 심박수, 자연어 문장 등
B. 자연어의 특성
- 단어 순서에 따라 의미가 완전히 달라짐
- 예: "나는 너를 사랑해" vs "사랑해 나는 너를"
- 기존 CNN, MLP는 순서를 고려하지 못해 한계 존재
(3) 학습 방법
A. BPTT (Backpropagation Through Time) 개념
- 일반적인 역전파와 달리 시간 축을 따라 펼쳐서 역전파
- 각 시점의 손실을 모두 더한 후 전체 가중치 업데이트
- 시간적으로 멀어진 과거의 기여도가 점점 약해짐
B. 문제점
- 기울기 소실(Vanishing Gradient): 과거 정보가 사라짐
- 기울기 폭발(Exploding Gradient): 수치가 커져서 학습 불안정
- 긴 문장이나 장기 의존성 문제 해결이 어려움
(4) 모델 종류
- RNN은 장기 의존성 문제 (Long-Term Dependency)가 있음
- 시간이 오래 지날수록 과거 정보가 사라지거나 왜곡
- 원인은 기울기 소실/폭발(vanishing/exploding gradient) 때문
- 이 문제를 해결하기 위해 장기 기억을 다룰 수 있는 구조가 등장
| 항목 | RNN | LSTM | GRU |
|---|---|---|---|
| 기본 구조 | 단순 순환 | 셀 상태 + 3개 게이트 | 2개 게이트로 간결화 |
| 기억 장치 | Hidden state 하나만 유지 | Cell state, Hidden state 분리 | Hidden state 하나로 통합 |
| 게이트 이름 | 없음 | 입력, 망각, 출력 | 업데이트, 리셋 |
| 장점 | 구조 단순, 계산 빠름 | 장기 의존성 해결, 정확도 ↑ | LSTM보다 계산 효율 ↑, 성능 유사 |
| 단점 | 기울기 소실, 장기 정보 손실 | 복잡, 연산량 많음 | 이론적으로 해석 어려움 |
| 사용 적합 | 짧은 시퀀스 | 복잡한 시퀀스, 번역, 언어모델 | 실시간 예측, 모바일 모델 |
| 연산 속도 | ★★★★★ | ★★☆☆☆ | ★★★★☆ |
| 기억 지속력 | ★★☆☆☆ | ★★★★★ | ★★★★☆ |
| 대표적 사용처 | 간단한 시계열, 신호 분석 | 기계번역, 언어생성 | 음성인식, 챗봇, 실시간 예측 |
(5) LSTM
- LSTM (Long Short-Term Memory)
- 장기 기억(Cell State)과 단기 기억(Hidden State) 분리
- 정보를 선택적으로 저장하거나 잊게 만드는 게이트 구조 도입
- 더 깊은 문맥 기억 가능
- 3개 게이트 + Cell state
- Forget Gate:
- 어떤 과거 정보를 잊을지 결정
fₜ = σ(Wf · [hₜ₋₁, xₜ])
- Input Gate:
- 현재 정보를 얼마나 저장할지 결정
iₜ = σ(Wi · [hₜ₋₁, xₜ]),ĉₜ = tanh(Wc · [hₜ₋₁, xₜ])
- Cell State 업데이트:
Cₜ = fₜ * Cₜ₋₁ + iₜ * ĉₜ
- Output Gate:
- 출력 hidden state 결정
oₜ = σ(Wo · [hₜ₋₁, xₜ]),hₜ = oₜ * tanh(Cₜ)
(6) GRU
- GRU (Gated Recurrent Unit)
- LSTM보다 구조 단순
- Cell state 없이 hidden state만 사용
- 학습 속도 빠르고 파라미터 수 적음
- 2개 게이트로 구성
- Reset Gate:
- 과거 정보를 얼마나 초기화할지 결정
rₜ = σ(Wr · [hₜ₋₁, xₜ])
- Update Gate:
- 과거와 현재 정보를 어떻게 조합할지 결정
zₜ = σ(Wz · [hₜ₋₁, xₜ])
- New Hidden State:
- 후보값:
h̃ₜ = tanh(W · [rₜ * hₜ₋₁, xₜ]) - 최종값:
hₜ = (1 - zₜ) * hₜ₋₁ + zₜ * h̃ₜ
- 후보값:
(7) RNN의 주요 변형 및 응용 구조
A. 단방향 RNN
- 입력 순서대로 한 방향으로만 흐름
- 미래 정보 사용 불가
B. 양방향 RNN
- 입력을 순방향과 역방향 모두 처리
- 전체 문맥을 더 깊이 이해할 수 있음
C. 다층 RNN (Deep RNN)
- RNN 셀을 여러 층 쌓아 복잡한 표현 가능
- 추상화된 문맥 학습 가능하지만 학습 어려움
D. Sequence-to-One
- 전체 시퀀스를 보고 하나의 출력 예측
- 예: 문장 → 감정 분석
E. One-to-One
- 하나의 입력 → 하나의 출력
- 예: 이미지 분류 (단일 입력 → 단일 라벨)
F. Sequence-to-Sequence
- 입력 시퀀스 → 출력 시퀀스
- 예: 번역 (한국어 문장 → 영어 문장)
- 인코더-디코더 구조 사용
G. One-to-Sequence
- 하나의 입력에서 여러 개의 출력 생성
- 예: 이미지 캡셔닝
(8) 입력과 출력의 구조 분류
| 구조 유형 | 입력 | 출력 | 예시 |
|---|---|---|---|
| One-to-One | 하나 | 하나 | 이미지 분류 |
| One-to-Many | 하나 | 시퀀스 | 이미지 캡셔닝 |
| Many-to-One | 시퀀스 | 하나 | 감정 분석 |
| Many-to-Many (동일 길이) | 시퀀스 | 시퀀스 | 품사 태깅 |
| Many-to-Many (다른 길이) | 시퀀스 | 시퀀스 | 기계 번역 |
3. RNN 모델 구현
기온 예측 모델
(1) 데이터 로드 + 시각화
# ✅ 1. 데이터 로드 + 시각화
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
df = pd.read_csv('data/codeit/jena_climate_2009_2016.csv')
temperature = df['T (degC)']
temperature.index = df['Date Time']
temperature.head()
plt.figure(figsize=(10, 5))
temperature.plot()
plt.xticks(rotation=20)
plt.xlabel('Date Time')
plt.ylabel('Temperature (degC)')
plt.title('Temperature over Time')
plt.show()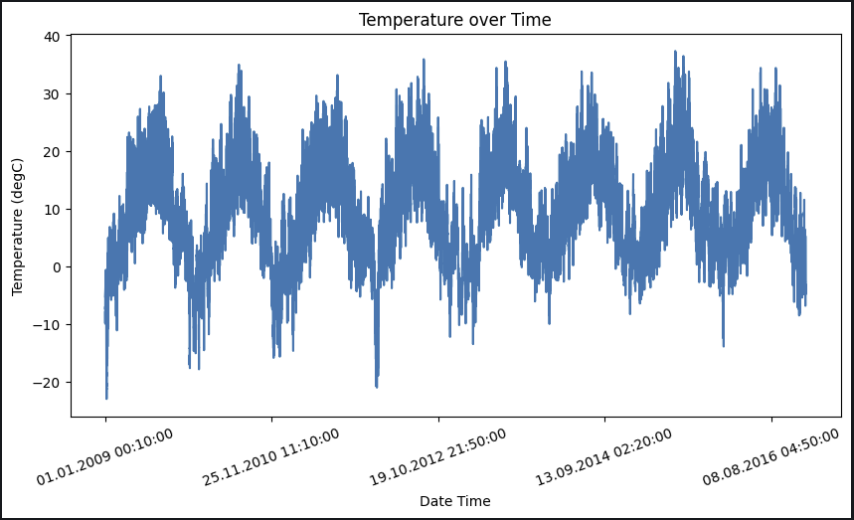 7년 간의 기온 데이터. csv 파일을 열어보니 행이 무려 42만 개다.
7년 간의 기온 데이터. csv 파일을 열어보니 행이 무려 42만 개다.
(2) 데이터 생성 + 스플릿
# ✅ 2. Dataset 생성
class TemperatureDataset(Dataset):
def __init__(self, series, seq_length):
self.x = []
self.y = []
for i in range(len(series) - seq_length):
self.x.append(series[i:i+seq_length])
self.y.append(series[i+seq_length])
self.x = torch.tensor(self.x).unsqueeze(-1)
self.y = torch.tensor(self.y)
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
temp = df['T (degC)'].values.astype('float32')
dataset = TemperatureDataset(temp, 30)
# ✅ 3. 데이터 스플릿
train_size = int(dataset.__len__() * 0.8)
train_dataset, test_dataset = random_split(dataset, [train_size, dataset.__len__() - train_size])
train_dataset.__len__(), test_dataset.__len__()
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=128)
train_dataloader.__len__(), test_dataloader.__len__()
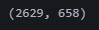
(3) 모델 생성 및 학습
# ✅ 4. 모델 생성
# dataset.__getitem__(0)[0].shape 로 input_size 확인
class RNN(nn.Module):
def __init__(self, input_size=1, hidden_size=32, num_layers=1):
super().__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.rnn(x)
return self.fc(out[:, -1, :])
# ✅ 5. 모델 학습
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = RNN().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 3
for epoch in range(num_epochs):
total_loss = 0
for x_batch, y_batch in train_dataloader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device).unsqueeze(1)
output = model(x_batch)
loss = criterion(output, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_dataloader)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')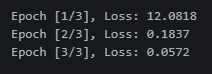 에폭 3번만 돌렸는데 로스가 0.05!!
에폭 3번만 돌렸는데 로스가 0.05!!
(4) 모델 검증
# ✅ 6. 모델 검증
preds = []
trues = []
with torch.no_grad():
model.eval()
for x_batch, y_batch in test_dataloader:
x_batch = x_batch.to(device)
output = model(x_batch)
preds.append(output.cpu().numpy())
trues.append(y_batch.unsqueeze(1).cpu().numpy())
preds = np.concatenate(preds, axis=0)
trues = np.concatenate(trues, axis=0)
plt.figure(figsize=(10, 5))
plt.plot(trues[:100], label='Actual')
plt.plot(preds[:100], label='Predict')
plt.xlabel('Time Step')
plt.ylabel('Temperature')
plt.legend()
plt.show()
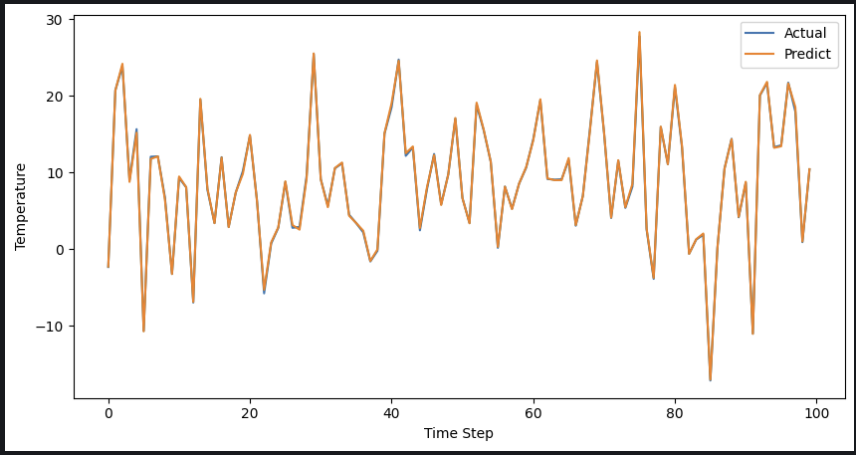 이게 맞나..? 내 눈에는 심하게 과적합인 것 같다.. 일단 오늘은 여기까지 ㅠㅠ
이게 맞나..? 내 눈에는 심하게 과적합인 것 같다.. 일단 오늘은 여기까지 ㅠㅠ

AI Engineer